Multi-Region High Availability Comes to Feature Stores
Part 1 - Single Region Highly Available Hopsworks
Learn how Hopsworks achieves high availability for the Online and Offline Feature Store and a Metadata layer, making it an operational ML system both for on-premise and cloud infrastructure.

In computer science, A.M. Turing Award winner Leslie Lamport is widely considered the father of distributed systems. His work is fundamental in understanding and modeling distributed algorithms. Among others he has worked on consensus algorithms, fault tolerant replicated state machines, distributed snapshots etc. He conceived the original Paxos protocol which inspired many more consensus algorithms and his theorems have practical implementations on every modern system. Yes, he’s the same Lamport who brought us LaTeX.
Leslie Lamport gave a non-technical, yet very precise definition of a distributed system;
“A distributed system is one in which the failure of a computer you didn't even know existed can render your own computer unusable”
[https://amturing.acm.org/award_winners/lamport_1205376.cfm]
We have witnessed a proliferation of intelligent agents in every aspect of our daily life. Some are just for fun but others are mission critical to a business such as automatic settlement of an insurance claim, live credit scoring or real-time fraud detection.
A common mistake is to think of an ML system as a single pipeline which can live on its own. Real operational ML systems are divided into three independent pipelines with clean and robust APIs to the Hopsworks Feature Store and Model Registry as shown in Figure 1.
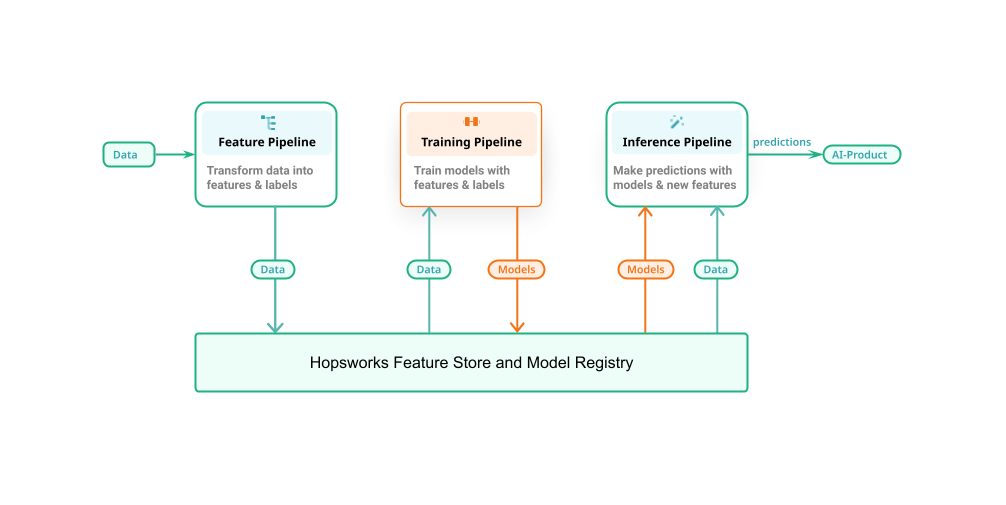
Figure 1: The Feature Store’s role in an ML system (made up by three individual pipelines; feature pipelines, training pipelines and inference pipelines).
Why a Highly Available Feature Store is Important for an ML System
Looking at Figure 1 we can see that the Feature Store plays an integral role in an ML system. Data engineers will use it frequently to curate new features which data scientists/ml engineers will consume to train a more efficient model. More importantly though, production inference services will use the Online Feature Store to retrieve relevant features and augment the inference request with user context. From that we can easily deduct how important it is for a Feature Store to be operational with the agreed SLAs and with several 9s of availability.
In Hopsworks we are passionate about building Highly Available, performant distributed systems and in this article we are going to present how we implemented a resilient Feature Store.
System Overview
Before explaining the details behind the Highly Available aspects of Hopsworks I believe it is important to give a brief overview of Hopsworks Feature Store. The intention is to explain the basic components of our system without going into much details on the application level. For a more in-depth analysis of the Feature Store and Model service please read more here.
On high level Hopsworks Feature Store consists of three components:
- an offline store for large volumes of historical feature data used for training and for batch predictions,
- an online store for feature data that is read at low latency by online (interactive) AI applications;
- a metadata layer that stores information about the feature store itself, and metadata about the feature data, users, computations, and so on.
