The Feature Store Makes Your Data Warehouse Easy to Use for AI
The feature store gives Data Scientists superpowers in data modeling and temporal querying of time-series data
In this article, we cover the added value of a feature store over a data warehouse when managing offline data for AI.

Trigger warning - this article is written primarily for data engineers, data architects, and ML engineers who have responsibility for providing data to data science teams and are curious if their data warehouse or lakehouse can be their feature store or not.
This article is part 4 in a 7 part series describing in lay terms concepts and results from a SIGMOD 2024 research paper on the Hopsworks Feature Store.
Other Parts: 1 (Modular/Composable AI Systems) , 2 (The Taxonomy for Data Transformations), 3 (Use all features: Snowflake Schema), 4 (Lakehouse for AI), 5 (From Lakehouse to AI Lakehouse), 6 (Real-Time AI Database), 7 (Reproducible Data).
Introduction
Feature stores have reached a level of maturity where a Data Scientist, without SQL or data modeling skills, can create, maintain, and query fact and dimension tables containing time-series data in a data warehouse or lakehouse and easily run temporal queries to read point-in-time correct data for model training and inference. Despite this, we often hear that a feature store is just a lakehouse if you don’t use its low latency online feature serving capability. In this article, we will show how the feature store is an easy to use layer on top of your data warehouse or lakehouse with specific support for the subset of slowly changing types from dimension modeling that are relevant for AI. We will show how the complex temporal joins that are required to read data for both training and inference (without any future data leakage or stale data) are made accessible to data scientists working in Python using intuitive APIs. We also introduce the two main abstractions in feature stores, feature groups and feature views, and how they enforce the desired data model. In the next article in this series, we show you how our feature store addresses another problem with using an existing data warehouse for AI - slow throughput in reading data to Python clients.
The Data Warehouse/Lakehouse as a Feature Store
You are a data engineer or data architect and one of your responsibilities is architecting the data model for your bronze, silver, and gold tables. Your goal is to create data marts that are easy to maintain and to support high performance (and, hopefully, low cost) queries for dashboards and analysts. Your bronze layer is a landing layer for ELT (or ETL) pipelines. You use a Data Vault data model for your silver layer due to its flexibility. For your gold layer, where possible, you use Snowflake Schema data models for easier maintenance and flat tables when you need low latency queries for selected use cases. You manage a reasonable number of business fact tables, and a larger number of tables that store dimensions for those facts. You have a mixture of immutable and mutable data in your dimension tables. You put your immutable dimensions in Type 0 slowly changing dimension (SCD) tables, and your mutable time-series data in Type 2 SCD tables.
One data science team is asking you to make some of the warehouse data available in a low latency database for an online AI-enabled application, but that will happen at some far off time in the future. Right now, however, your focus is the data scientists who want to use your data (or features as they call it) to train their machine learning models.
They want to use an existing fact table (sales stores by day) as labels for a supervised machine learning model that will predict revenue for the coming quarter. From that fact table, they want to compute aggregate features (sum, max, average, etc) over time windows (a given hour, day, week or month) from the fact tables. It’s easiest to do this in DBT/SQL, so they go ahead and learn to write SQL in DBT.
They also want to include columns from the Type 2 SCD tables about marketing activities and special offers. They also have 3rd party data relating to holidays, the consumer price index, and inflation expectations. You explain that the Type 2 SCD tables have an entity identifier (a primary key) and one timestamp column that indicates when the values in that row became valid and a second timestamp column that indicates when the row values ceased to be valid. In turn, the data scientists explain to you the potential problem of future data leakage and the stale data problem - if they join columns from a dimension table with the fact table rows and the dimension table row values are not valid at the time the fact value was measured, it will negatively affect their models. Luckily, the fact table includes a timestamp column, the event time, and for every row in the fact table, they can join the selected columns from the different dimension tables using their two timestamp columns.
