Multi-Region High Availability Comes to Feature Stores
Part 2 - Multi-Region Architecture for Demanding Applications
Following our previous blog, we expand on the architecture to fit a Tier 1 classification where all components of Hopsworks are replicated in a different geographical region.

Introduction
In Part 1 of this article series we explored the components of Hopsworks Feature Store and we analyzed the technologies and techniques providing high availability and fault tolerance to such an important and complicated system.
Whilst for most use cases the architecture we explain in Part 1 would suffice, certain applications require stronger guarantees. These Tier 1 applications are usually involved in the most important hot path of a business and prolonged downtime incur financial loss and regulatory penalties.
In this part we will expand the architecture described previously to fit a Tier 1 classification where all components of Hopsworks are replicated in a different geographical region. A Feature Store is an intricate system consisting of different databases, job schedulers and various microservices. Designing such a system to operate in Active-Active setup is very difficult and would impact performance to achieve strong consistency between the two regions. For this reason we designed each sub-system differently taking advantage of both Active-Active and Active-Passive architectures.
Recap
Before we dive into architectural designs let’s remember the components of Hopsworks Feature Store from Part 1.
In summary the Hopsworks Feature Store consists of three components:
- an offline store for large volumes of historical feature data used for training and for batch predictions,
- an online store for feature data that is read at low latency by online (interactive) AI applications;
- a metadata layer that stores information about the feature store itself, and metadata about the feature data, users, computations, and so on.
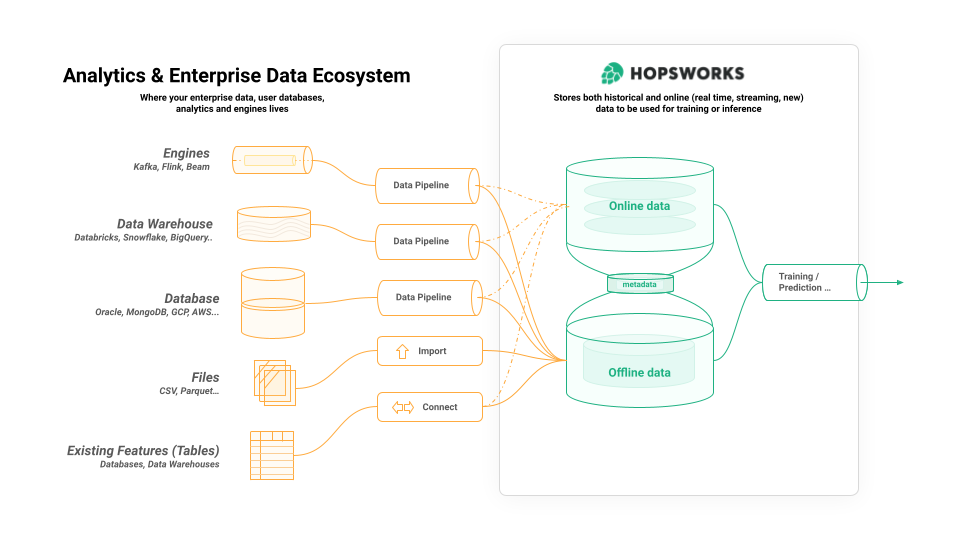
Figure 1: Overview of Hopsworks Feature Store.
In Part 1 we analyzed the HA characteristics of each component separately. We will follow the same principle here but before that we will introduce two more abstractions.
Global Load Balancer
The first new abstraction is a load balancer service which can route traffic in both regions. In Part 1 Hopsworks was running in a single region using our internal Service Discovery system for the different microservices to communicate with each other. Every microservice is configured with its corresponding health check so traffic will be routed only to healthy instances of the same service.
Moving to a multi-region architecture we need a global Load Balancer service which can route traffic to both regions, in case of Active-Active sub-systems, or to the currently active region in case of Active-Passive sub-systems.
Active Cluster Arbitrator
The second abstraction in the Multi-Region architecture is the Active Cluster Arbitrator which is an oracle machine deciding which region is Active and which region is Passive. It is the source of truth for all Active-Passive components as we will see later on.