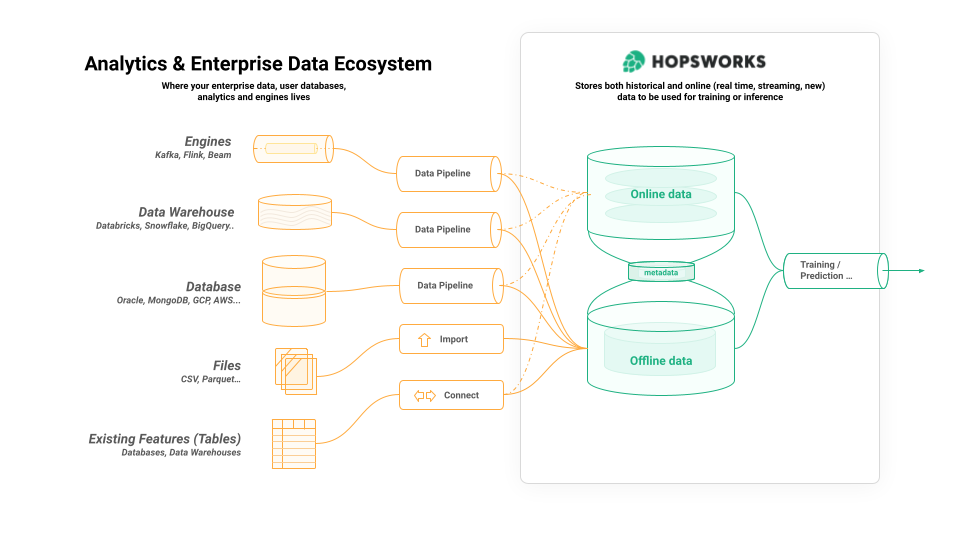
Figure 2: Overview of Hopsworks Feature Store
Do you remember the definition of a distributed system that Lamport gave? A catastrophic failure in any of the aforementioned components will affect the end-user and may cost the organization in money, reputation or regulatory penalties.
In the following sections we will describe how we built a resilient system without single point of failures for the mission critical components.
Resilient Metadata Layer
We will begin by describing the architecture of the metadata layer as it is the link between the online and offline store. In a nutshell, the metadata layer stores schemata information for the online feature store, information about feature views, storage connectors, system users and projects etc Moreover, HopsFS - our distributed file system used in the offline store - stores file system metadata such as file ownership and permissions, block locations, distributed locks etc.
We store all our metadata in RonDB, an in-memory, distributed, low-latency database with ACID properties. For any distributed system, failure is part of its design, it should not be an exceptional case, rather it should be normal and the system should survive and recover.
Redundancy in RonDB
RonDB consists of one or more _Datanode_s which store the actual data in-memory. A datanode will periodically snapshot its data to a durable medium to be able to survive a node restart. Datanodes are organized into Node Groups which store fragment replicas. That means a cluster would survive as long as there is at least one alive node in a Node Group.
The RonDB Management node is responsible for maintenance operations such as taking consistent backup of datanodes, joining new datanodes, creating node groups, being the arbitrator in case of a network split etc. there must be at least one management node in every RonDB cluster.
Finally, you can have zero or more API nodes. Data stored in datanodes can be accessed via the NDB API which has bindings for C++, Java, Javascript but the most common way is through a MySQL server and standard ANSI SQL. So a cluster can have more than one MySQL server to achieve higher performance but also redundancy.
Having all these in mind let’s look at Figure 3 which illustrates a typical RonDB cluster. We have two Node Groups, each consisting of three Datanodes, two Management servers and multiple MySQL servers. Additionally, we have redundant REST API servers and various other clients using ClusterJ or C++ API to connect to RonDB.
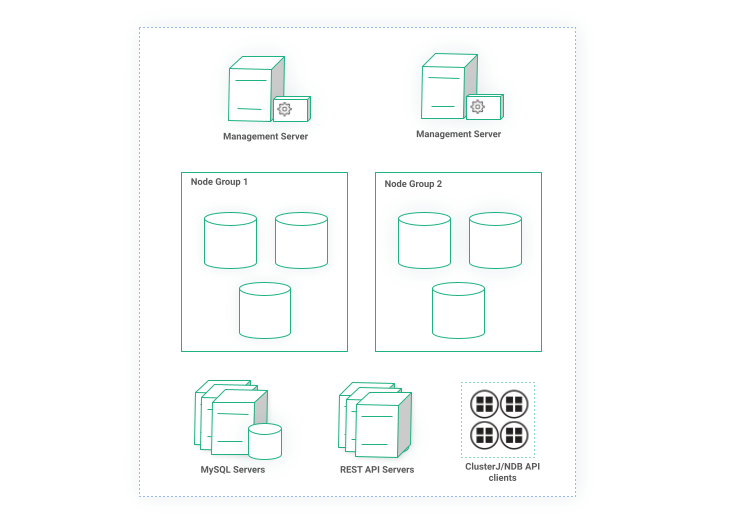
Figure 3: Highly available RonDB cluster
In our setup above losing both Management servers will not impact the availability of the cluster. For as long as both are dead, new nodes cannot join or take a cluster backup but the database is fully operational. Any number of API nodes can be configured to take over the role of arbitrator in case of a split-brain scenario. If one management server is still alive, then nothing is impacted.
As mentioned above, Datanodes is where data is stored so obviously they are designed with redundancy in mind. The cluster is operational as long as each node group participating in the cluster has at least one node operating. RonDB being an ACID compliant database, it will automatically shutdown when it is not safe to operate any longer, that is when all nodes in a node group are dead.
