MLOps
TL; DR
MLOps is the operational framework that makes machine learning systems reliable, reproducible, and production-ready through automated pipelines, versioned artifacts, and continuous monitoring.
What is MLOps?
MLOps (Machine Learning Operations) is a set of practices that automate the development, testing, deployment, monitoring, and versioning of machine learning systems. It extends DevOps principles to ML workflows, enabling faster iteration, reproducibility, and reliable production AI systems.
Machine learning operations (MLOps) describes processes for automated testing of ML pipelines and ML artifact versioning that helps improve both developer productivity through faster iteration speed and the quality of ML systems. MLOps processes include best practices for the development of features/models, deployment of models, testing of features/models, and the monitoring of features/models in production environments.
The key principles underlying MLOps are the automated testing and versioning of ML artifacts, and integration into a CI/CD (continuous integration, continuous deployment) development process. The testing hierarchy and versioning of ML artifacts is shown in the two figures below.
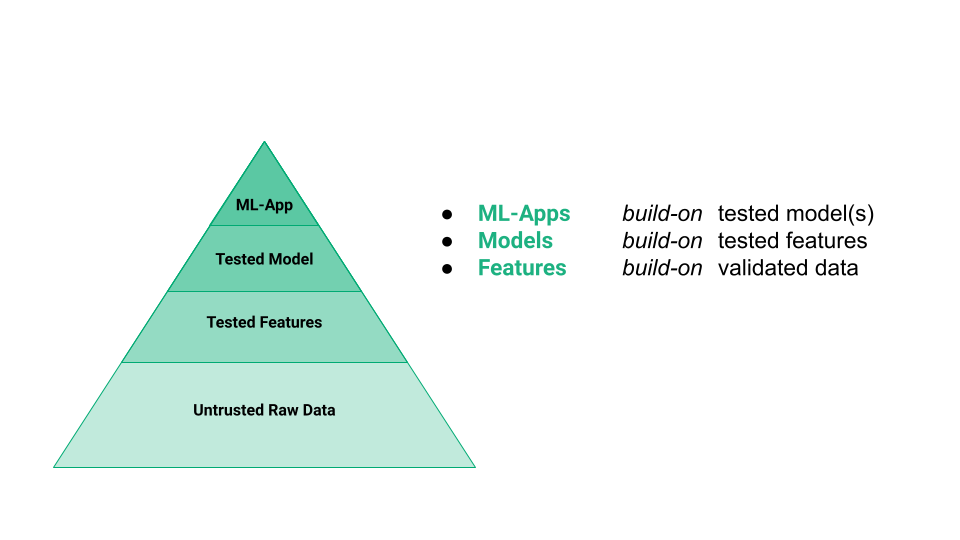
Figure 1: Hierarchy of testing involved in building ML systems
In the above figure, we can see the hierarchy of testing involved in building ML systems. Features input data and logic can be tested, making it easier to depend on models trained on those features. Similarly, ML systems can build with more confidence on models that have been tested for performance, bias, and data compatibility.
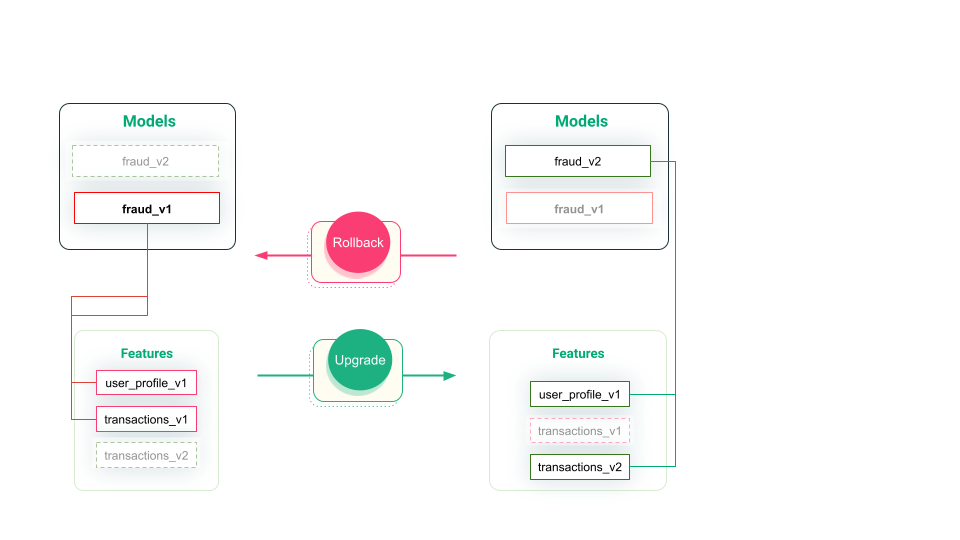
Figure 2: Upgrading/downgrading of ML systems
ML artifacts should be versioned to enable smooth upgrading/downgrading of ML systems. In the above figure, we can see that the fraud_v1 and fraud_v2 models are dependent on different versions of the transaction features: v1 and v2, respectively. When you upgrade your deployed model that uses precomputed features from a feature store, you may need to make sure that it is connected to the new feature version. You should keep both the old model version and feature versions available and keep the old feature pipeline updating v1, so that you can seamlessly downgrade to v1 without any problems.
Why MLOps Matters
MLOps matters because it addresses the operational challenges of deploying and maintaining ML systems at scale:
- Reduces model deployment time
- Prevents training-serving skew
- Enables reproducible ML experiments
How is MLOps different from DevOps?
The development and operation of ML systems has both familiar software engineering challenges (that have been addressed by automated software testing and versioning as part of the DevOps paradigm) as well as novel challenges related to data validation, feature/model drift, ML artifact versioning, ML pipeline orchestration, and infrastructure management. There are familiar unit tests from DevOps that can be used on feature functions, as well as new types of tests such as data validation, model validation, and end-to-end feature/training/inference tests.
How can you leverage MLOps in a project?
To leverage MLOps in a project, adopt a ML pipeline-first approach focusing on feature pipelines, training pipelines, and inference pipelines, producing versioned features and models as outputs, stored in a feature store and model registry, respectively. This approach decomposes building ML systems into more manageable ML pipelines that can be independently developed and tested, their outputs can be versioned, the ML pipelines can be easily composed into a working ML system.
FAQs
Is MLOps only for large organizations?
No. While originally adopted by large ML teams, MLOps practices benefit teams of all sizes by improving reproducibility and deployment reliability.
Do you need a feature store for MLOps?
A feature store is not strictly required for MLOps, but it simplifies versioning, reproducibility, and training-serving consistency in production ML systems.
Is MLOps required for LLM systems?
Yes. LLM-based systems require versioning, monitoring, and deployment practices similar to traditional ML models, especially in RAG and real-time AI applications.
How can you build a successful MLOps practice with Hopsworks?
You can build a successful MLOps practice with Hopsworks by unifying real-time feature serving, point-in-time consistent training data, versioned ML artifacts, and automated pipelines within a single AI Lakehouse platform.
Visit the Hopsworks MLOps Capabilities Page