Scalable metadata: the new breed of file systems (em)powering big data companies
HopsFS is an open-source scaleout metadata file system, but its primary use case is not Exabyte storage, rather customizable consistent metadata.

A Data-Center Scale File System
Google, Microsoft, and Facebook have been pushing out the state-of-the-art in scalable systems research in the last 15 years. Google has presented systems like MapReduce, GFS, Borg, and Spanner. Microsoft introduced CosmosDB, Azure Blob Storage and federated YARN. Facebook has provided Hive, Haystack, and F4 systems. All of these companies have huge amounts of data (Exabytes) under management, and need to efficiently, securely, and durably store that data in data centers. So, why not unify all storage systems within a single data center to more efficiently manage all of its data? That’s what Google and Facebook have done with Colossus and Tectonic, respectively. The other two scaleout metadata file systems covered here, ADLSv2 and HopsFS, were motivated by similar scalability challenges but, although they could be, they are typically not deployed as data center scale file systems, just as scalable file systems for analytics and machine learning.
The Problem and where we are today
First generation hierarchical distributed file systems (like HDFS) were not scalable enough in the cloud, motivating the move to object stores (like S3) as the cloud-native storage service of choice. However, the move to object stores is not without costs. Many applications need to be rewritten as the stronger POSIX-like behaviour of hierarchical file systems (atomic move/rename, consistent read-after-writes) has been replaced by weakened guarantees in object stores. In particular, data analytics frameworks traditionally rely on atomic rename to provide atomic update guarantees for updating columnar data stores. The lack of atomic rename in S3 has been one of the motivations for the introduction of new columnar store frameworks for analytics and ML, such as Delta Lake, Apache Hudi, and Apache Iceberg that provide ACID guarantees for updating tables over object stores. These frameworks add metadata to files in the object store to provide the ACID guarantees, but their performance lags behind systems built on mutable scaleout metadata, underpinning columnar data stores such as Snowflake and BigQuery.
Metadata: The Hierarchical File System Scalability Bottleneck
Hierarchical file systems typically provide well-defined behaviour (a POSIX API) for how a client can securely create, read, write, modify, delete, organize, and find files. The data in such file systems is stored in files as blocks or extents. A file is divided up into blocks, and distributed file systems spread and replicate these blocks over many servers for improved performance (you can read many blocks in parallel from different block servers) and high availability (failure of a block server does not cause the file system to go down, as replicas of that block are still available on other block servers).
However, the data about what files, directories, blocks, and file system permissions are in the system have historically been stored in a single server called the metaserver or namenode. We call this data about the file system objects metadata. In file systems like HDFS, the namenode stores its metadata in-memory to improve both latency and throughput in the number of metadata operations it can support per second. Example metadata operations are: create a directory, move or rename a file or directory, change file permissions or ownership. Operations on files and some operations on directories (such as `rm -rf`) require both updates to metadata and to the blocks stored on the block servers.
As the size of data under management by distributed file systems increased, it was quickly discovered that metadata servers became a bottleneck. For example, HDFS could scale to, at a push, a Petabyte, but not handle more than 100K reads/sec and only a few thousand writes/sec.
It has long been desired to re-architect distributed file systems to shard their metadata across many servers to enable them to support (1) larger volumes of metadata and (2) more operations/second. But it is a very hard problem. Read here about the contortions Uber applies to get its HDFS’ namenode to scale instead of re-designing a scaleout metadata layer from scratch.
Scaleout, Consistent Metadata
When sharding the state of the metadata server over many servers, you need to make decisions about how to do it. Google used its existing BigTable key-value store to store Colossus’ metadata. Facebook, similarly, chose the ZippyDB key-value store for Tectonic. Microsoft built their own Replicated State Library - Hekaton Ring Service (RSL-HK) to scale-out ADLS’ metadata. The RSL-HK ring architecture combines Paxos-based metadata with Hekaton (in-memory engine from SQL Server). HopsFS used NDBCluster (now RonDB) to scale out its metadata.
