Feature Vector
What is a feature vector?
A feature vector is a row of feature values. A training sample for a model includes a feature vector and the label(s). In inference pipelines, a feature vector is the input values to a model that, in turn, returns a prediction. In online inference pipelines, when you have a feature store, you can retrieve a precomputed feature vector. For this, your online application provides the entity_id ( primary key(s)) that is used by the feature store to return a feature vector of precomputed features for the model. The precomputed feature vector may be joined with on-demand features to produce the final (encoded) feature vector used by the model to make a prediction.
Examples of feature vectors
Let's consider a dataset of houses with two features, the size of the house in square feet and the number of bedrooms, and a label, the price of the house. A feature vector for a specific house might look like:
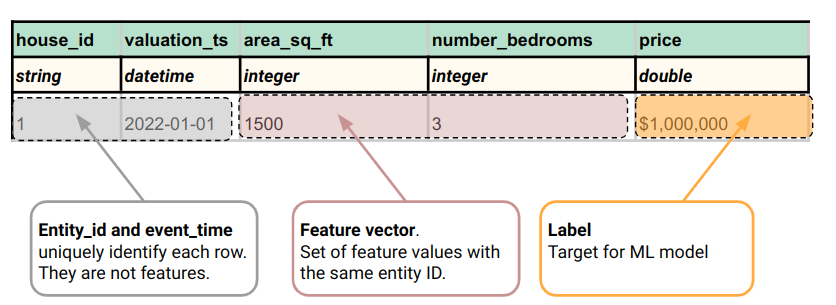
Below is a tabular figure showing the same feature vector as in the above source code, along with names for the features (area_sq_ft, number_bedrooms), the label (price), entity_id (house_id), timestamp (valuation_ts):
Are feature vectors related to vector databases?
No. A feature vector is the input to a ML model for training or inference. A vector, stored in a vector database, is typically a compressed representation of high dimensional data, created with an embedding model. Feature vectors typically consist of numerical data, as most ML algorithms require numeric data as input, but some ML algorithms, such as CatBoost, support categorical data as input. Similarly, feature vectors input to Scikit-Learn pipeline for training or inference can take mixed input data (categorical features are typically encoded as numbers in the pipeline before being input to the model).
Read feature vectors from a Feature Store for Online Inference
A feature store can be used to retrieve a single feature vector of precomputed features for an entity_id. This enables online models to use historical and contextual precomputed features in their predictions, enabling higher quality predictions.
In this example, in Hopsworks, we use a feature view’s get_feature_vector method to retrieve the feature vector:
You can retrieve a batch of feature vectors of precomputed features for a batch of entity_ids using the feature view’s get_feature_vectors method. In this case, we retrieve the feature vectors as a Pandas DataFrame: