Data Validation for Enterprise AI: Using Great Expectations with Hopsworks
Learn more about how Hopsworks stores both data and validation artifacts, enabling easy monitoring on the Feature Group UI page.

Problem Statement
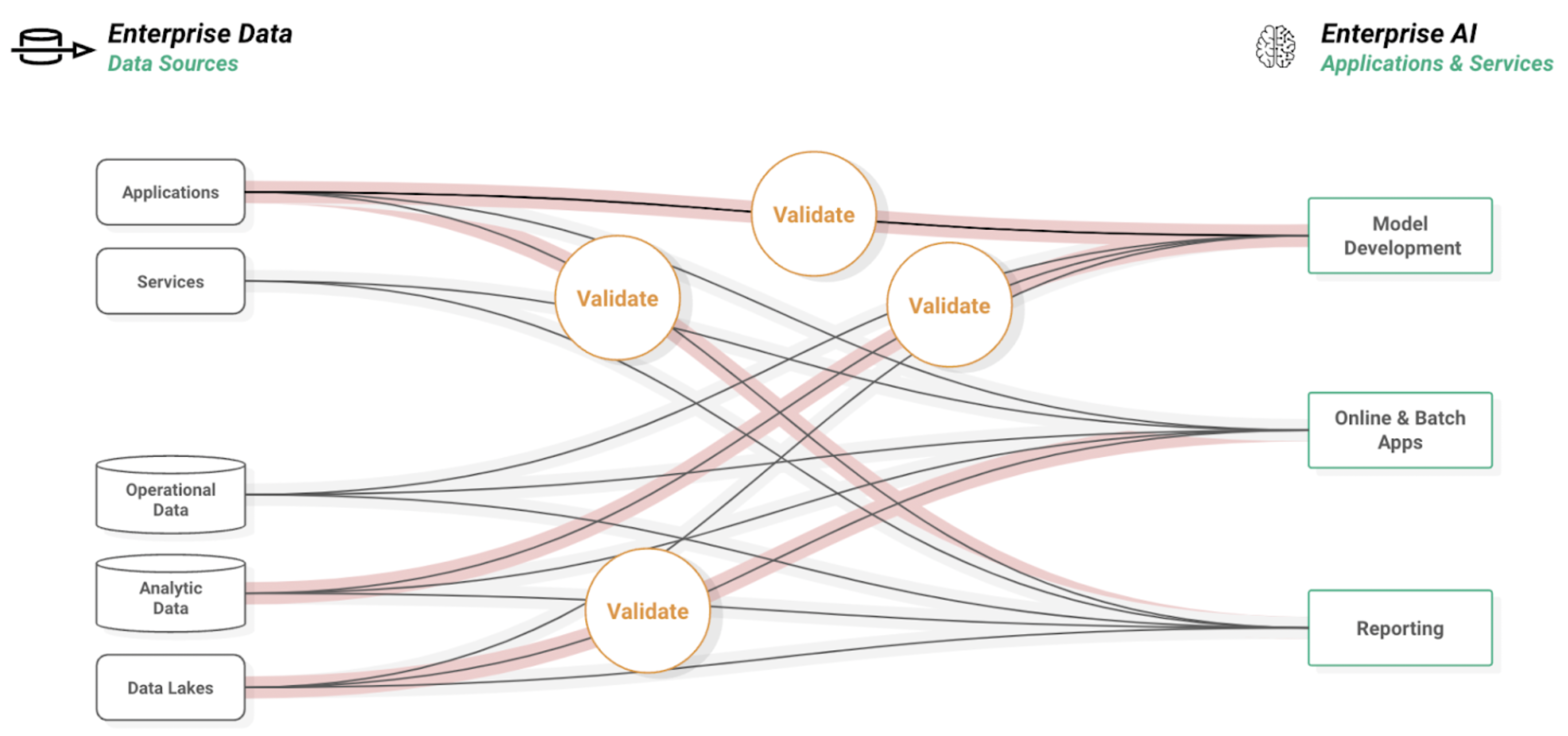
Figure 1. Feature Engineering pipelines set up with its own validation for every use-case. As the number of applications increases, the complexity of the data stack becomes unmanageable.
The development of Machine-Learning and AI systems usually requires setting up a Feature Engineering (FE) pipeline to collect raw data from the various data sources and transform them into suitable inputs. The multiplication of use cases leads to the multiplication of these pipelines, slowly increasing the architectural complexity of an organization's data stack. While reusing a Feature across multiple systems is not uncommon, it is often complicated and impractical to share and reuse only parts of FE pipelines.
In addition, these systems heavily rely on high-quality data to make accurate predictions. A datetime parsing error could lead a recommendation service to fail to suggest current trending movies. A degradation in the underlying data therefore directly impacts the quality of the service for the users. It has thus become best practice to include data validation steps in feature engineering pipelines in order to monitor data quality and ensure that the collected data meet production requirements.
These issues compound to increase the burden on the data engineering team. Indeed, the workload due to maintenance alone of an increasing number of pipelines with evolving requirements severely limits the team's ability to support new projects or develop innovative Features. Hopsworks platform and its Feature Store aims to provide a purpose built Feature database which unifies the data stack to scale to hundreds of use-cases without scaling your team to hundreds of data engineers.

Figure 2. Hopsworks Feature Store is a central piece of the modern data stack. Data engineers write high-quality validated data to Feature Group to be made available to all other stakeholders. Data Scientists can search and select Features and query them directly from python with an API adapted to their use-case.
Hopsworks Platform and Enterprise Feature Store
The Hopsworks Platform and its Feature Store are designed to overcome the obstacles associated with the development, deployment, and operations of features. At its core lies the Feature Store, an online and offline database whose API is designed specifically to write and read Features. Hopsworks 3.0 and its python client integrates with Great Expectations to offer Data Validation capabilities ensuring consistent data quality for downstream users.