The only requirement from Hopsworks is that it advertises the active/standby region in the following JSON construct
In its simplest form ACA is an HTTP server serving the current configuration. The JSON response can be configured using GitOps process or any other kind of automation. Obviously, running a single instance of ACA will hinder the availability of the whole system so we must ensure we run multiple instances behind the global load balancer service as depicted in Figure 2.
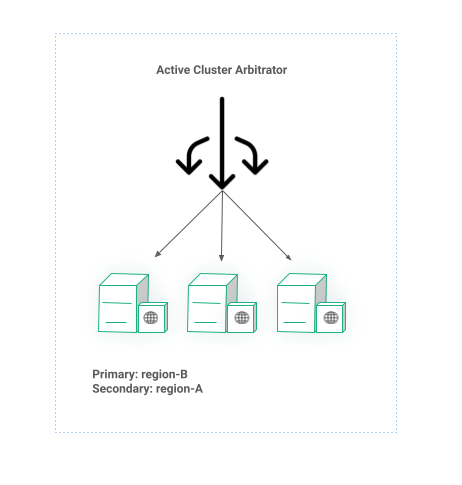
Figure 2: HA Active Cluster Arbitrator
Globally Replicated Metadata Layer
The metadata layer in Hopsworks is the link between the Online and Offline store, it stores feature groups metadata, feature views, users, credentials, HopsFS metadata etc. In Part 1 we explained the resiliency of the underlying database, RonDB, and fault tolerance of the application server.
As explained previously, data stored in RonDB are replicated in multiple datanodes for redundancy. The latency between machines in the same Data Center is negligible and such “pipelining” is possible. Moving to a globally replicated architecture introduces a new challenge, that of increased latency - especially when the second site is geographically far. Performance will drop considerably but also distributed transactions might be randomly aborted due to timeouts in the two-phase commit protocol of RonDB.
RonDB asynchronous replication
This is where asynchronous Global Replication comes into play. Every transaction committed in Region A is asynchronously replicated to Region B. In its simplest form we can have Region A being the active/writer site while Region B being the passive/reader site. In more complex setups both regions can be active with conflict resolution algorithms guarding the consistency of data.
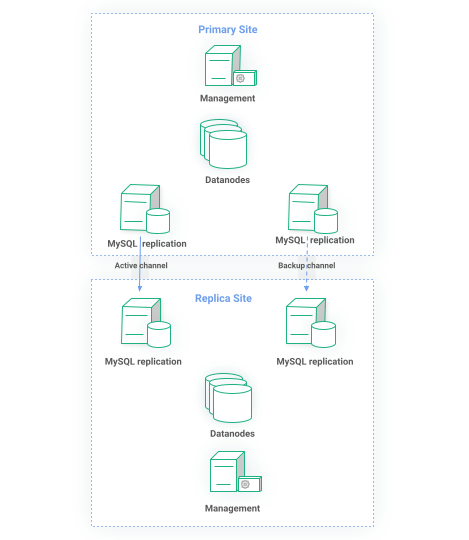
Figure 3: Global replication of RonDB cluster
The replication happens between two designated MySQL servers. Remember that in RonDB MySQL are just lightweight API processes so they come at almost no cost. Every connected MySQL node will receive committed transactions and write them to its binlog. The MySQL server on the Replica site is configured to receive events from the Primary site and consequently apply the transaction. In the example of Figure 3, there are two replication channels. The active is doing the replication while the backup is ready to automatically take over if it detects replication has not made any progress.
The architecture above covers our most demanding use-cases with requirements in high performance and high availability. Quite often high performance is orthogonal to fault tolerance but with this architecture we achieve both by exploiting the benefits of synchronous ACID transactions within the region and asynchronous replication to the replica site. Multiple failures can still be tolerated within the same region but in the event of a catastrophic failure we can always switch to the Metadata Layer in the replica region.