The capabilities of these underlying storage engines are reflected in the semantics provided by the higher level file systems. For example, Tectonic and (probably) Colossus do not support atomic move of files from any directory to any other directory. Their key-value stores do not support agreement protocols across shards (only within a shard). So, at the file system level, you introduce an abstraction like a file system volume (Tectonic calls them tenants), and users then know they can perform atomic rename/move within that volume, but not across volumes. Google solves this problem at a higher layer for structured data with Spanner by implementing two-phase commit transactions to ensure consistency across shards. In contrast, RSL-HK Ring by Microsoft and RonDB by Hopsworks support cross-shard transactions that enable both ADLSv2 and HopsFS to support atomic rename/move between any two paths in the file system.
To put this in database terms, the consistency models provided by the scaleout metadata file systems are tightly coupled to the capabilities provided by the underlying metadata store. If the store does not support cross-partition transactions - consistent operations across multiple shards, you will not get strongly consistent cross-partition file system operations. For example, if the metadata store is a key-value store, where each shard typically maintains strongly consistent key-value data using Paxos. But Paxos do not compose - you cannot run Paxos between two shards that themselves maintain consistency using Paxos. In contrast, RonDB supports 2-phase commit (2PC) across shards, enabling strongly consistent metadata operations both within shards and across shards.
Once a scaleout metadata storage layer is in place, stateless services can be used to provide access control and implement background maintenance tasks like maintaining the durability and availability of data, disk space balancing, and repairing blocks.
Scaleout Metadata File Systems Overview
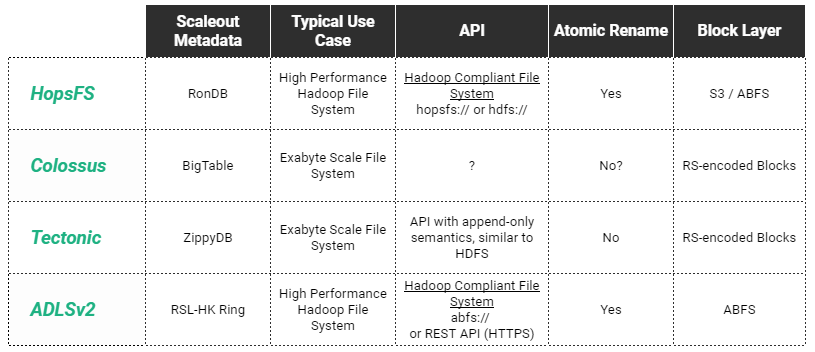
We can see that Hadoop File System APIs are still popular, as they model the contents of a filesystem as a set of paths that are either directories, symbolic links, or files, but address the challenge of scalability by restricting the POSIX-like semantics with append-only writers (there is no support for writing at random offsets in files).
Partitioning Scheme
With a scaleout metadata file system, you can have many more concurrent clients, leading to the well-known problem of hotspots - overloaded read/writes that are handled by a single shard. For example, Tectonic, ADLS, and HopsFS all ensure that objects (files/directories) in a directory are co-located in the same shard for efficient low latency directory listing operations. However, if the directory contains millions of files, such an operation can overload the threads responsible for handling operations on that shard. HopsFS and Tectonic randomly spread independent directories across shards to prevent hotspots, while ADLS supports range partitioning. Another well-known technique from object-stores, like S3, is used by ADLS - paged enumeration of directories. This requires clients to perform many iterative operations to list all objects in a large directory, but enables client quotas to kick in throttle and clients before they overload a shard.
Block Layer
Blocks are a logical unit of storage that hides the complexity of raw data storage and durability from the upper layers of the filesystem. In earlier generations of distributed file systems, such as HDFS, full replicas of blocks were stored at different data nodes to ensure high availability of file blocks. However, object stores and scaleout metadata file systems have eschewed full replicas and instead ensure high availability of file blocks using Reed-Solomon (RS) Coding. RS-encoded blocks provide higher availability guarantees and lower storage overhead, but with the disadvantage of more CPU and network bandwidth required to recover lost blocks. Given the continued growth in network bandwidth and available CPU cycles, this tradeoff is favorable.
There is a general trend towards smaller blocks, enabling faster recovery of failed blocks and faster availability of blocks to readers, but the cost is the need for more metadata storage capacity and higher available throughput in ops/sec at the metadata service.
