Two-Tower Embedding Model
The two-tower (or twin-tower) embedding model is a model training method for connecting embeddings in two different modalities by placing both modalities in the same vector space. For example, a two-tower model could generate embeddings of both images and text in the same vector space. Personalized recommendation systems often use items and user-histories as the two different modalities. The modalities need to be “grounded”. For example, image and text can be “grounded” by creating training data where a caption matches an image. Two-tower models are able to map embeddings from different modalities into the same space by ensuring both modalities have the same dimension “d”. For example, if the item embedding is of length 100, then the query embedding dimension should be 100.
Personalized recommendations for Products - Linking Two Modalities
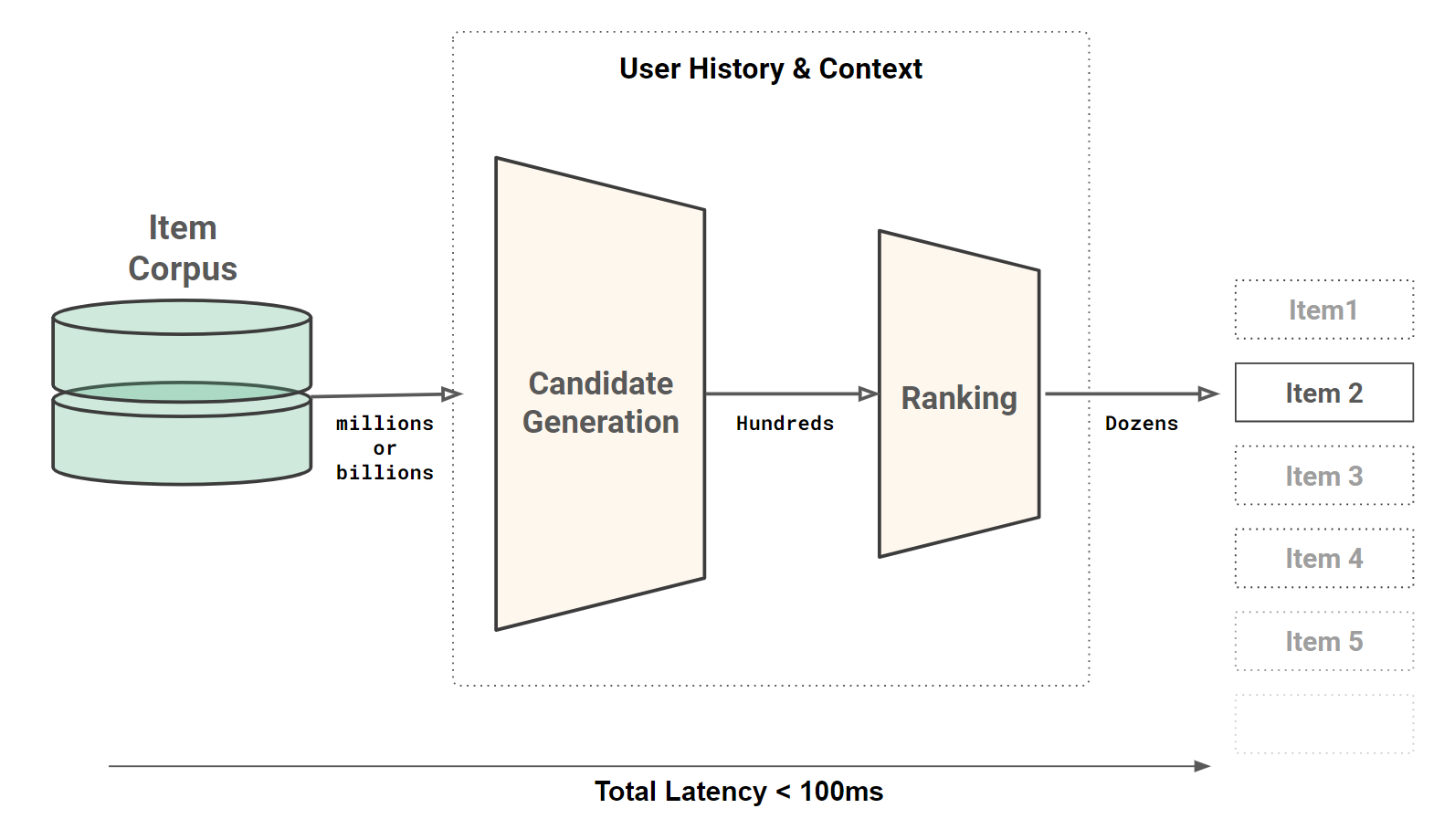
The two-tower model for personalized recommendations combines two items and “user history and context”. That is, given user history and context, can we generate hundreds of candidate items from a corpus of millions or billions of items? Given, those hundreds of candidates, can personalize the ranking of the candidates to the user’s history and context (e.g., items that are trending)?