Ubiquitous Hopsworks application
As discussed in Part 1 we are able to run multiple instances of the application server because it is a stateless application, state is stored in RonDB. In a multi-region architecture only one region is Active at a time while the others can exclusively serve read requests. Each instance is aware of the region it is running in. Read requests are always served locally. Write requests in a passive region that modify the global state are transparently redirected to the primary site. Due to the global replication mechanism, changes in state are eventually propagated to the Passive region. A high level architecture of the Metadata layer is shown in Figure 4.
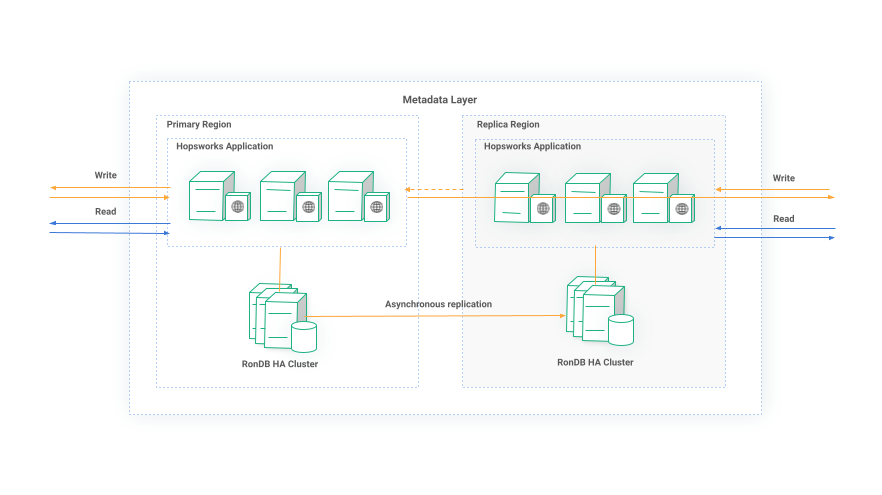
Figure 4: Multi-region Active/Passive Hopsworks Metadata layer
Active-Active Online Store
The Online Feature Store is typically invoked by realtime user-facing applications and as such it has the strictest SLA and it must always have fresh data. We decided to engineer the critical path of the Online feature store in an active-active architecture to fit these requirements and to be able to fail-over instantly. If you remember from Part 1, we run multiple instances of the online feature store microservice for redundancy. These microservices consume messages from Kafka topics and persist them in a RonDB cluster - separate from the Metadata layer.
Often big organizations have a dedicated team to administer Kafka clusters and provide multi-region stretched Kafka topics. If this is not an option we can achieve a similar result with a tool such as Kafka MirrorMaker. The end-goal is to have the same Kafka message be delivered to both regions. The onlinefs microservices will guarantee to store the data in their respective disjointed RonDB clusters as shown in Figure 5.
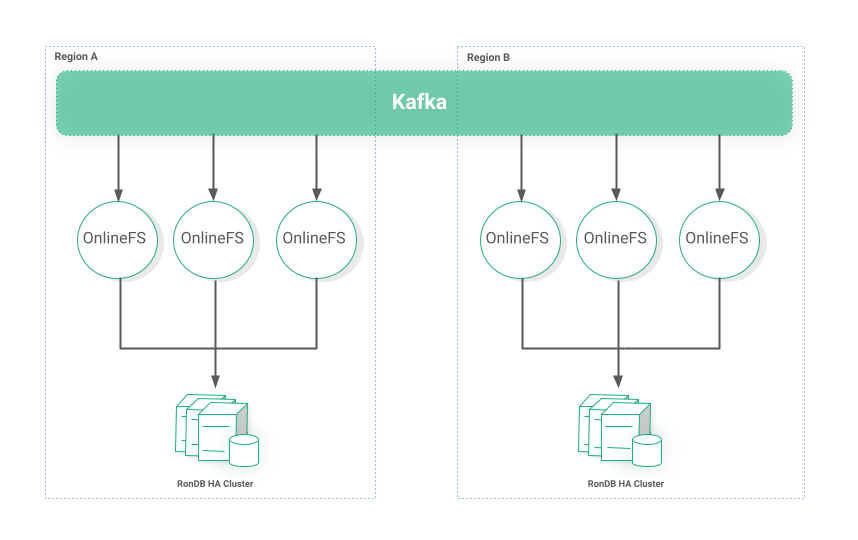
Figure 5: Active/Active multi-region Online Feature Store
The OnlineFS service relies on the Metadata application just for fetching some metadata information such as topic schema at the beginning of its lifecycle. Other than that it can operate independently even if the metadata component is not online.