Both Colossus and Tectonic provide rich clients that can customize the types of blocks and RS coding needs, depending on the workload needed by the client. For example, blob storage requires frequent appends and is handled differently from writing tabular data. Although neither Tectonic or Colossus discussed the block sizes they support, it is safe to assume that they support blocks all the way down to a few MBs in size. ADLSv2 stores its block data in Azure Blob Storage (ABS). HopsFS, the managed service on www.hopsworks.ai, also stores its blocks as objects in object storage (S3 on AWS and ABS on Azure). On premises, HopsFS stores its blocks replicated as fixed-size files replicated across data nodes.
Hot and Cold Data Tiers
When your ambition is to store data for the entire data center, you need to support many different storage technologies with different cost/storage trade-offs. As such, Colossus, HopsFS, ADLSv2, and Tectonic all support storing data in tiers: magnetic disks, SSDs, NVMe, in-memory. Among these systems, HopsFS has unique support for storing small files in the scaleout metadata layer for higher performance operations on small files.
Extended, Searchable Metadata
HopsFS takes a different approach to using scaleout metadata. Instead of using it, primarily, to build exascale file systems, it provides a principled architecture for easily extending metadata for files and directories. In particular, this is useful in the domain of machine learning where we have both artifacts (feature data, training data, programs, models, log files) that are typically stored as files and metadata (experiments, hyperparameters, tags, metrics, etc ) that are stored in a metastore (often a relational database). HopsFS unifies the artifact store and metastore, and even enables polyglot storage and querying of metadata in both RonDB (SQL) and Elasticsearch (free-text search). This simplifies operations and provides new free-text search capabilities compared to existing ML metastores (TFX, MLFlow). The same approach enabled us to be the first to release an open-source Feature Store for ML based on Hopsworks. When building our Feature Store, instead of needing to build a separate artifact store (file system) and metastore (database) and write complex protocols to ensure the consistency of both stores, we had a single consistent storage system, where artifacts can be easily extended with consistent metadata that can be queried using free-text search. Features can be annotated with statistics and tags in metadata, training data
