Training Data
What is training data?
Training data refers to the data set that is used to train and evaluate a ML model. Training data consists of a large number of input examples, which include the features as well as the corresponding output or target values.
When is training data created by a feature store?
A feature store enables the reproducible creation of training data from feature groups. Training data is an immutable snapshot of feature data from the feature store and it is typically read by clients as either a DataFrame or as files (a materialized snapshot from the feature groups).
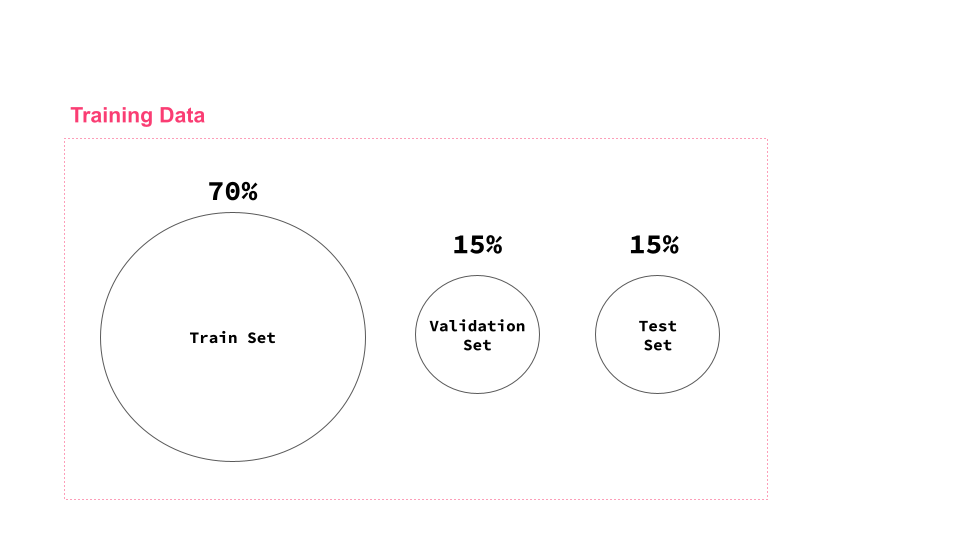
How does training data relate to the train/validation/test splits?
Training data in machine learning refers to the unsplit training data that is created by the feature store, see the image below. The training data is typically split into partitions: train, validation, and test sets. The train set is used to train the model. The validation set is used to evaluate model performance for different hyperparameters. The test set is used as a holdout set to evaluate model performance on unseen data.