Create a Feature Group in the Feature Store to hold your data. Provide minimal metadata and directly insert a Pandas DataFrame to populate it.
The Feature Store is a natural endpoint for a feature pipeline. By creating a Feature Group, data engineering teams can insert Pandas or Spark DataFrames directly into the Feature Store. The columns of a DataFrame are Features that can be easily searched on Hopsworks UI to help Data Scientists or Business Analysts identify data relevant to the task at hand. The feature definition is found in the Python code used to create the DataFrame.
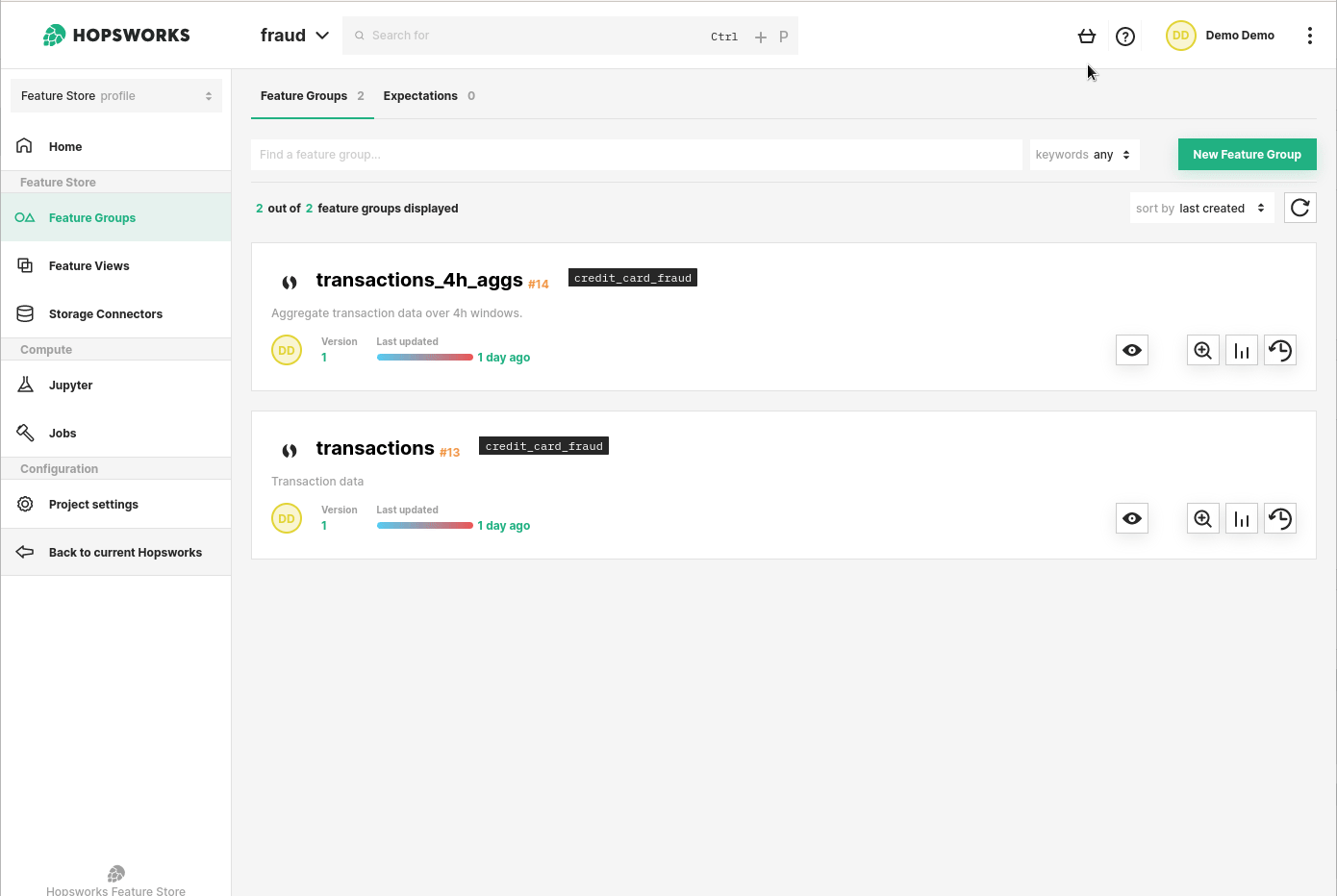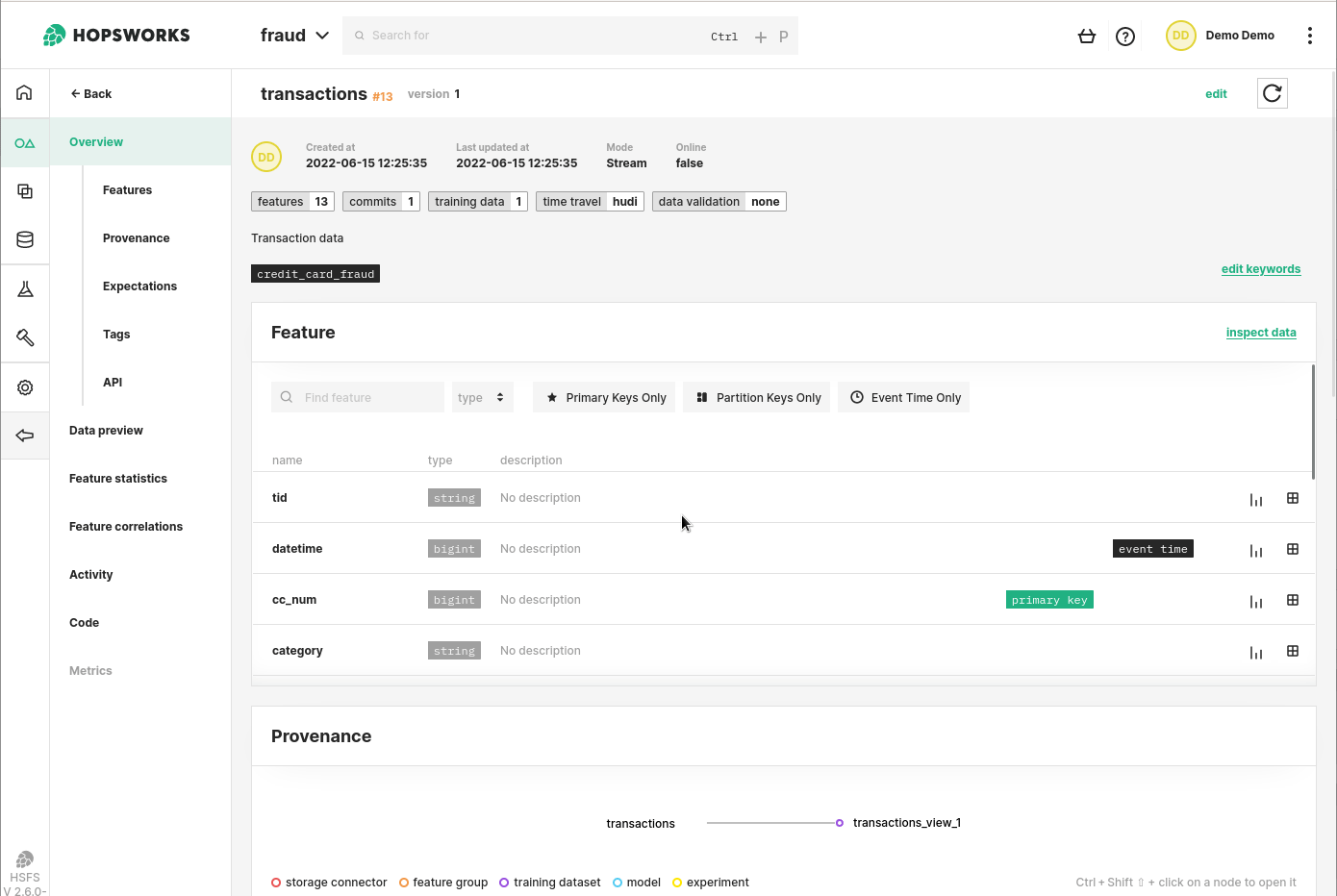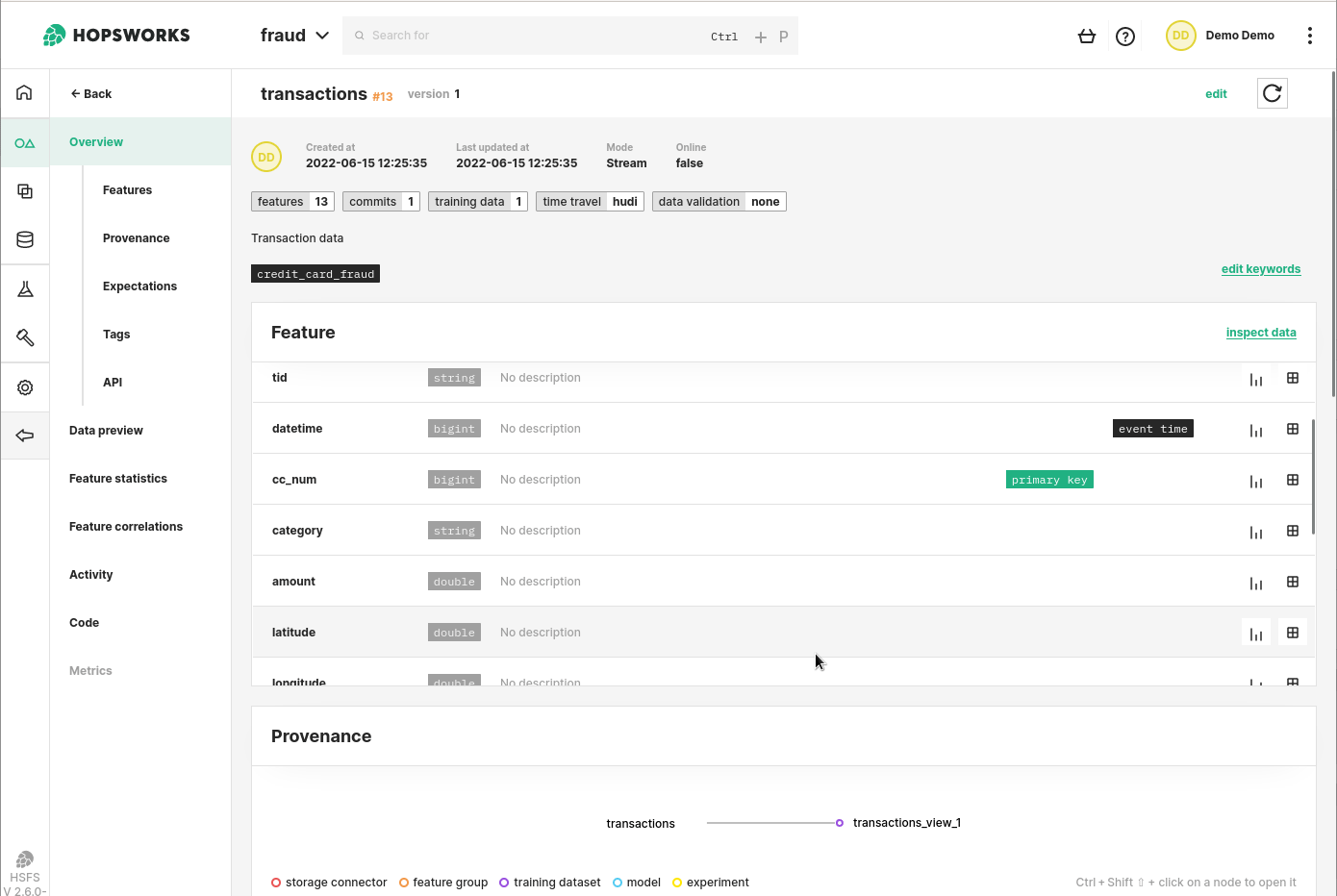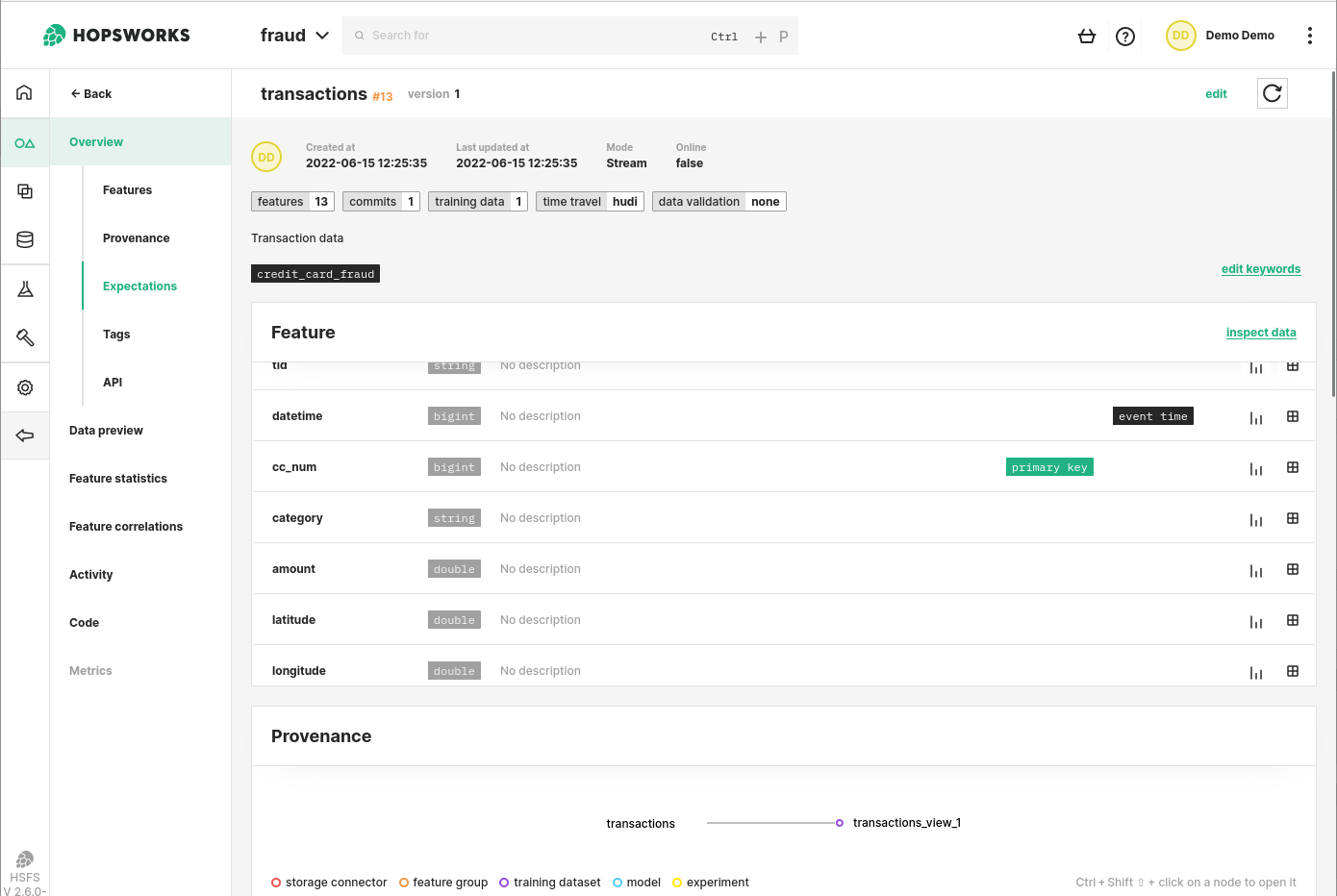
Figure 3. Feature Groups are a core abstraction in Hopsworks. Feature data can be regularly inserted into a FG to be made available for Data Scientists or Business analysts. Once a Feature exists in the Feature Store, it can be used and reused at no cost for the data engineering team.