This will be a tough query. After a bit of research, you discover that an ASOF JOIN will perform the required temporal query. You propose an INNER JOIN, but the data scientists complained that even if values are missing from the dimension tables, you want to include the fact rows, because they can later input a value for any missing data from the joined column(s). So, instead, you use an ASOF LEFT (OUTER) JOIN to join the (feature) columns in with the (label) facts, producing training data for a supervised machine learning model. You are using Databricks/Redshift as your lakehouse, but, unfortunately, it doesn’t support ASOF LEFT JOINs. So, you figure out you can implement an ASOF LEFT JOIN with a state table and a lot of SQL. However, your existing fact table only includes the event_time for when the event happened, so you will also need to create a state table that contains both the start and end time for when the event was valid. That is a huge amount of work. Are your data scientists expected to be able to write these complex ASOF LEFT JOIN queries or build state tables to generate point-in-time correct training data? What happens when they want to add new columns, remove columns, run these queries on a schedule and create new tables in my data warehouse? There’s gotta be an easier way to do this. Enter the feature store.
The Hopsworks Feature Store
The Hopsworks feature store is both a lakehouse for data for AI as well as an operational database for serving feature data at low latency and high throughput to online AI applications.
Hopsworks works with your existing data warehouse or lakehouse, without unnecessary copying of data from the data warehouse to the feature store. If you have a lakehouse, Hopsworks stores its offline tables in either Apache Hudi or Delta Lake table formats (Iceberg support coming soon). Existing tables in your data warehouse or lakehouse can be mounted as external feature groups in Hopsworks (with no data copying). You can even push down SQL queries to compute features on-read from your data warehouse with an external feature group.
External feature groups, or direct access to the source data, gives your data scientists visibility over available data and the ability to create new features and use existing tables as features. Features computed from the source table(s) (and potentially other data sources) can be stored as feature groups in Hopsworks - either in Delta Lake or Apache Hudi tables. Data scientists don’t have to open a ticket to create a new table in the data warehouse - you only need to give them read privileges for selected tables in the data warehouse.
But what about dimension modeling and the ASOF LEFT JOINs? To explain how Hopsworks simplifies reading point-in-time correct data for training and inference, we need to first define feature groups and feature views.
A feature group consists of a schema, metadata, a Delta or Hudi table to store historical feature data, optionally a table in RonDB (row-oriented, in-memory database) to store the latest feature values for online serving, and an optional vector index for similarity search. An external feature group is the same as a feature group, but uses an existing table in an external data warehouse instead of the Hudi/Delta table in Hopsworks.
The metadata typically contains the feature group’s:
- name
- version (a number)
- entity_id (primary key)
- online_enabled status - if a table in RonDB is used for online feature serving
- event_time column (optional)
- tags for feature discovery/reuse and governance
- a partition_key column (used for faster queries through partition pruning)
- foreign_key columns (references to a primary key in another feature group)
- embedding columns that should be indexed for similarity search.
The entity_id is needed to retrieve rows of online feature data and prevent duplicate data, while the version number is the table (or schema) version. A new feature group version creates a new table. You need a new version for schema breaking changes and support for A/B tests of different versions of features by different models. The event_time column is needed to create point-in-time consistent feature data. While foreign keys are supported to implement data models (like a Star Schema or Snowflake Schema data model). Foreign key constraints (like ON DELETE CASCADE) are not supported.