Some important requirements for extensible file system metadata are that it:
- is never orphaned, otherwise i might discover a file or directory that doesn’t really exist. HopsFS achieves this with foreign keys in RonDB;
- is consistent, otherwise, i might add or annotate a file/directory with metadata, search for it, and not find it. HopsFS achieves this by encapsulating metadata operations in a single ACID transaction;
- supports low latency query/search. Search for metadata should be interactive, ideally subsecond. HopsFS realizes efficient search through the polyglot storage of metadata, in both RonDB and Elasticsearch, enabling multiple query APIs;
- easily extended by developers. In HopsFS, we can either add (metadata) tables in RonDB (with optional foreign keys to inodes to ensure metadata is consistent with the file or directory) or attach a JSON object to a file or directory, where those JSON objects are queryable from Elasticsearch.
Colossus
Even though we first heard about Colossus’ architecture in 2009 and its name in 2012, Google has been surprisingly secretive about the lowest layer of their scalable storage and compute architecture. However, after the release of Tectonic (coincidence?) in early 2021, Google released more details on Colossus in May 2021.
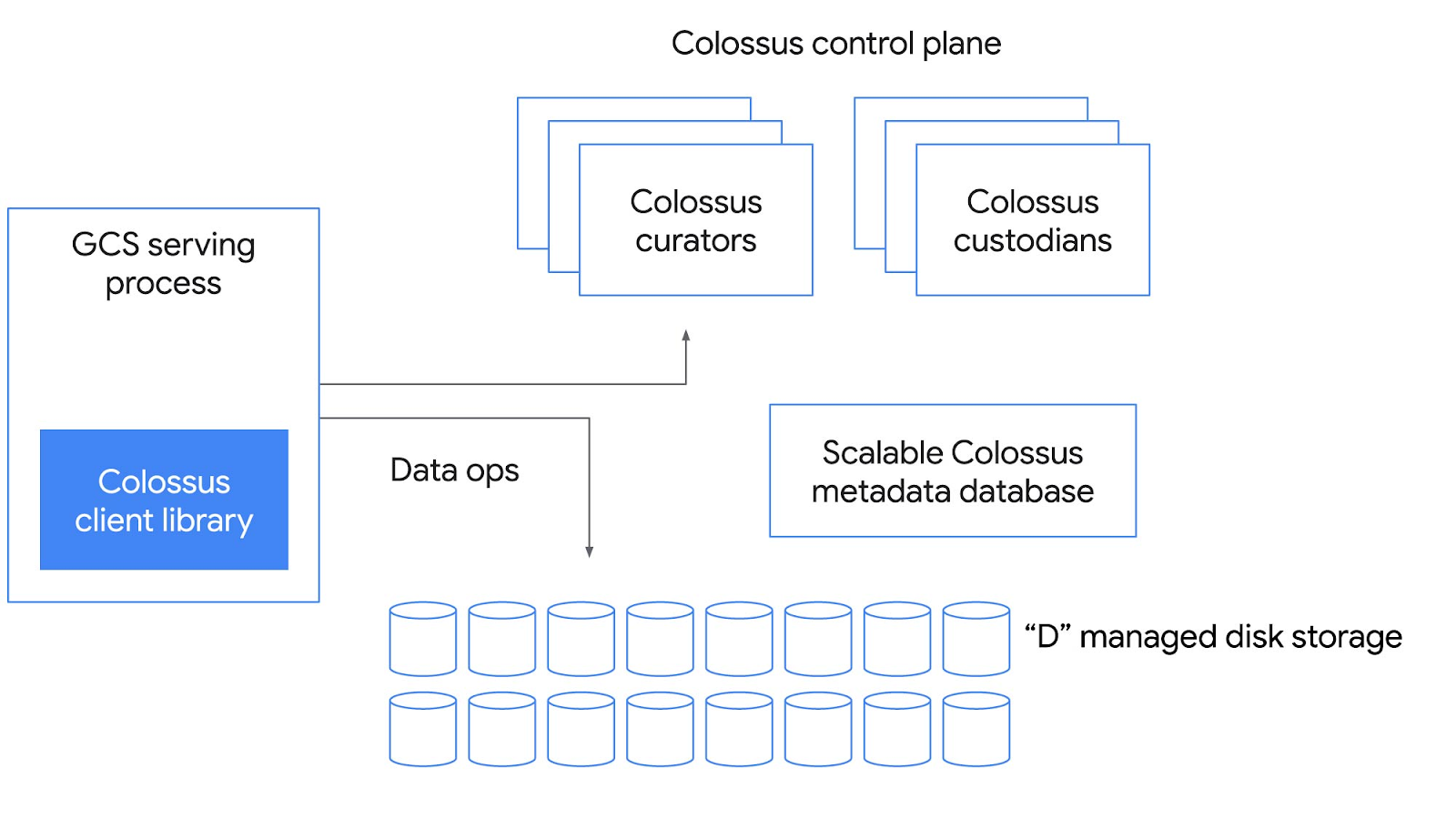
[Image from https://cloud.google.com/blog/products/storage-data-transfer/a-peek-behind-colossus-googles-file-system]
Metadata Storage System
Colossus’ metadata storage service is BigTable, which does not support cross-shard transactions. We assume this means that Colossus lacks atomic rename, a hole that is filled for tabular data (at least) by Spanner, which supports cross-shard transactions.
In Colossus, file system clients connect to curators to perform metadata operations, who, in turn, talk to BigTable. Custodians perform file system maintenance operations, and “D” services provide block storage services, where clients read/write blocks directly from/to “D” servers.