The Feature View abstraction allows Data Scientists to select the desired Features from various Feature Groups to create an input schema for a model. In a single line of code, one can then create a corresponding training and testing dataset. For online applications which query pre-engineered features in real-time, the Feature View API also enables online serving of Feature vectors.
Hopsworks integrates with Great Expectations to enable validation of data which are about to be inserted into the Feature Store. This allows data validation to act both as a gatekeeper for the Feature Store but also to monitor and document the incoming data. Gatekeeping ensures that production projects can maintain high quality data, while monitoring enables the team to follow the evolution of the underlying data. The aim should be to create confidence for downstream users that the data in the Feature Store have been thoroughly validated and can be relied on for production grade applications, especially for online enable projects.
One of the key values of a Feature Store lies in the increased reusability of Features. The data engineering team only needs to compute and validate Features once, independently of the number of use-cases (models, online services, business reports, etc...). This massively reduces the burden on the data engineering team to maintain and set up pipelines for individual use cases. In that regard, the Feature Store is the perfect layer to mediate the interaction between data engineers and data scientists. It enables data scientists to try out different combinations of Features to train new models without requiring support from the data engineering team. With Hopsworks Feature Store they can directly search for Features and create datasets from the dedicated Feature View API without any knowledge of the complicated data collection infrastructure.
