Machine Learning Infrastructure
What is Machine Learning Infrastructure?
In software development, infrastructure typically refers to the underlying framework, systems, and resources required to support the development, deployment, and operation of software applications. This includes hardware components, such as servers, storage devices, and networking equipment, as well as software components such as operating systems, databases, web servers, and middleware. For machine learning (ML) systems or application development, specialized infrastructure is often required to tailor the needs of handling large amounts of data, training, deploying, and serving machine Learning ML models. This is where machine learning infrastructure comes to the rescue.
Machine learning infrastructure is built upon the traditional hardware & software infrastructure with specific adjustments for ML applications. It encompasses the hardware, software, and operational practices required to support the entire ML lifecycle. From data ingestion and preprocessing of data to model training, deployment, and inference, a well-designed machine learning infrastructure streamlines each process stage, maximizing efficiency and performance.
What are the Key Components of Machine Learning Infrastructure?
ML systems do not just encompass the development of ML algorithms and building ML models. Data quality, training resources, deployment configurations, and continuous monitoring all play critical roles in ensuring the success of an ML project. As the following figure demonstrates, in real-world ML systems, only a small fraction of the life cycle is composed of the ML code.
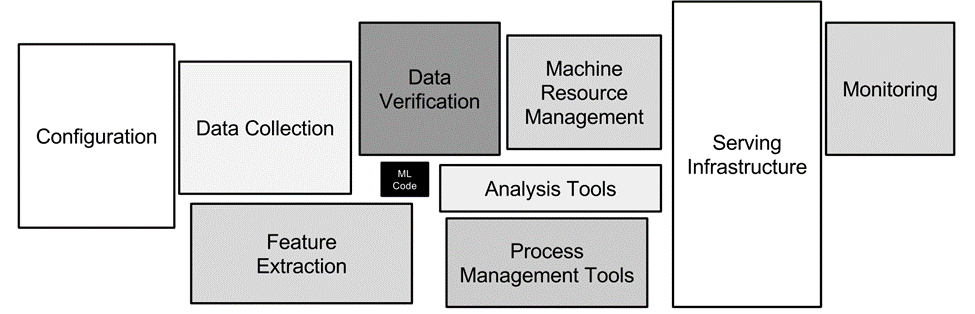
Figure 1: Image showing that ML code is only a small part of the ML system (figure comes from paper “Hidden Technical Debt in Machine Learning Systems” by Sculley et. al. ).
To address the specific needs of ML systems, a robust and scalable machine learning infrastructure can be built to support ML development. Typical ML infrastructures consist of the following key components:
Data Infrastructure
High-quality data is one of the most critical aspects of ML systems. Machine learning infrastructure includes the systems and processes for data collection, storage, preprocessing, feature engineering, data versioning, accessing, and management, such as data lakes, feature stores, data warehouses, and data management tools that can be built on top of private repositories or cloud storage. For example, Data Version Control or DVC is an open-source version control system for data, models, and pipelines. A feature store is a data platform that manages the storage and efficient querying of feature data throughout feature engineering, model training, and inference.
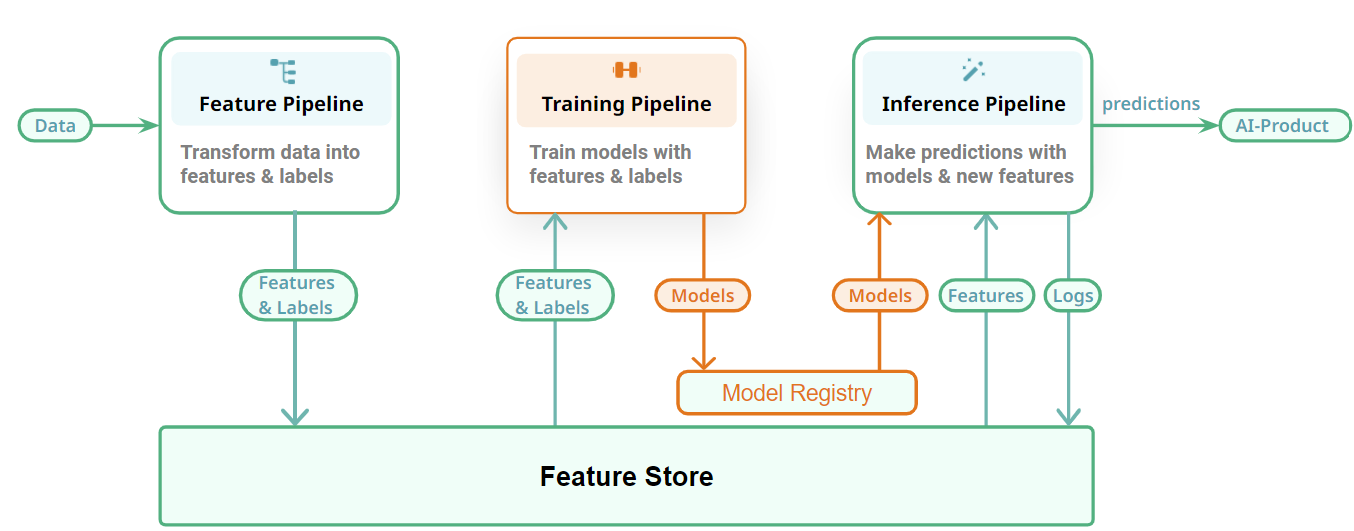
Figure 2: Example of a feature store - Hopsworks.