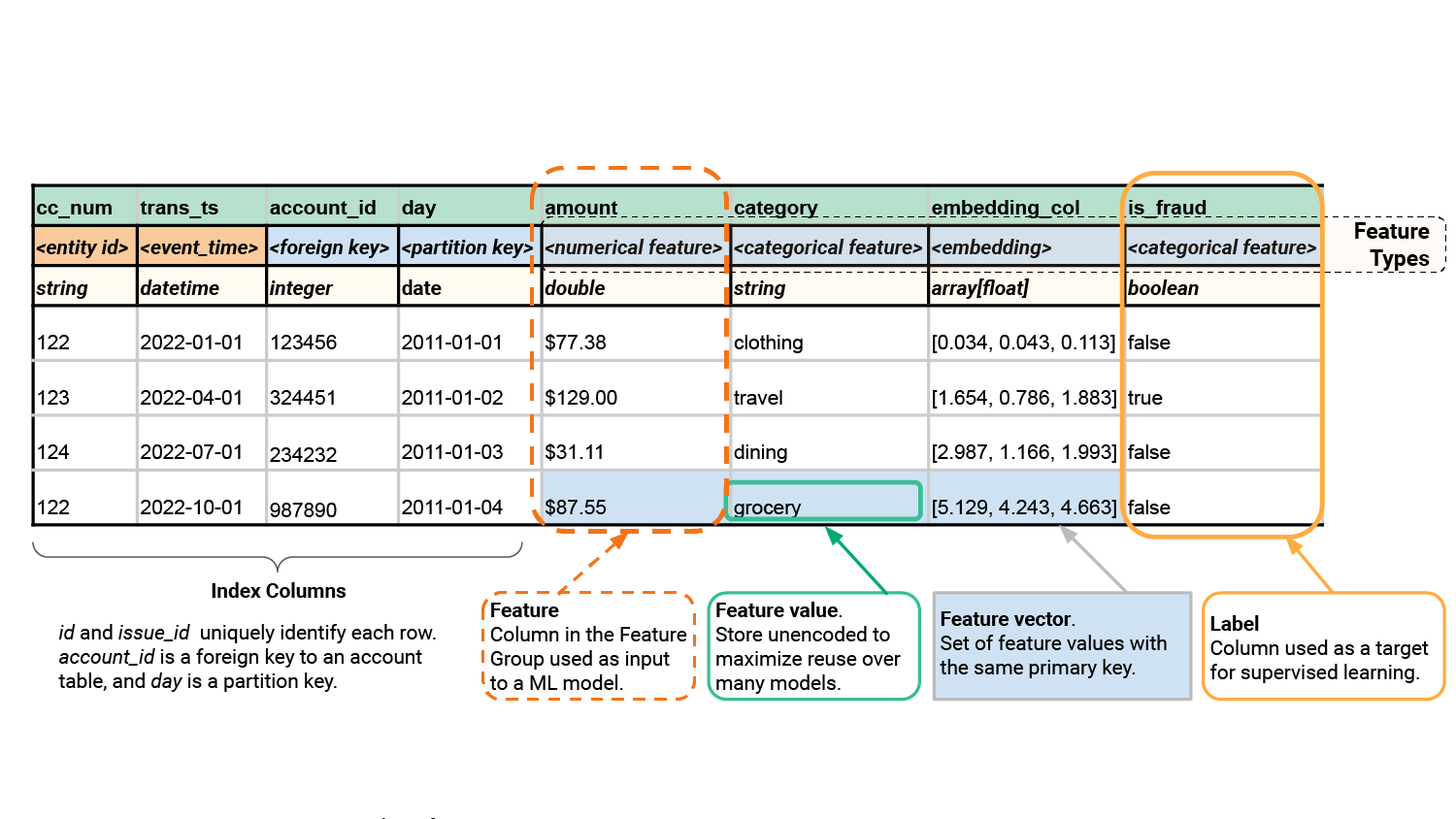
Figure 1: Rows are uniquely identified with a combination of the entity ID and the event_time. You can have a foreign key that points to a row in a different feature group, and a partition key, used for push-down filters for faster queries. The index columns are not features.
Feature Pipelines as ETL Jobs
Data scientists typically prefer to work with DataFrames, in frameworks such as Pandas, Polars, and PySpark. Hopsworks makes it easy for them to (1) create feature groups (optionally taking the schema from the DataFrame), and (2) upsert the DataFrames into tables. This enables them to easily write feature pipelines that append/update/delete data from feature group tables.