Build Data Validation Steps Using Great Expectations
Great Expectations (GE) is a python package that has exploded in popularity in recent years. Designed to validate DataFrames in Pandas or Spark, it elegantly combines data validation with data monitoring capabilities.
At its core, GE splits the data validation tasks into two components. These components are then bundled into a so-called Expectation.
- Expectation Type : The actual metric to be computed or the test to be performed on the provided data. How to perform this calculation or test is implemented in the GE library (e.g., compute the arithmetic mean of a column of a pandas DataFrame)
- Kwargs: Define the success criteria to determine whether validation was a success or not and other potential configuration options such as the column(s) on which to perform the calculation.
Expectation in Great Expectations, configure it to suit your needs

Figure 4. Expectation Suite in Great Expectations
Expectations are the individual building blocks that can be added to an Expectation Suite to set up a Data Validation step in your Feature Engineering pipeline. A fully fledged Expectation Suite contains all the Expectations necessary to validate all the Features in the pipeline.
Create an Expectation Suite to hold your list of Expectations. Each Feature comes with its specificities, so use Expectations as building blocks to build a data validation step which matches your context
It can be passed along to the GE validator along with a DataFrame to generate a Validation Report. The report collects metadata on the validation steps as well as all the Validation Results from the individual expectations. These results contain essential information about the quality of the underlying data such as the computed metric or the proportion of value satisfying the Expectation.
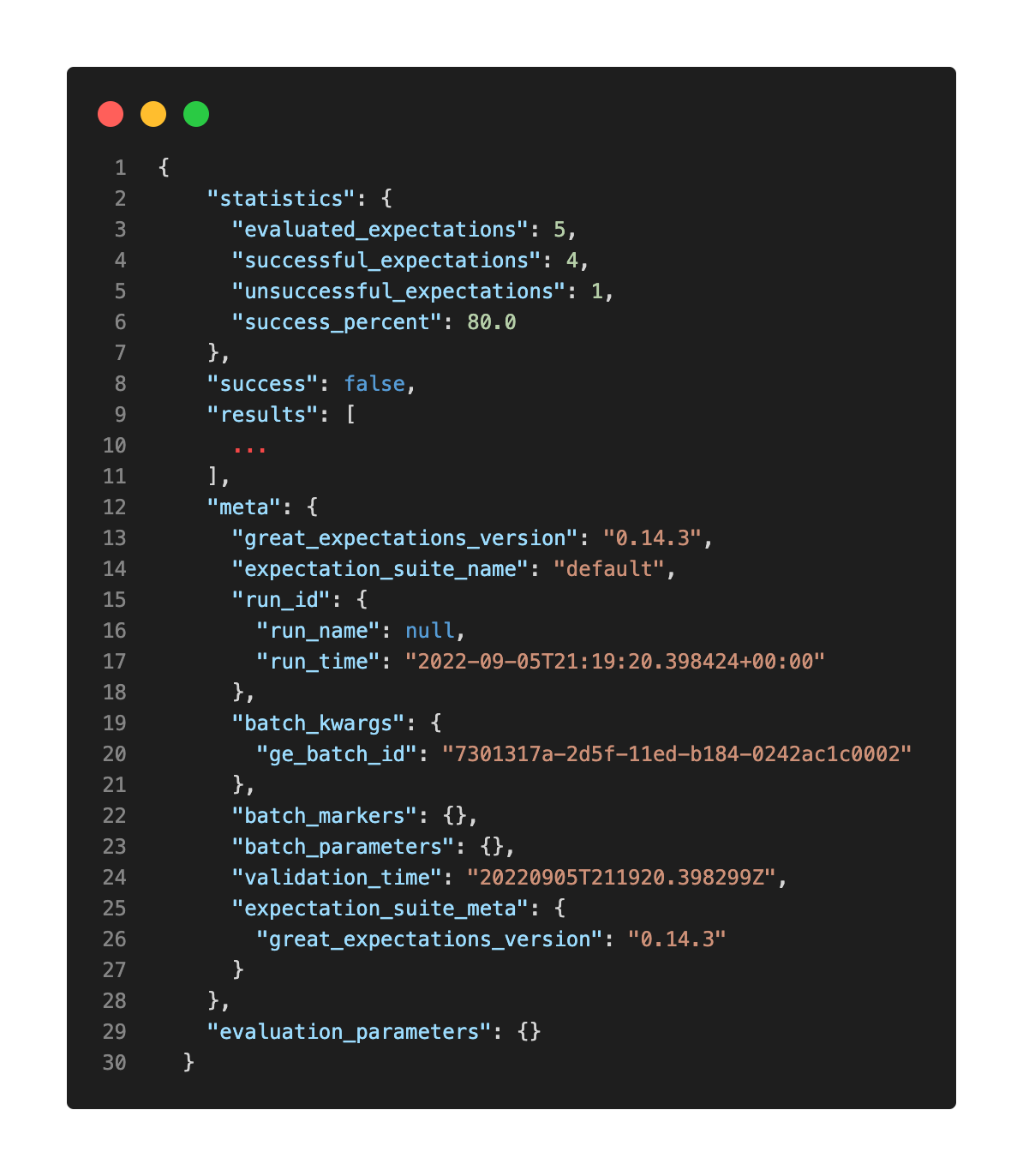
Figure 5. Validation Report from Great Expectations

Figure 6. Validation Result in Great Expectations
Integrating Great Expectations with Hopsworks
As the Feature Store simplifies and encourages the reuse of features, it makes sense to validate data before writing to any Feature Groups. Data validation is performed once per feature rather than once per use-case. Not only does it reduce the validation burden on the data engineering team but it also builds trust in the quality of the data available in the Feature Store.
