Retrieval Augmented Generation (RAG) for LLMs
What is Retrieval Augmented Generation (RAG) for LLMs?
Retrieval-augmented generation (RAG) for large language models (LLMs) aims to improve prediction quality by using an external datastore at inference time to build a richer prompt that includes some combination of context, history, and recent/relevant knowledge (RAG LLMs). RAG LLMs can outperform LLMs without retrieval by a large margin with much fewer parameters, and they can update their knowledge by replacing their retrieval corpora, and provide citations for users to easily verify and evaluate the predictions.
The most common systems used to provide external data for RAG LLMs are vector databases and feature stores. RAG for LLMs works because of the ability of LLMs to perform in-context learning.
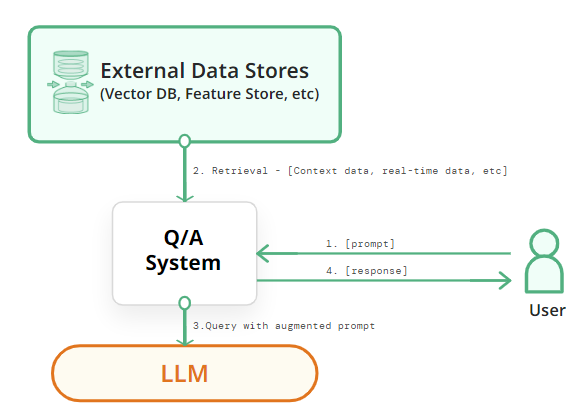
RAG for LLMs
RAG integrates information retrieval (or searching) into LLM text generation. It uses the user input prompt to retrieve external “context” information from a data store that is then included with the user-entered prompt to build a richer prompt containing context information that otherwise would not have been available to the LLM. Some examples of context information used by RAG include:
- real-time context (the weather, your location, etc);
- user-specific information (orders the user has made at this website, actions the user has taken on the website, the user’s status, etc);
- relevant factual information (documents not included in the LLM’s training data - either because they are private or they were updated after the LLM was trained).
Why is there a need for RAG LLMs?
Pre-trained LLMs (foundation models) do not learn over time, often hallucinate, and may leak private data from the training corpus. To overcome these limitations, there has been growing interest in retrieval-augmented generation which incorporate a vector database and/or feature store with their LLM to provide context to prompts, also known as RAG LLMs.
What data systems are used for RAG LLMs?
Vector databases are used to retrieve relevant documents using similarity search. Vector databases can be standalone or embedded with the LLM application (e.g., Chroma embedded vector database). When structured (tabular) data is needed, an operational data store, such as a feature store, is typically used. Popular vector databases and feature stores are Weaviate and Hopsworks that both provide time-unlimited free tiers.
How does RAG compare with Fine-Tuning?
Fine-tuning takes a pre-trained LLM and further trains the model on a smaller dataset, often with data not previously used to train the LLM, to improve the LLM’s performance for a particular task.
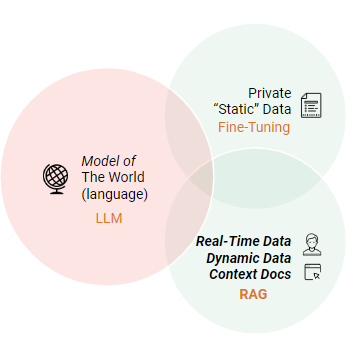
LLMs can be extended with both RAG and Fine-Tuning
In the above figure, we can see that fine-tuning is appropriate when you want to customize a LLM to perform well in a particular domain using private data. For example, you can fine-tune a LLM to become better at producing Python programs by further training the LLM on high-quality Python source code.
In contrast, you should use RAG when you are able to augment your LLM prompt with data that was not known to your LLM at the time of training, such as real-time data, personal (user) data, or context information useful for the prompt.
Challenges with RAG
One of the challenges in using a vector database is the stochastic nature of similarity search - how do you know the document you retrieve is actually relevant for the prompt?

LLM Question-Answering System using RAG (feature store and vector database) as well as Fine-Tuning
In contrast, using structured data in RAG, such as in the example above is quite straightforward. In this figure, the user has logged onto the website, so we have the user’s ID. With the user’s ID, we can retrieve the customer’s recent investments as a list of strings that we prepend to the prompt. In the above figure, looking up the relevant document in a vector database to the user’s concern about “rising interest rates affects property” is more challenging. If you query the vector database with “rising interest rates affects”, it has a good chance of returning a relevant document, but if you include “property” in your vector database query, it may return a document related to property, which is not the context we would like to provide to steer the conversation towards other investment opportunities.
Efficiency and Scaling in RAG LLM Systems
Scaling RAG LLM systems efficiently in large enterprises or production environments presents a unique set of challenges. With the increasing size of external data sources and user queries, maintaining high-quality, low-latency responses requires both architectural innovations and resource optimization.
Cloud-based infrastructure, such as Kubernetes or serverless architecture, enables on-demand scaling of RAG LLM systems. For instance, platforms like Pinecone or Hopsworks provide dynamic scalability, allowing organizations to adjust their compute and memory resources based on real-time demand. This elasticity is particularly important for businesses with fluctuating workloads, as it optimizes resource allocation and cost efficiency.
The Evolution of RAG LLMs
Hybrid Retrieval Models
As RAG for LLM systems evolve, hybrid retrieval models are gaining traction by combining dense neural retrieval with traditional keyword-based search. This hybrid approach improves the reliability and precision of retrieving relevant documents, balancing the strengths of semantic similarity with exact keyword matches.
Multimodal RAG
The next frontier of RAG LLMs involves multimodal RAG systems, where LLMs can retrieve not only text but also images, videos, and structured data. This approach enhances applications across sectors, including healthcare, autonomous vehicles, and retail, by enabling systems to synthesize diverse information sources for richer, contextually relevant outputs.
Resources for RAG LLMs
If you want to learn more about RAG LLMs, check out these blogs and tutorials showcasing how to use RAG LLMs with a feature store for ML applications.
- Unlocking the Power of Function Calling with LLMs
- Build Your Own pdf ai: Using both RAG and Fine-Tuning in one Platform
Our research paper, "The Hopsworks Feature Store for Machine Learning", is the first feature store to appear at the top-tier database or systems conference SIGMOD 2024. This article series is describing in lay terms concepts and results from this study.
- Part 1: Modularity & Composability for AI Systems
- Part 2: The Taxonomy for Data Transformations in AI Systems
- Part 3: Use all features: Snowflake Schema
- Part 4: The Feature Store Makes Your Data Warehouse Easy to Use for AI
- Part 5: From Lakehouse to AI Lakehouse with a Python-Native Query Engine
- Part 6: RonDB: A Real-Time Database for Real-Time AI Systems
- Part 7: Reproducible Data for the AI Lakehouse