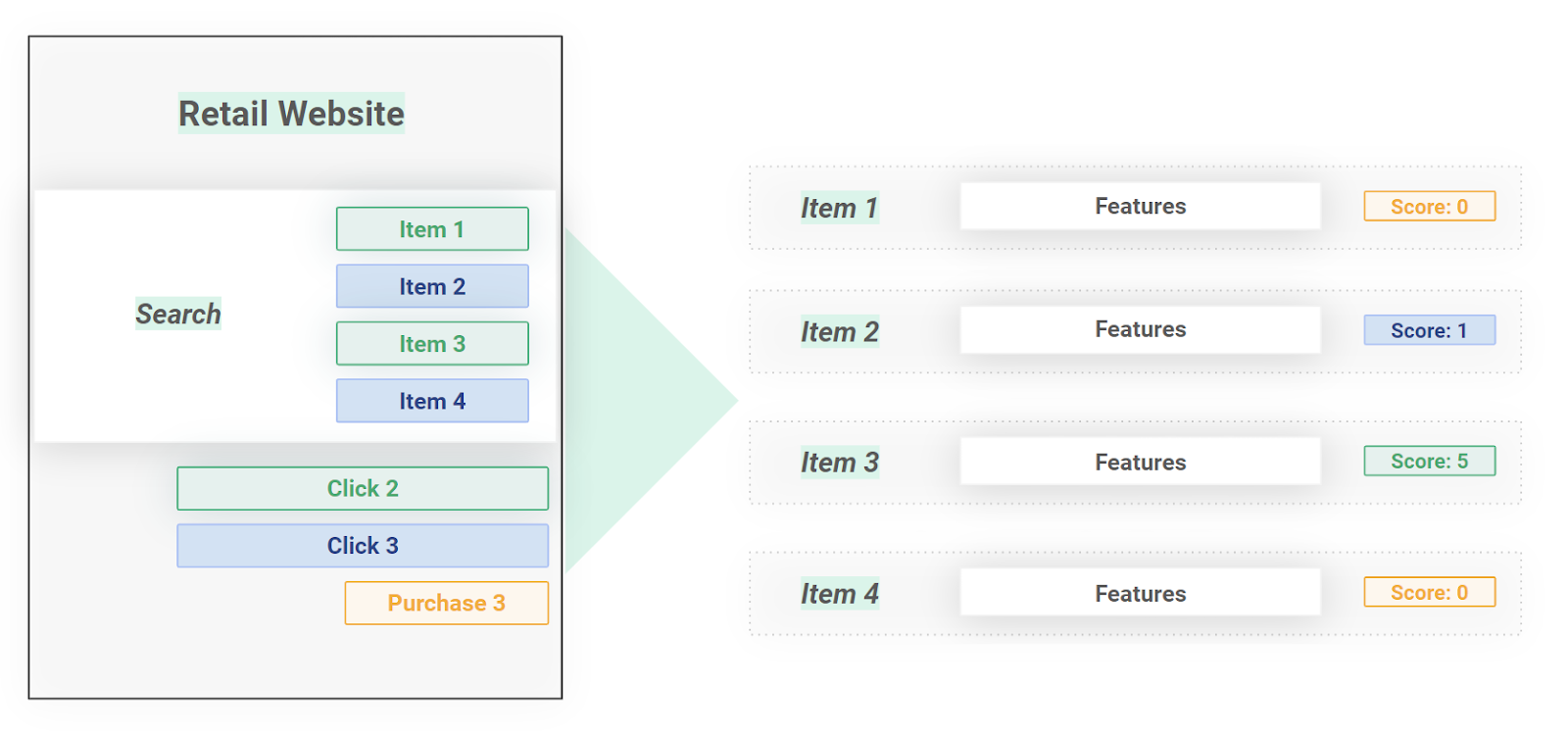
We can create training data for our personalized recommender system that combines the two modalities by presenting items in response to the user query. The user may click on some item, purchase another item, place another item in a shopping cart, and not click on another item. We collect training samples as the combination of the item, a score for the user's action (0=not clicked, 5=purchased, 1=clicked), and the user’s query, user history, and context.
