



Download Now
O'Reilly's Book "Building ML Systems" First Chapter Available!

Machine Learning Observability (ML Observability) involves closely monitoring and understanding how machine learning models perform once they're deployed into real-world environments. At its core, it's a systematic approach to monitoring, analyzing, and comprehending the behavior and performance of ML systems once they're deployed into production environments. It serves as a window into the system's inner workings, allowing us to track how well the models are doing their job, how the data they receive is changing, and whether they're using resources efficiently.
When developing ML models, developers typically train them on historical data to learn patterns and make predictions or decisions on new data. However, the real challenge arises when these models are deployed into production systems. Unlike traditional software, where the behavior is deterministic and predictable, ML models often interact with dynamic and evolving data sources. This dynamic nature introduces uncertainties and complexities that require continuous monitoring and analysis.
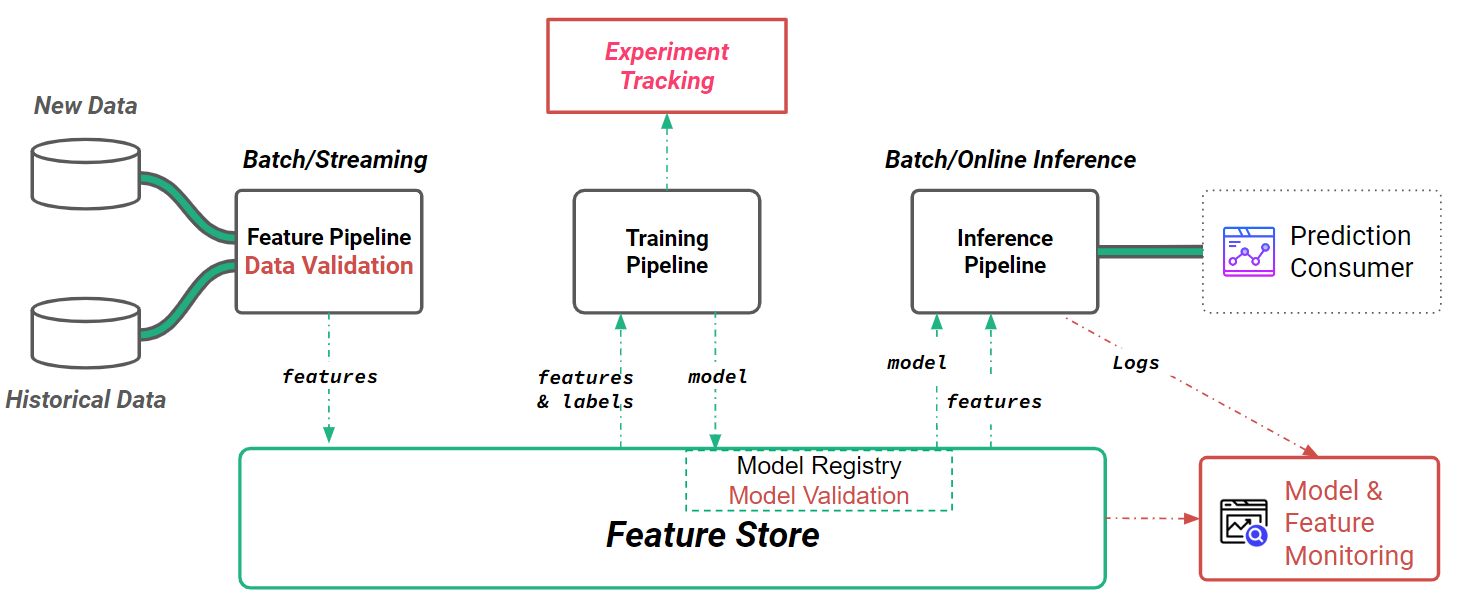
ML Observability encompasses several key components. Firstly, it involves monitoring the performance of the models themselves. Developers can track various metrics such as model accuracy, prediction latency, and resource utilization. These metrics provide insights into how well the models are performing and whether they meet the desired objectives. Secondly, ML Observability extends beyond just the models to include the entire ML pipeline and infrastructure. Developers also need to monitor data pipelines, ensuring that the input data remains consistent and representative of the training data.
Furthermore, ML Observability involves logging and tracing model predictions and system events. This allows developers to debug issues, audit model behavior, and ensure compliance with regulatory requirements. By capturing logs and traces of model predictions, developers can trace back any unexpected behavior to its root cause and take corrective actions.
Visualization and analysis are crucial aspects of ML Observability. The ability of visualizing the monitored data to gain insights into model behavior, performance trends, and areas for improvement is helpful. This visual representation helps understand complex relationships and make informed decisions about optimizing and scaling the ML system.
ML Observability is essential for ML production due to the probabilistic nature of ML models. ML models interact with real world data that can be changing and shifting, leading to unpredictable scenarios. Data might change, models might degrade, or resources might run out. Without ML Observability, we're flying blind, risking poor performance, crashes, and failures.
One of the primary reasons why observability is needed is to detect and diagnose issues affecting the performance of ML systems. In production environments, models may encounter various challenges, such as data drift, data anomaly, or changes in the underlying data distribution.
ML models are trained on historical data assuming that future data will follow a similar distribution. However, in real-world scenarios, this assumption often doesn't hold true. As the data generating process evolves, the incoming data can shift gradually or abruptly, leading to data drift. Data drift poses a significant challenge for ML systems because models may become less effective or accurate over time if they're not adapted to the changing data distribution. For example, an ML model trained to classify customer preferences based on historical data may struggle to make accurate predictions if there's a sudden change in consumer behavior or preferences. Detecting and mitigating data drift requires continuous monitoring of incoming data and model performance. By comparing the statistical properties of new data to the training data, developers can identify instances of data drift and take corrective actions, such as retraining the model on the updated data or implementing adaptive learning techniques that can adjust to new data.