Active-Passive Offline Store
The offline store is equally important to an organization but because it does not serve real time applications it does not justify the operational complexity of an Active-Active distributed system. For that reason we decided to architect the offline store in an Active-Passive configuration.
HopsFS, our distributed filesystem, stores all metadata information in the RonDB cluster of the Metadata layer. Therefore, all users, file permissions, block locations, etc are asynchronously replicated to the Standby region.
HopsFS datanodes store the actual file blocks so we need a way to replicate them on the other region. Almost every organization has some sort of Object Storage such as AWS S3, Google Cloud Storage, Azure Blob Storage etc . Even organizations with their own on-premise data-centers operate an object storage such as Scality or Cohesity. All these have two things in common. Firstly, they have the same S3-like API and secondly are geo-replicated. As mentioned in Part 1, HopsFS can use any S3 API compatible object storage as a backend system instead of the local drives. We rely on the geo-replication feature of such a system to replicate the file blocks on the passive region as depicted in Figure 6.
Finally, HopsFS is region aware and it consults the Active Cluster Arbitrator service. HopsFS in the active region will proceed running while HopsFS in standby will enter a crashloop phase. Every microservice of HopsFS runs a watchdog service which will kill the process if it is not running in the active region while letting it start if it is. With this watchdog service in place the fail-over happens automatically as soon as the ACA advertises a change in the primary/standby region configuration.
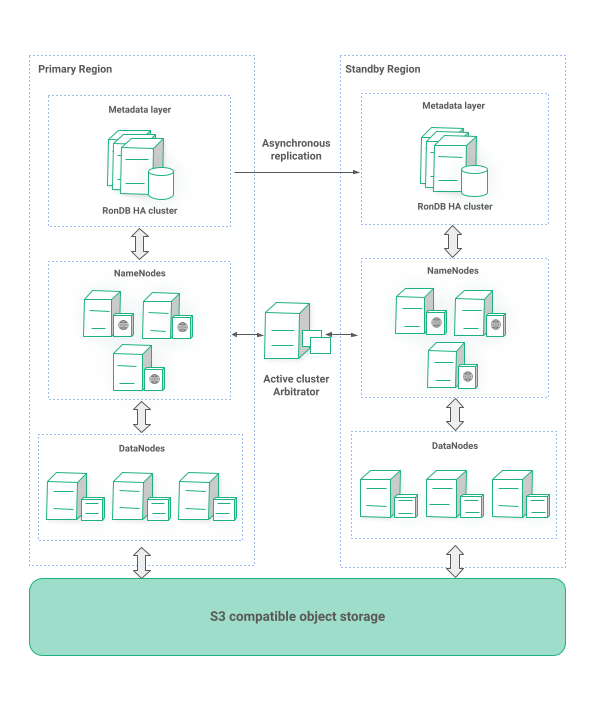
Figure 6: Multi-region Offline Feature Store
Conclusion
Feature stores are an integral component of a modern Machine Learning system. Many online applications rely on the availability of the feature store to augment a user request with some additional context which will give a more personalized experience. In the first part of this article we described the fault tolerance of Hopsworks Feature Store in a single region. We recognized the importance of a redundant system and we analyzed the high availability aspects of the three key components of Hopsworks. In this part we built on top of Hopsworks HA and we went one step further describing the multi-region characteristics of Hopsworks catered for Tier 1 applications.