Versioning (of ML Artifacts)
What is versioning of ML artifacts and why is it important for MLOps?
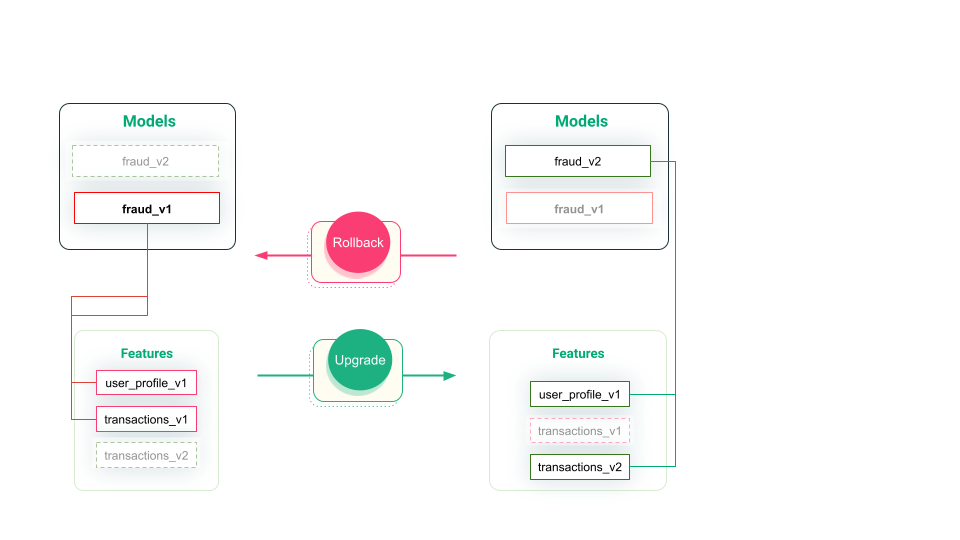
Versioning of models, features, feature groups, feature views, and training datasets enables the management of dependencies between ML artifacts. For example, in the figure below, we can see that when the fraud mode upgraded from version 1 to version 2, the precomputed features used by fraud_v2 have changed to transactions_v2. This means when you deploy the new model, you need to connect it to the correct new versions of the feature in the online feature store. If there is a problem with fraud_v2 and you rollback to fraud_v1, you need to connect fraud_v1 to transactions_v1, so the feature pipeline feeding transactions_v1 should not be turned off until you are sure you will never have to downgrade from fraud_v2. Here, we can see that versioning enables smooth upgrading and downgrading of model versions and their dependent features.