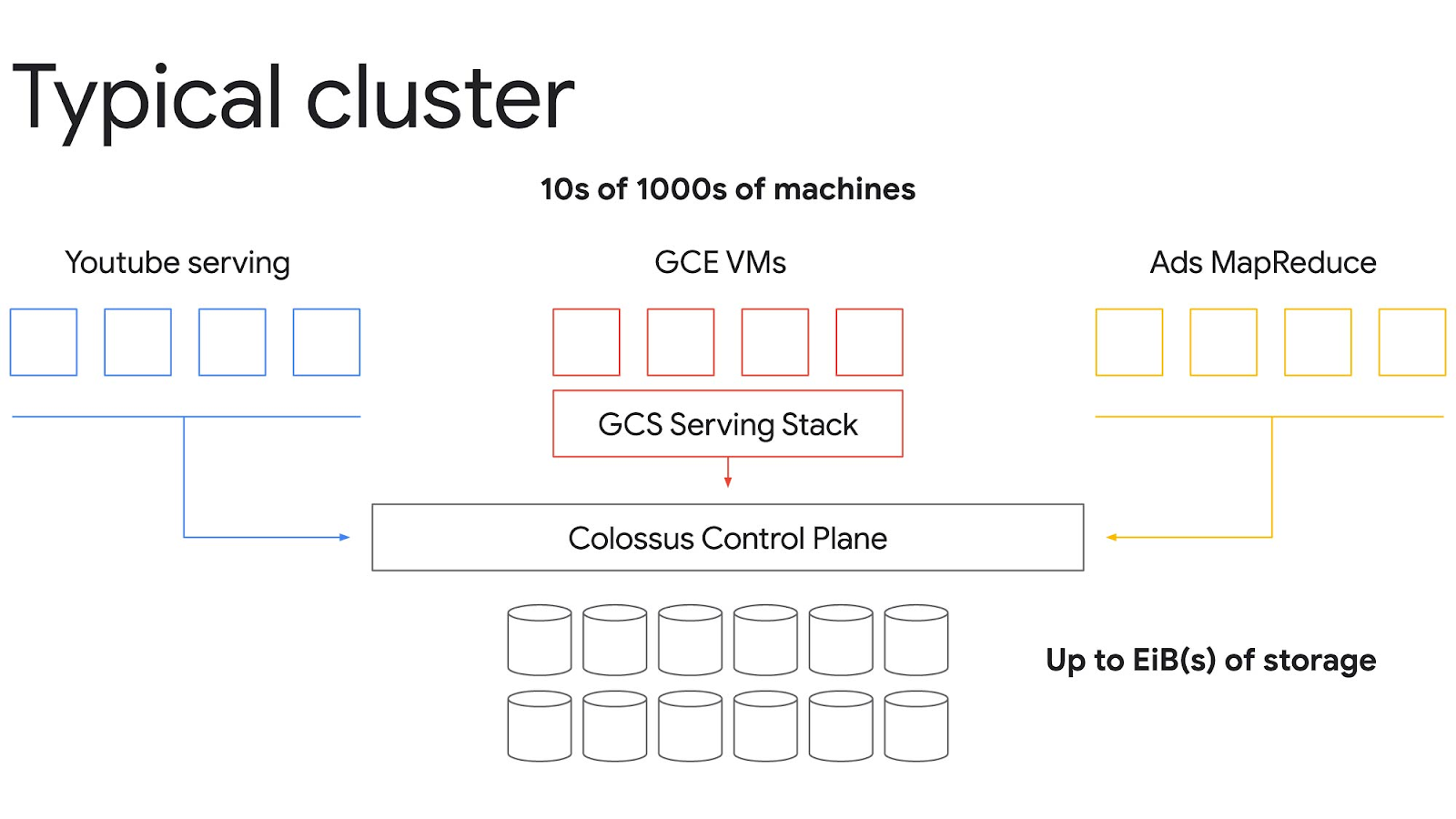
[Image from https://cloud.google.com/blog/products/storage-data-transfer/a-peek-behind-colossus-googles-file-system]
Different clients of Colossus can store their data on different volumes (metadata shards). Atomic rename is possible within a volume, but not across volumes.
Tectonic
Tectonic was first announced as a file system at USENIX Fast 2021, and it unifies Facebook’s previous storage services (federated HDFS, Haystack, and others) to provide a data-center scale file system.
Metadata Storage System
Similar to Colossus, Tectonic stores its metadata in a key-value store, but in this case in ZippyDB. As ZippyDB lacks cross-partition transactions, cross-namespace file system operations are not supported. That is, you cannot atomically move a file from one volume (metadata shard) to another. Often, such operations are not needed, as all the data for a given service can fit in a single namespace, and there are no file system operations between different applications. There are separate stateless services to manage the name space, blocks, files, and file system maintenance operations.