What is a two-tower embedding model architecture?
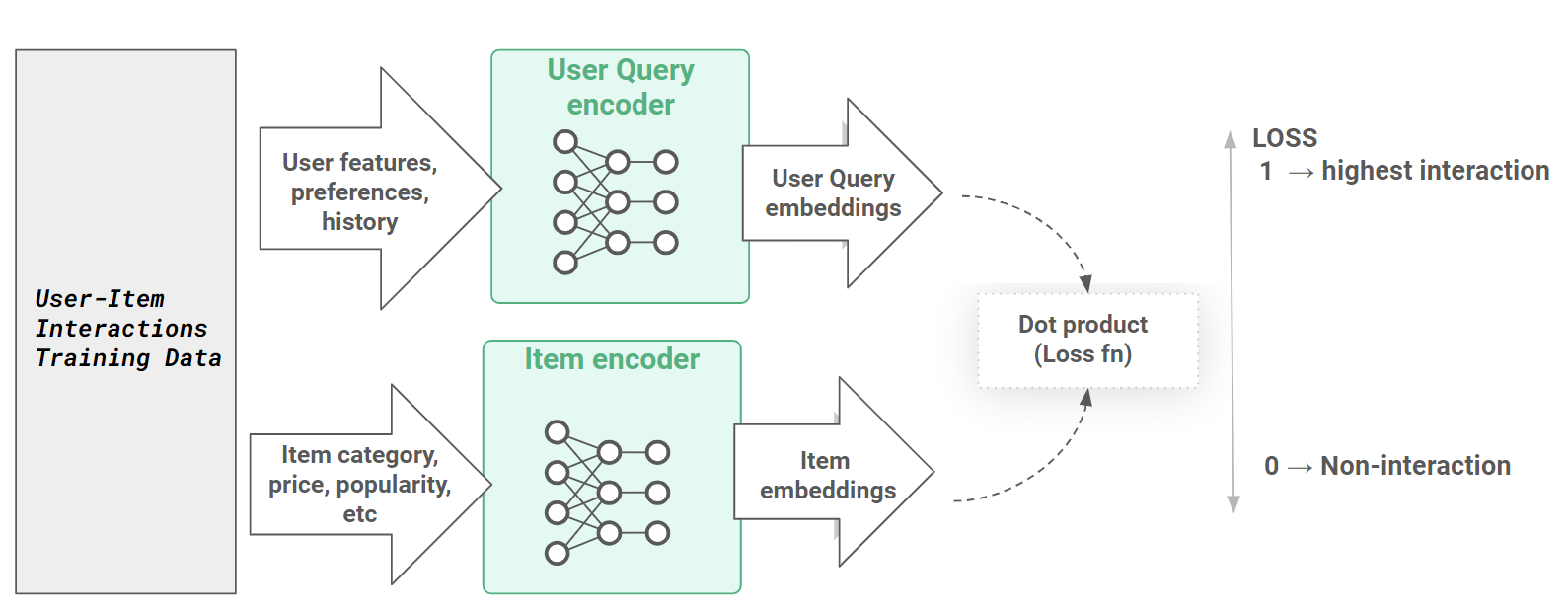
Most two-tower architectures are used for personalized search/recommendations, where you have queries and items as the two modalities. In this case, the two-tower embedding model architecture is a deep learning model architecture that consists of a query tower and an item tower. The query tower encodes search query and user profile to query embeddings, and the item tower encodes the item, store, and location features to item embeddings.
The probability of a user query resulting in an item being clicked or placed in a shopping cart is computed using a distance measure (such as the dot product, cosine similarity, Euclidean distance, or Hadamard product) between the embeddings from two towers. The query and item tower models are trained jointly on the history of user queries and item interactions.