It is also worth noting that protecting sensitive data and ensuring regulatory compliance are paramount in ML applications. Machine learning infrastructure for data should incorporate robust security measures, including access controls, encryption, and compliance frameworks, to safeguard data privacy and mitigate risks.
Model training infrastructure
Training complex machine learning models demands substantial computational resources. It is important for machine learning infrastructure to incorporate specialized hardware accelerators such as GPUs (Graphics Processing Units) or TPUs (Tensor Processing Units). GPUs excel at handling thousands of smaller tasks simultaneously, making them well-suited for the matrix and vector operations common in deep learning algorithms. TPUs are custom-designed ASICs (Application-Specific Integrated Circuits) optimized for tensor operations, which are fundamental to many deep-learning algorithms.
In addition to GPUs and TPUs, scalable computational resources provide the ability to provision computing power dynamically to meet the demands of ML workloads. This scalability can be achieved through cloud computing platforms, which offer on-demand access to virtualized computational resources such as virtual machines (VMs) or containers. Another example is distributed computing capabilities, especially when training deep neural networks or on massive datasets. Infrastructure frameworks like Apache Spark enable parallel processing and distributed training, accelerating model development while optimizing resource utilization. By leveraging scalable computational resources, the infrastructure capacity can be adjusted in real-time and utilized more optimally, ensuring performance and cost efficiency.
Model deployment and serving infrastructure
Once trained, ML models, along with other components in the applications, need to be deployed in production environments to serve real-time predictions. ML infrastructure for model deployment, including packaging, versioning, deploying, and serving, often leverages containerization technologies (e.g., Docker, Kubernetes) and serverless computing platforms to ensure scalability, reliability, and efficient resource utilization.
Dedicated model serving frameworks, such as TensorFlow Serving and PyTorch Serve, provide specialized infrastructure for deploying and serving ML models in production. These frameworks offer features such as model versioning and traffic routing, allowing multiple applications to access the same ML model and facilitating the deployment of models at scale with minimal overhead.
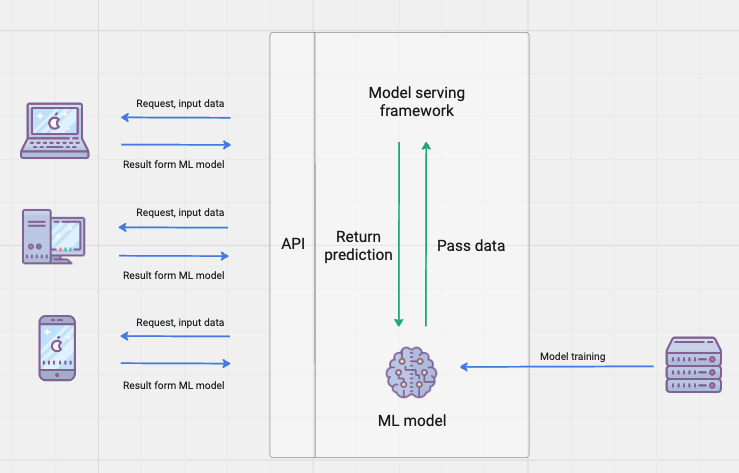
Figure 3: An illustration of ML serving
Model Monitoring and Observability
Continuous monitoring of model performance is essential for detecting anomalies, optimizing resource allocation, ensuring reliability, and enabling continuous improvement. ML infrastructure for monitoring integrates with logging frameworks, metrics tracking tools, and anomaly detection systems, providing actionable insights to ML developers.
Monitoring for model drift detection is another essential aspect of maintaining the performance and reliability of ML models in production environments. Model drift refers to the phenomenon where the statistical properties of the data used for model training and the data encountered in the real world diverge over time, leading to degradation in model performance.
What are the Best Practices for Machine Learning Infrastructure?
Effective machine learning infrastructure relies on modularity and flexibility. Modular design involves breaking down complex infrastructure systems into smaller, reusable components or modules. Each module serves a specific function and can be included, upgraded, or replaced without affecting the whole system. This approach promotes flexibility and agility, allowing developers to adapt their infrastructure to changing requirements and technologies.
Another aspect to consider when designing machine learning infrastructures is automation. Automated model lifecycle management will simplify the deployment, monitoring, and optimization of ML models, reducing the burden on ML teams. Automation that streamlines the ML development phases also helps reduce manual intervention and minimize human-introduced errors.
By adhering to these best practices, developments can build a robust and agile ML infrastructure capable of supporting the entire ML lifecycle, from development to deployment and beyond.
Summary
Machine learning infrastructure encompasses the hardware, software, and operational practices required to support the entire machine learning lifecycle, including components such as data storage and management systems, computational resources for training and inference, model deployment and serving platforms, and monitoring tools. Effective machine learning infrastructure prioritizes modularity, flexibility, and automation to adapt to changing requirements and technologies seamlessly.
Machine learning infrastructure is the foundation to build and scale ML applications. By investing in a robust and comprehensive ML infrastructure, developers can unlock more potential for ML. By staying informed about the latest trends and best practices, and by continuously optimizing and evolving their ML infrastructure, developers can position themselves for long-term success in the rapidly changing ML technological landscape.