Feature Groups (FG) in Hopsworks are defined by a schema (similar to a Pandas DataFrame or a table in a relational database). The schema consists of feature names and data types. One can think of these FGs as a destination table where feature pipelines regularly insert DataFrames, appending, updating, or deleting rows. Adding validation starts with defining an Expectation Suite in Great Expectations. It will hold all of the Expectations required to validate DataFrames to be inserted into the FG. It is then a matter of writing a job to perform validation manually. However this generates a lot of boilerplate and additional management such as storing and fetching the suite, running validation, storing and fetching reports, and alerts on failure.
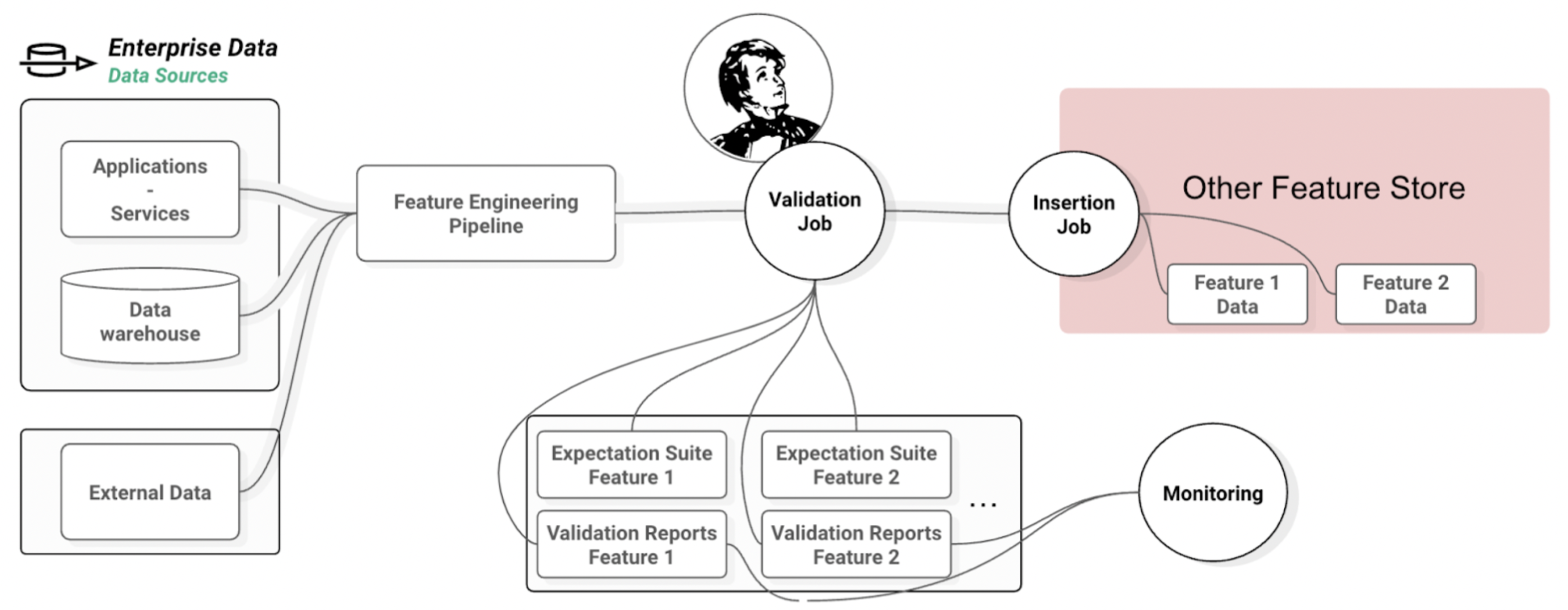
Figure 7. Data Validation as an additional step in your Feature Engineering Pipeline leads to increased complexity and additional storage management.
Taking advantage of Great Expectations integration eliminates these obstacles. Simply attach your GE expectation suite to a FG, and Hopsworks python client will take care of the data validation step automatically on every insert. In addition the Feature Store centralizes everything by storing both the data, the suite and validation reports.
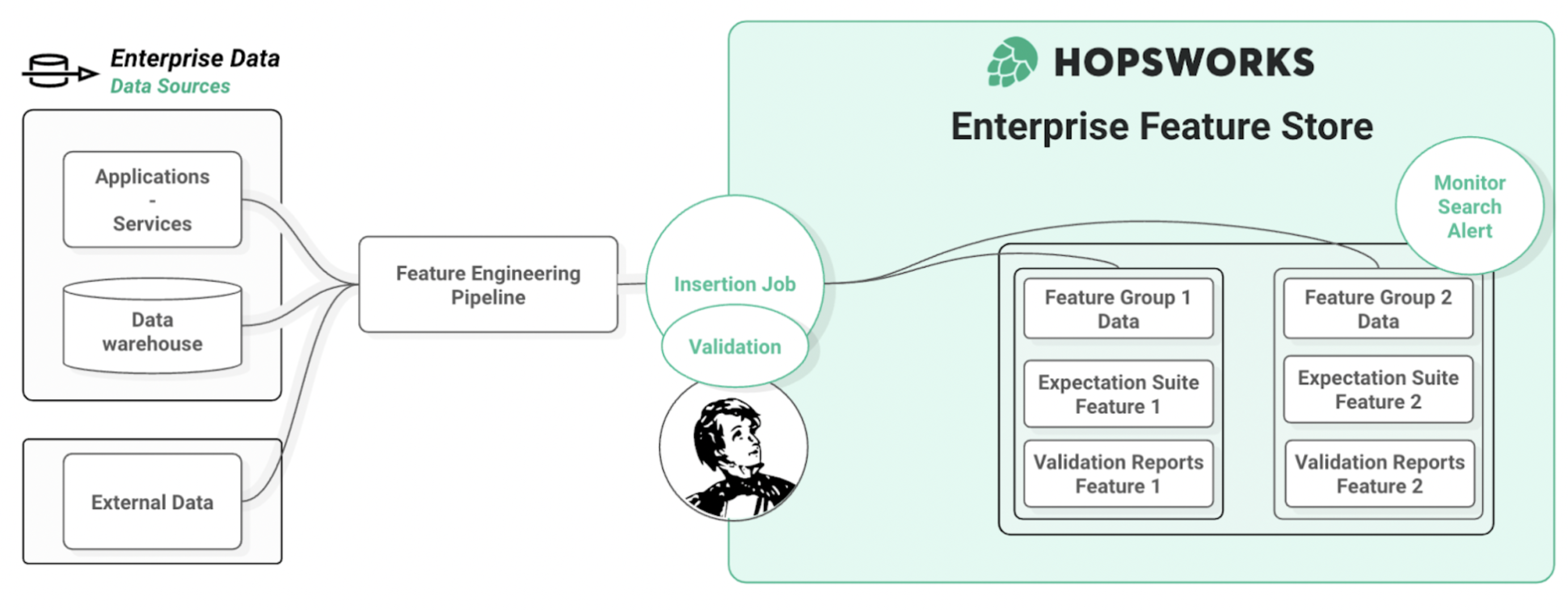
Figure 8. Automatic Validation on Insertion with Hopsworks Feature Store. Store data and validation in a single place to enable easy monitoring and reduce overhead.