Personalized Recommendations/Search with Hopsworks
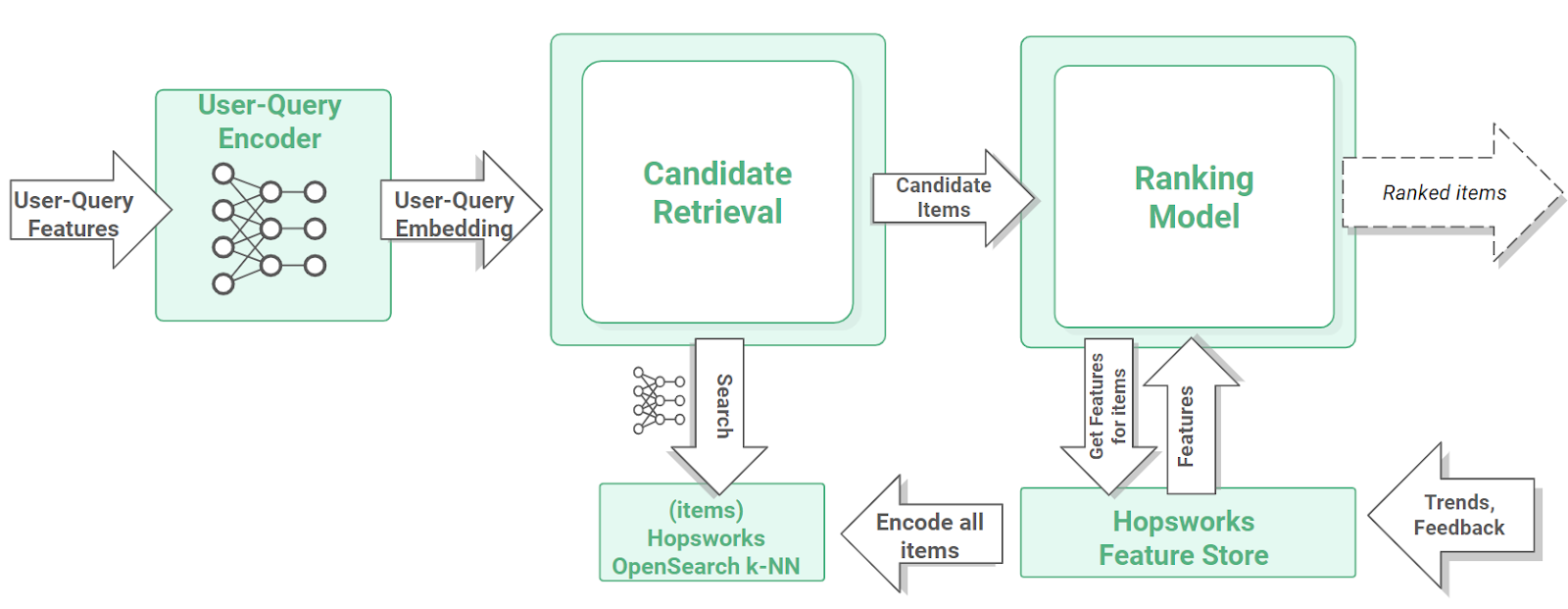
You can use the Hopsworks platform to manage the collection and usage of feature data when building two-tower models. Hopsworks includes a feature store, model registry, and vector database, providing both the online services needed to collect and manage training data, and the online infrastructure for candidate retrieval (VectorDB) and personalized ranking (feature store).
What other types of applications use the twin-tower model architecture?
Bytedance used test/images with ALBERT and Vision transformer twin-tower model architecture. Another example is the TextGNN Architecture that uses the two tower structure for decoupled generation of query/keyword embeddings
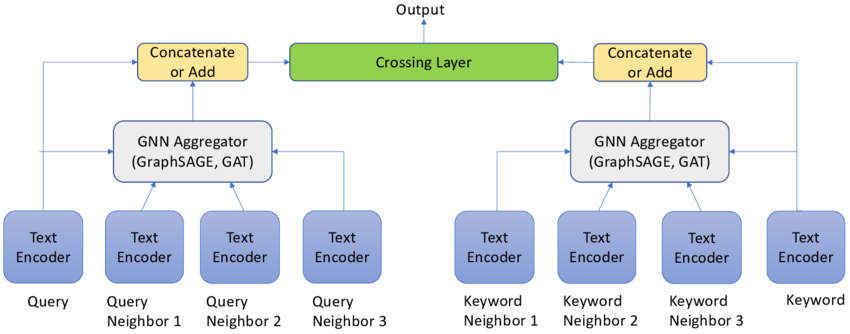
Image from TextGNN: Improving Text Encoder via Graph Neural Network in Sponsored Search by Zhu et al - https://arxiv.org/abs/2101.06323
Spotify have used Graph embeddings in combination with a two-tower embedding model to build a personalized recommendation system for audio books - "unlike music andpodcasts, audiobooks, initially available for a fee, cannot be easilyskimmed before purchase, posing higher stakes for the relevanceof recommendations" [De Nadai et al]