Changes in data distribution can occur not only due to drift over time but also as a result of intentional or unintentional modifications to the data sources or data collection processes after ML models are deployed into production. For example, in an e-commerce application, changes to the user interface or website layout may affect the way users interact with the platform, leading to changes in the distribution of user behavior data. Similarly, updates to data collection mechanisms or changes in data preprocessing pipelines can alter the characteristics of the incoming data, impacting the performance of deployed models. Such changes can have a significant impact on the effectiveness and reliability of ML systems. Models trained on outdated or biased data may produce inaccurate or unreliable predictions when deployed in environments with different data distributions. Therefore, it's essential to monitor for changes in data distribution and update models accordingly to ensure their continued effectiveness and reliability in production settings.
Data related issues can degrade the performance of the models, leading to inaccurate predictions or decisions. By monitoring key metrics such as model accuracy, data consistency and quality, and performance degradation, models can be ensured to remain stable and reliable over time, and issues can be identified and diagnosed early on, minimizing their impact on the system.
Another reason why ML Observability is essential is to optimize resource utilization. ML model inference and updating (online retrain or online learning) often require significant computational resources, such as CPU, memory, and GPU. Inefficient resource allocation can lead to increased costs and decreased system performance. By monitoring the real-time utilization of computational resources, developers can identify bottlenecks and optimize resource allocation to ensure efficient resource utilization.
ML Observability also plays a crucial role in debugging and troubleshooting ML systems. In complex production environments, identifying the root cause of issues can be challenging. By capturing logs and traces of model predictions and system events, developers can trace back any unexpected behavior to its root cause and take corrective actions to resolve the issue.
In ML context, the adage "garbage in, garbage out" holds particular significance. Even the most sophisticated models can't perform well if fed with flawed or inconsistent data. ML Observability encompasses observability of the quality of data that arrives at feature pipelines.
ML systems often operate in environments where they have limited control over the data they ingest. Data may arrive from various sources, each with its own quirks, biases, and anomalies. These data imperfections can harm ML model performance if left unchecked. Therefore, it's important to incorporate robust data validation mechanisms into the feature engineering process - you need to ensure that you have visibility that new data arriving in the system passes your data validation tests.
ML Observability on data validation consists of monitoring the quality and characteristics of incoming data to identify issues that could affect model performance. Data quality issues can range from missing values and outliers to distribution shifts and data drift. The goal of data validation is to ensure data integrity throughout the feature engineering pipeline. This involves implementing checks and safeguards to detect and rectify data anomalies before they propagate downstream and adversely impact model training and inference. By establishing ML Observability on data validation, developers can monitor the metrics and mitigate the risk of model degradation due to poor-quality data.
Several techniques can be employed for data validation in feature pipelines, including:
For example, Hopsworks includes support for Great Expectations and visualizes the result of data validation runs in the platform, see below. In the event that data validation tests fail, an alert can be sent to a slack channel, email, or PagerDuty.

‘
Furthermore, ML Observability is needed to comply with regulatory requirements and industry standards. Many industries, such as finance and healthcare, have strict regulations governing the use of ML models. By logging and tracing model predictions, compliance can be ensured to fulfill regulatory requirements and demonstrate the fairness, transparency, and accountability of the ML models.
Having observability means we can catch problems early on. We can spot if an ML model isn't performing as expected, or if the data it's seeing is different from what it was trained on. This way, issues can be fixed before they become severe problems.
© Hopsworks 2024. All rights reserved. Various trademarks held by their respective owners.