This not only reduces the workload of the data engineering team but enables you to keep an eye on validation while checking the FG page on the Hopsworks UI.
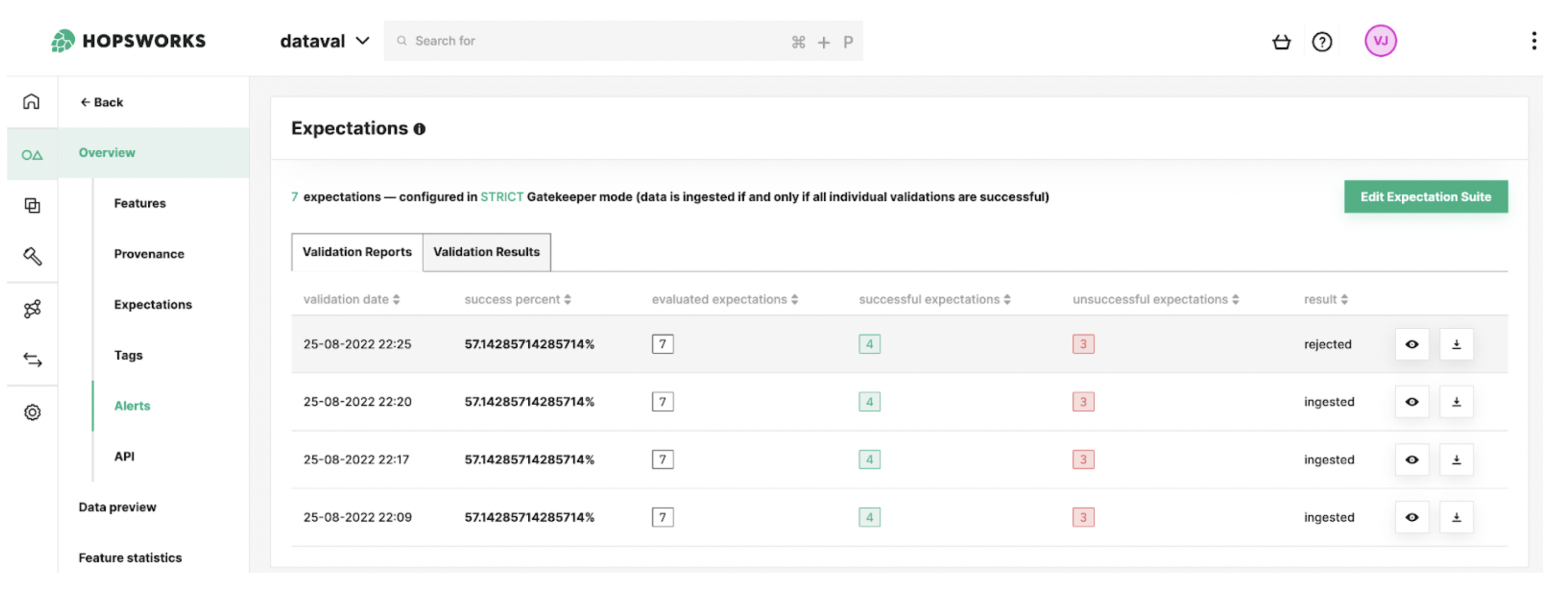
Figure 9. The validation report history keeps track of the quality of the data inserted into the Feature Group.