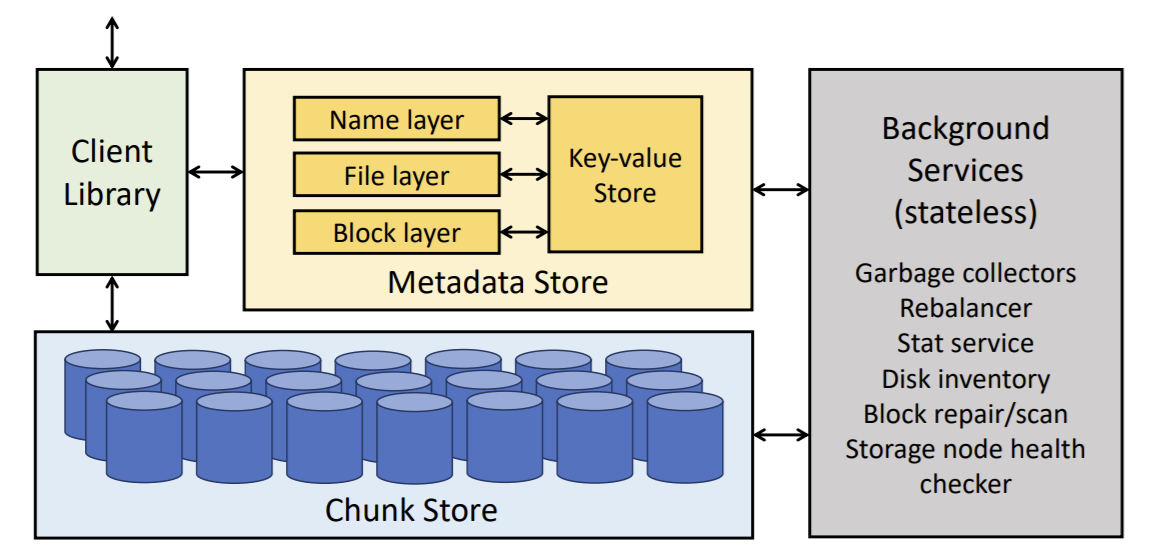
[Image from https://research.fb.com/wp-content/uploads/2021/02/Facebooks-Tectonic-Filesystem-Efficiency-from-Exascale.pdf]
ADLSv2
Azure Data Lake Storage (ADLS) was first announced at Sigmod 2017 and it supports Hadoop distributed file system (HDFS) and Cosmos APIs. It has since been redesigned as Azure Data Lake Gen 2 (ADLSv2) that provides multi-protocol support to the same data using the Hadoop File System API, the Azure Data Lake Storage API and the Azure Blob storage API. Unlike Colossus and Tectonic, it is available for use as a service - but only on Azure.
Metadata Storage System
The most recent information about ADLS’ architecture is the original paper describing ADLS from 2017 - no architecture has been published yet for ADLSv2. However, ADLS used RSL-HK to store metadata and it has a key-value store (ring) with shards using state machine replication (Paxos) and with transactions across shards, al in an in-memory engine (“It implements a novel combination of Paxos and a new transactional in-memory block data management design.”).
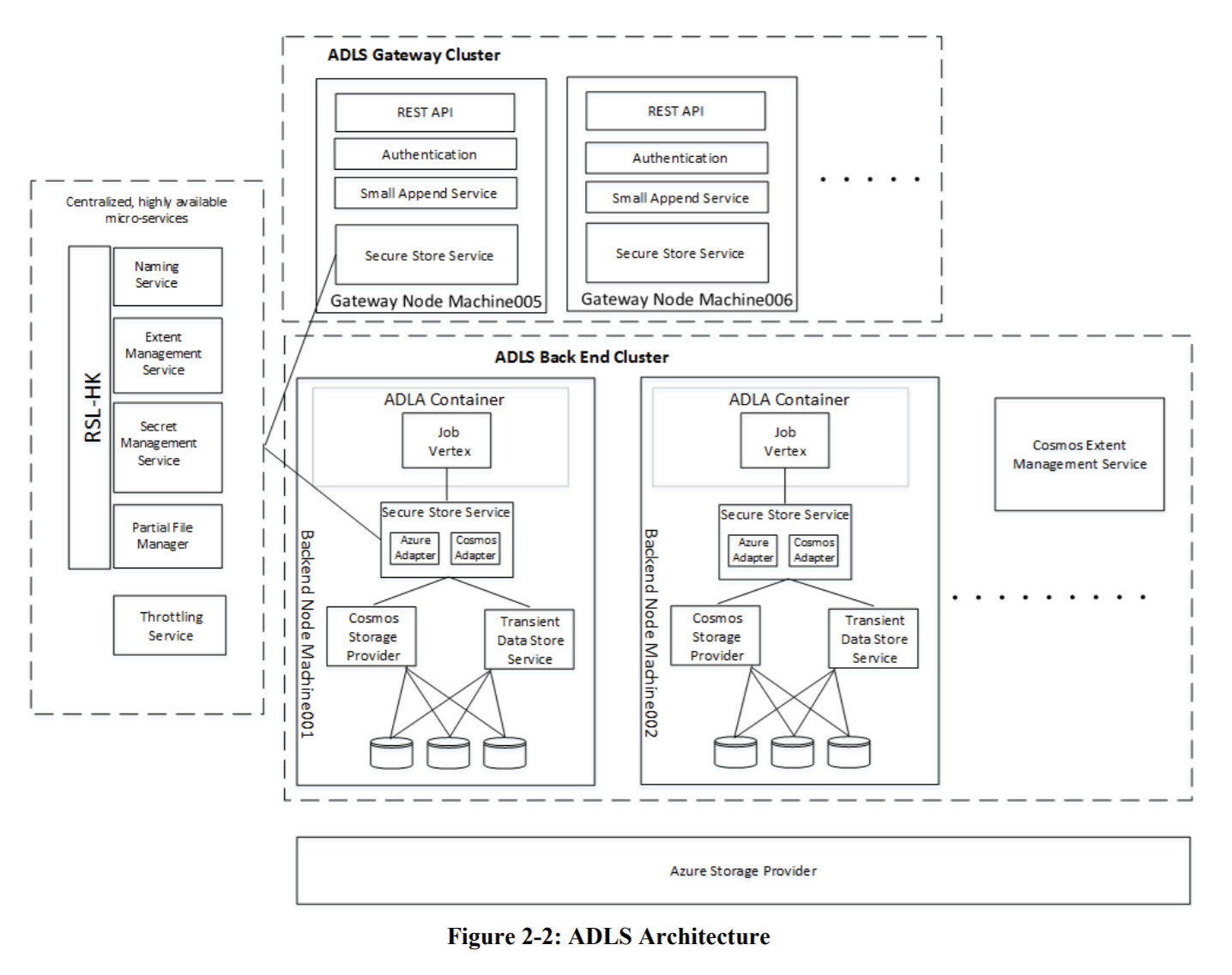
[Image from https://dl.acm.org/doi/10.1145/3035918.3056100]
HopsFS
HopsFS was first announced at USENIX Fast 2017 and provides a HDFS API. HopsFS is a rewrite of HDFS and it supports multiple stateless namenode (metadata servers), where the leader performs file system maintenance operations, and a pluggable metadata storage layer.
Metadata Storage System
HopsFS provides a DAL API to support different metadata storage engines. Currently the default engine for HopsFS is RonDB (a fork of NDB Cluster, the storage engine for MySQL Cluster), a scalable key-value store with SQL capabilities. RonDB can scale to handle hundreds of millions of