Batch Inference Pipeline
What is a batch inference pipeline?
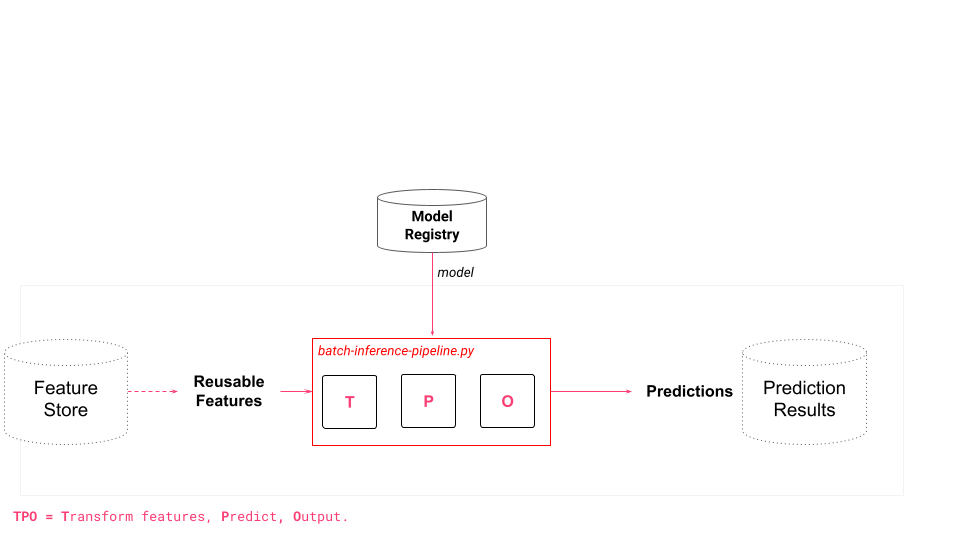
A batch inference pipeline is a program that takes as input a batch of data and a model, and outputs predictions that are typically written to some sink, such as a database.
Why are batch inference pipelines important?
Batch inference pipelines are important because they allow for efficient and scalable inference on large volumes of data using a trained model. Batch inference pipelines are typically run on a schedule (e.g., daily or hourly) and are used to drive dashboards and operational ML systems (that use the predictions for intelligent services).
Example of a batch inference application
A Spark program reads all of the new inference data that has arrived in the previous 24 hours as a DataFrame. The Spark program downloads the model from the model registry, broadcasts it to all executors, and then a map function calls predict on the model for each row in the DataFrame, returning the predictions as a DataFrame. The predictions DataFrame is then stored in a database from where it is consumed by a Dashboard or operational ML system.