For example, to define the feature group from figure 1 and write data into it, a Data Scientist typically writes code that looks as follows:
With their favorite language (Python) and favorite feature engineering framework (DataFrames), our data scientist has implemented an ETL (extract, transform, load) pipeline in PySpark/Pandas/Polars that writes to a Type 2 SCD table as a feature group. They needed to define a primary key and the event time column. Here, feature values (dimensions) can change over time - multiple rows can have the same primary key, but with a different timestamp value. Note that feature values do not need a 2nd timestamp column indicating when a feature value ceases to be valid as feature values are strictly non overlapping - a feature is a measurement and cannot have two measurements that are both valid at the same point in time.
Let us consider a different feature pipeline. This time our data scientist wants to import immutable data into a feature group. In this case, they do not include an event_time column in the feature group definition. Now, implicitly they implemented a Type 0 SCD table.
If our data scientist progresses to building real-time AI applications and needs an online table for the feature group, they specify online_enabled=True when creating the feature group. That will store all the historical feature value observations in the offline lakehouse table and the latest feature values in the online RonDB table. This is, in fact, a Type 4 SCD table (with the twist that the latest observations are stored in a table in a different database from your data warehouse). The support for the different SCD Types in our feature store is summarized in table 1.Q§

Table 1: Feature stores implement variants of SCD Types 0, 2, and 4. Type 0 is for immutable feature data. Type 2 is for mutable feature data used by batch ML systems. Type 4 is for real-time ML systems that use the online table for real-time context and the offline table to create training data.
Once our feature groups contain useful data, our data scientists will need to perform temporal joins on the feature groups to create point-in-time consistent training data. First, in Hopsworks, data scientists should select the features that they want to include in the model they are building. This can be done in Python code by selecting features from different feature groups, joining them together (using foreign keys), and then creating a feature view to represent the selected features. The feature view stores the model schema including the input features and the output - the label columns defined in the feature view. The feature view is just metadata and does not store any actual data. A Python code snippet to select the features and create a feature view is shown below:
The feature view serves a few useful purposes in Hopsworks. Firstly, it prevents skew between training and inference by providing a shared schema for the features/labels used by the model. It also transpiles Python code into SQL queries that are executed by one of the query services - either the Hopsworks Query Service (powered by DuckDB and ArrowFlight), for data volumes that can be stored on a single server, or Spark for larger volumes of data that are output as files.
The feature view can be used to create point-in-time correct training data as DataFrames or files using API calls as follows:
The above code snippets implements a ASOF LEFT (OUTER) JOIN, as shown in figure 2. The feature view also has convenience methods to split the training data into training, test, and validation sets, supporting random and time-series splitting.
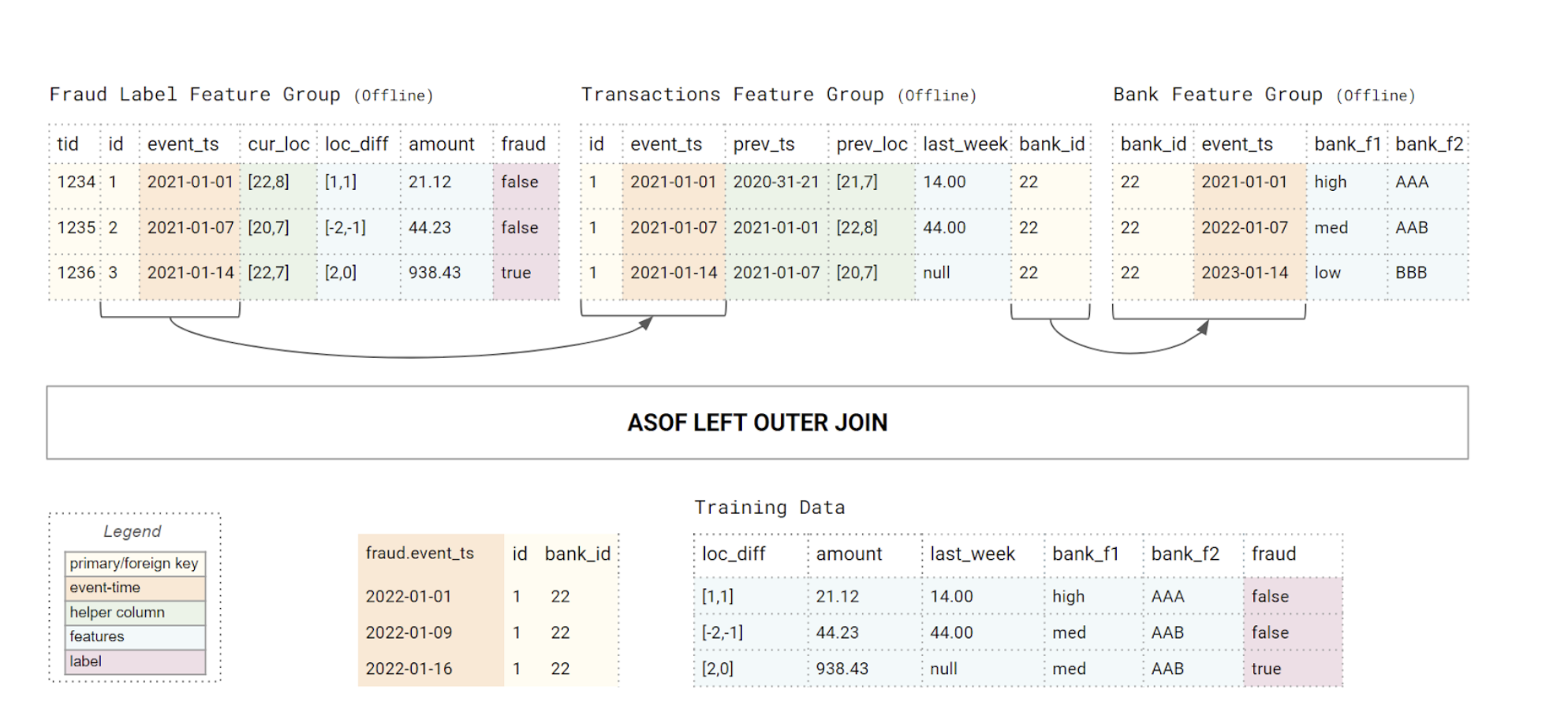
Figure 2: You create training data by starting from the table containing labels (facts) and join columns from other tables using (nested) ASOF LEFT JOINs.
For batch and online inference, you can use the same feature view to read feature data to be scored:
Now, we come to performance. Our data scientists are using Python to read data from the lakehouse tables. That is not a high performance capability of existing data warehouses, that (as of mid-2024), provide mostly JDBC/ODBC APIs for reading to Python clients. Data from the lakehouse will first be read by the JDBC/ODBC server, then transposed from columnar to row format, then serialized, then sent to the Pandas/Polars client that will then deserialize and transpose the data back from row-oriented to columnar format. The whole process introduces large bottlenecks that make using a data warehouse directly from Python often a painful process. There is, however, a more efficient way to query lakehouse data from Python - using Arrow Flight as a transport protocol, instead of JDBC/ODBC, and a columnar database that provides efficient LEFT ASOF JOINS, DuckDB. The next article in this series will examine the performance of reading batches of point-in-time correct data from the feature store.
Conclusions
In this article, we covered the added value of a feature store over a data warehouse when managing offline data for AI. We showed how the Hopsworks Feature Store implements three different SCD types in its feature groups, generates temporal queries from Python code. We wrote this article with the hope that it would help dispel the myth that a feature store is just a shiny data warehouse, and that it can help improve collaboration between your data engineering and data science teams, as well as enable data scientists to do great things with tabular data.