transactional reads per second and 10s of millions of transactional writes per second and it provides both a native key-value API and a SQL API via a MySQL Server. RonDB also provides a CDC (change-data-capture) API to allow us to automatically replicate changes in metadata to Elasticsearch, providing a free-text search API to HopsFS’ metadata (including its extended metadata). Metadata can be queried using any of the 3 APIs: the native key-value API for RoNDB, the SQL API, or using free-text search in Elasticsearch.
RonDB: LATS (low Latency, high Availability, high Throughput, scalable Storage)
HopsFS scales the Namespace Layer with RonDB and Stateless Namenodes, while the block layer is cloud object storage.
Deja-vu all over again
The journey from a stronger POSIX-like file system to a weaker object storage paradigm and back again has parallels in the journey that databases have made in recent years. Databases made the transition from strongly consistent single-host systems (relational databases) to highly available (HA), eventually consistent distributed systems (NoSQL systems) to handle the massive increases in data managed by databases. However, NoSQL is just too hard for developers, and databases are returning to strongly consistent (but now scalable) NewSQL systems, with databases such as Spanner, CockroachDB, SingleSQL, and NDB Cluster.
The scaleout metadata file systems, introduce here, show that distributed hierarchical file systems are completing a similar journey, going from strongly consistent POSIX-compliant file systems to object stores (with their weaker consistency models), and back to distributed hierarchical file systems that are have solved the scalability problem by redesigning the file system around a mutable, scaleout metadata service.