Idempotent Machine Learning Pipelines
What is an idempotent operation?
An idempotent operation produces the same result no matter how many times you execute it. Idempotent operations can be retried after failure without worrying about side-effects, meaning they are important in building reliable, self-healing systems.
What are the benefits of idempotent ML Pipelines?
If a ML pipeline is idempotent, you can re-run it in the case of failure without having to worry about side-effects - you will always get the same output.
Idempotency and Inference Pipelines
An inference pipeline takes features and a model as input and produces prediction(s) as output. The predictions are either returned to the client (online inference) or stored in some stable storage (batch inference).
An idempotent batch inference pipeline should read the same input features from the feature store and produce the same output. For example,a non-idempotent batch inference pipeline could take as a parameter for the date range of input features as “new features that arrived today”. An idempotent version of the same pipeline would require the pipeline executor to supply the date range as a parameter. This way, an orchestration engine, such as Airflow, can run the idempotent pipeline on a schedule (e.g., daily), and for each run, it provides the range of data to perform inference on (e.g., 24th April 2023).
Online inference pipelines are more difficult to design as idempotent if they retrieve precomputed features from the feature store, as the precomputed features can change between different online inference requests.
Idempotency and Training Pipelines
A training pipeline that takes a training dataset as input and produces a model as output can be considered as idempotent. However, unless extreme care is taken to ensure that the model training was deterministic (use the same seeds when using random number generation), the resultant models may be different. For many ML algorithms, it is practically impossible to reproduce an exact copy of a model due to randomness in the algorithms (e.g., DL algorithms) and non-determinism in the hardware (e.g., GPUs).
Idempotency and Feature Pipelines
For a feature pipeline, an idempotent write to an offline feature store typically involves dropping the feature group and recreating it. This is often not desirable due to both the overhead involved and the loss of feature data history. For an online feature store that only stores the latest feature values, a feature pipeline (that correctly orders writes from clients) can safely make idempotent updates to feature values (as is done by Hopsworks, see figure below). To enable reliable incremental updates of offline feature stores, they typically support ACID operations that ensure data integrity and enable operation retries when failures occur.
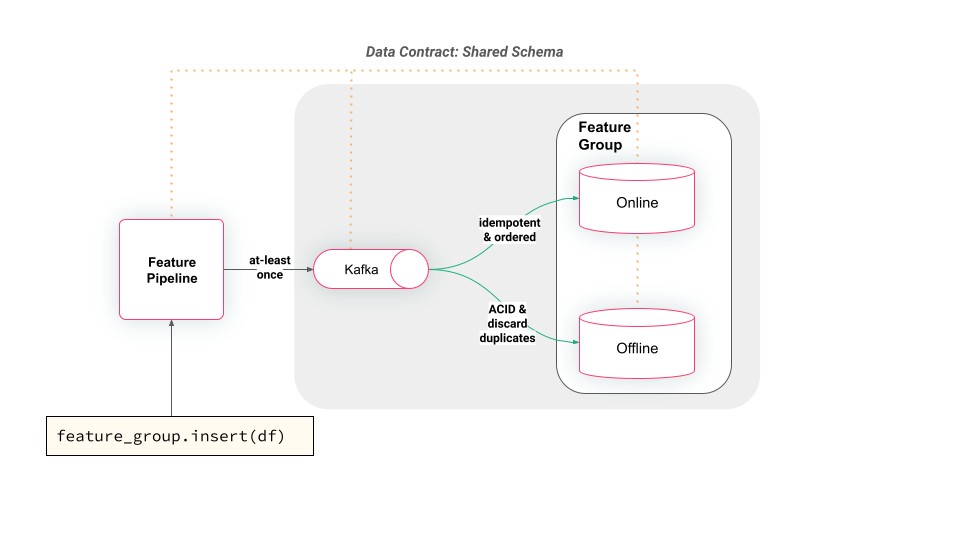
In the image above, we can see how Hopsworks receives writes through Kafka that can introduce duplicates, but consistent offline/online features are enabled through idempotent updates to the online feature store and ACID updates that discard duplicates (through Apache Hudi support) to the offline store.