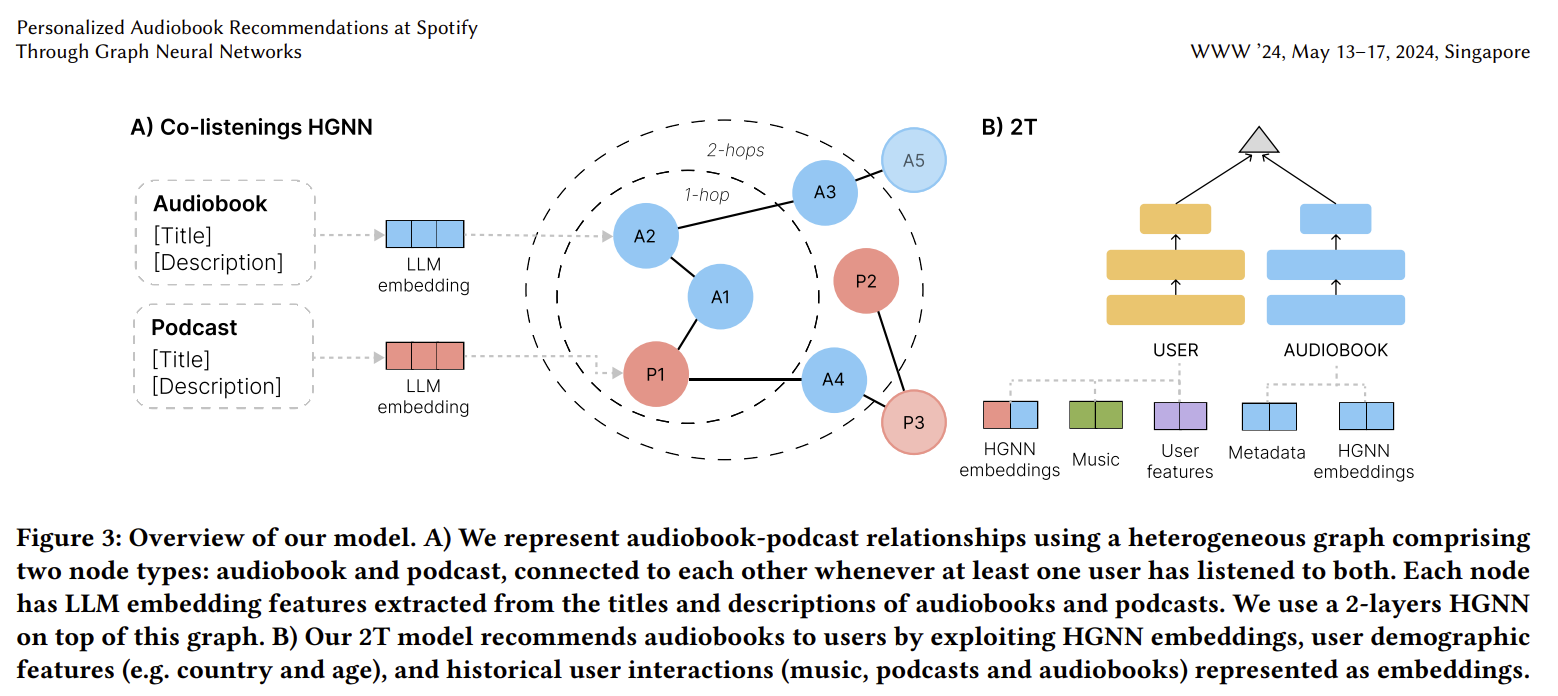
Image from Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks by De Nadai et al - https://arxiv.org/pdf/2403.05185.pdf
Can two-tower embedding models be extended to more modalities?
A two-tower embedding model connects vectors in only two different modalities. Research is ongoing in generalizing to 3 modalities or more. Multi-modal models trained as N-tower embedding models could potentially connect vectors from N different modalities.
Resources
Our research paper, "The Hopsworks Feature Store for Machine Learning", is the first feature store to appear at the top-tier database or systems conference SIGMOD 2024. This article series is describing in lay terms concepts and results from this study.
- Part 1: Modularity & Composability for AI Systems
- Part 2: The Taxonomy for Data Transformations in AI Systems
- Part 3: Use all features: Snowflake Schema
- Part 4: The Feature Store Makes Your Data Warehouse Easy to Use for AI
- Part 5: From Lakehouse to AI Lakehouse with a Python-Native Query Engine
- Part 6: RonDB: A Real-Time Database for Real-Time AI Systems
- Part 7: Reproducible Data for the AI Lakehouse