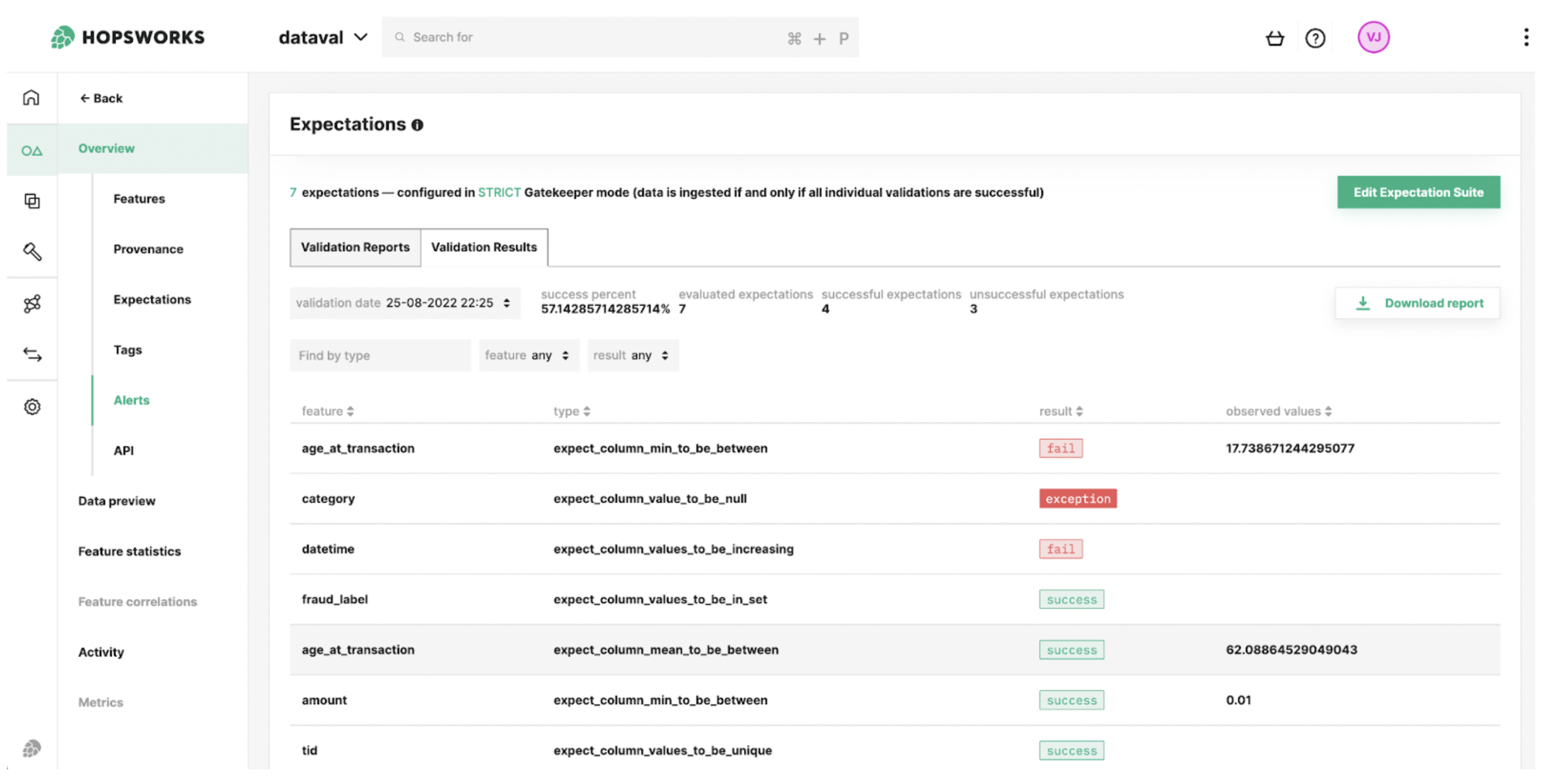
Figure 10. The validation result summaries provide a quick overview of whether the Expectations succeeded or failed.
Take advantage of Hopsworks API to streamline your Data Validation workflow
You can choose between two ingestion policies when adding Data Validation to Hopsworks in order to fit your project requirements. To avoid Data Validation becoming an obstacle in the early phase of a project, the ingestion policy defaults to "ALWAYS". Data insertion is always performed regardless of whether data validation succeeded or not. Validation via Great Expectations will, however, generate and upload reports on every insertion. Your team can then use them to build a better understanding of the underlying data and refine the Feature Engineering pipeline.
Set an ingestion policy that matches your context : "ALWAYS" to use data validation to monitor an early phase project, "STRICT" to enable gatekeeping for production grade data.
However as projects mature and move closer to production, you can set the ingestion policy to "STRICT" to block the insertion of data which do not meet production standards. This is particularly important for services using the Online Feature Store. Indeed, such online data can be queried at any time by a model in production. A deterioration of the data quality in the Online Feature Store could directly reduce the predictive accuracy of models relying on those features.
When working on your feature engineering pipeline you want to constantly keep an eye on whether your changes are breaking data validation. Once you are connected to Hopsworks, you can use your registered expectation suite to check for breaking changes. You can even choose to upload the validation report to keep track of your experimentation. This functionality can also be particularly convenient if you have a large dataset to insert and want to check whether a sample passes the validation checks.
Use your registered Expectation to validate data samples and investigate errors before uploading large batches.
To keep track of evolving requirements, Hopsworks makes it simple to fetch your Expectation Suite. Returning a native GE object means you can immediately edit it using the native Great Expectations API. Simply attach the edited suite to make use of Hopsworks automatic validation on insertion functionality. There is no need to update the feature engineering script performing the insertion. The new Expectation Suite will be the new ground truth for all subsequent insertions.
Quickly edit your Expectation Suite to adapt to evolving data requirements.
Setting data quality standards is one of these tasks that can require collaboration with other parts of the organization. To get everyone onboard, Hopsworks provides a UI to edit the Expectation Suite. It allows any of your colleagues with access to contribute to writing data quality checks. They can then monitor the validation history on the Feature Group page to verify that the ingested data complies with their requirements.
Conclusion
Hopsworks Feature Store is the perfect solution to simplify complex dependency relations between data sources and "smart" services. It acts as a central layer providing values to both data engineers and data scientists. The former can take advantage of the Feature Group API to write high quality features, either online or offline. While the latter can take advantage of the Feature View API, combining and joining existing features to create training datasets or batch inference data.
The integration with Great Expectation enables automatic pre-insertion validation with the Hopsworks python client. You simply define your Expectation Suite and attach it to your Feature Group. Hopsworks stores both data and validation artifacts, enabling easy monitoring on the Feature Group UI page.
Next Steps
Thanks for reading! Register on Hopsworks and try to create your very own data validated Feature Group for free with code snippet below:
Create your own data validated Feature Group in a few lines of code using Great Expectations Profiler and its integration with Hopsworks Feature Store
You can also check out our data validation tutorial using Great Expectation on Hopsworks AI.