Data Pipelines
What are data pipelines?
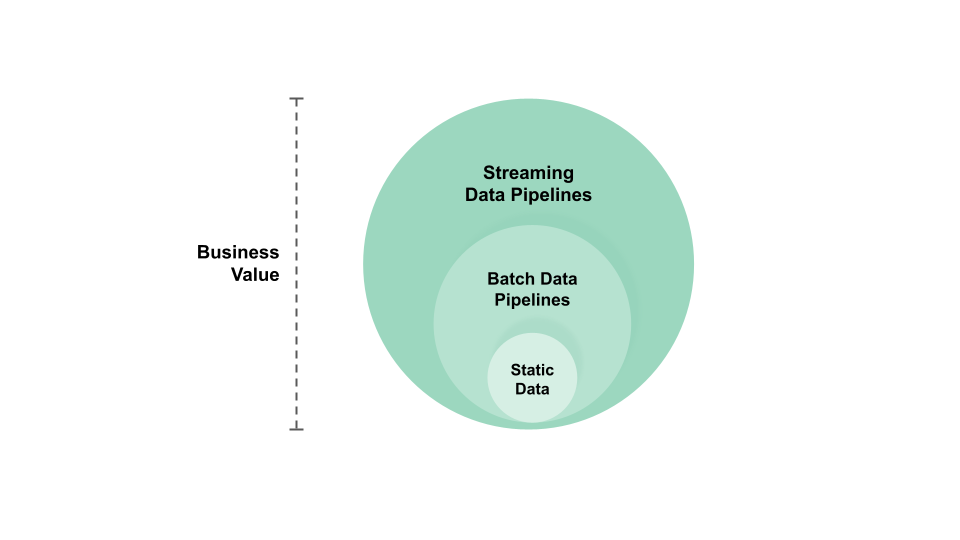
Data pipelines are orchestrated programs that move data from one system to another while also performing transformations on the data either before it has been copied to the target system (ELT) or after it has been copied (ETL). Data pipelines are a key building block in data engineering, as they enable data to flow from operational databases, where the data is generated, to analytical data warehouses, lakehouses, and data lakes where the data is analyzed and used for machine learning. The primary goal of a data pipeline is to automate and streamline the data flow, making it more efficient and reliable.
Without data pipelines (i.e., batch or streaming feature pipelines) machine learning systems can only work on static data and a model cannot be automated to generate value through automating predictions on new (inference) data. Compared to batch data pipelines, streaming data pipelines can produce fresher data (features), which is important for real-time ML.