Finally, API nodes such as MySQL servers are stateless processes so we can afford losing all of them - Online store as we will see later it uses the NDB API directly. Also, because MySQL servers in this case are lightweight we can run multiple nodes. Datanodes and API nodes are Availability Zone aware so although they can both be spread in different AZs they will always prefer a local Datanode if possible.
That said, the Metadata Layer is not just a database, it is also an advanced and complex application exposed via a RESTful API. It would be useless to achieve high availability on the database layer while the actual application using the database is the single point of failure. Since we store all state in the database, the application itself becomes stateless so we can deploy as many replicas as we want to satisfy our needs. We employ a distributed shared memory for any caching or synchronization among the replicas but still all persistent state is stored in RonDB.
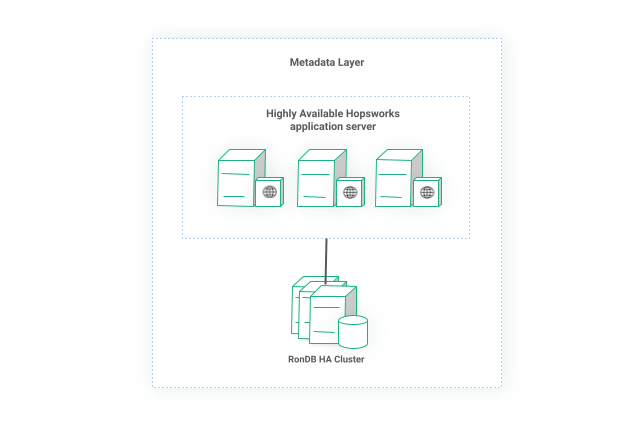
Figure 4: Metadata layer with multiple replicas of Hopsworks application and a resilient RonDB cluster
High Availability Online Store
The Online store consists of a number of stateless microservices applications which read messages from Kafka topics and consistently stores the data to RonDB as shown in Figure 5. The RonDB cluster is different from the Metadata layer cluster which allows flexible SLAs and custom-tailored configuration but it follows the same architecture to achieve high availability.
Achieving high availability for Kafka clusters is a straightforward task, we deploy multiple Brokers with an increased replication factor. OnlineFS is a containerized application with no state so multiple copies can run in parallel to achieve not only redundancy but also higher performance. OnlineFS will use the Metadata layer in the beginning of its lifecycle to fetch feature groups schemata but otherwise it is not used. So, even if the entire Metadata layer goes offline, the Online Feature Store will continue operations as normal.
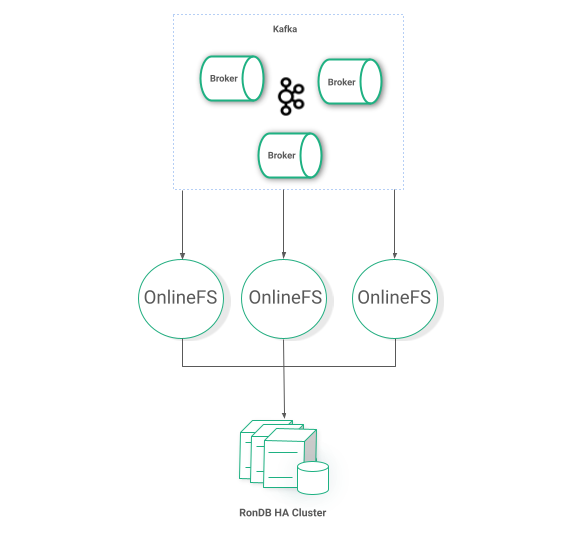
Figure 5: Redundant Online Feature Store
Resilient Offline Store
The second type of storage Hopsworks Feature Store provides is called offline and it is intended for large volumes of data and time-traveling queries. The offline store is backed by HopsFS which is a distributed, high performance, fault tolerant, POSIX-compliant filesystem.
HopsFS consists of _NameNode_s which are the “brains” of the filesystem responsible for acquiring distributed leases, knowing the blocks a file consists of, file permissions etc The actual blocks are handled by Workers. So when a client reads a file from HopsFS, it will first go to any of the NameNodes, the NameNode will validate the permissions of the file, figure out which blocks a file consists of and return a list of Workers responsible for these blocks. The client will then connect to these Workers, read the blocks in parallel and reconstruct the file.
All information that a NameNode is responsible for is stored in the Metadata RonDB cluster so the process becomes stateless which means we can have multiple active NameNodes on the same cluster for redundancy and higher performance. We have already discussed the resiliency of the Metadata layer so we will move to Workers.
Workers have different options for storage backend. It could be the local disk of the VM, an S3 bucket, Azure Blob Storage, Google storage or any S3 compatible storage solution. In case of local storage, the blocks are replicated to different workers, usually 3, for redundancy. So, even if some machines go offline you will still be able to reconstruct a file. Workers are rack or AZ aware so blocks are spread evenly.
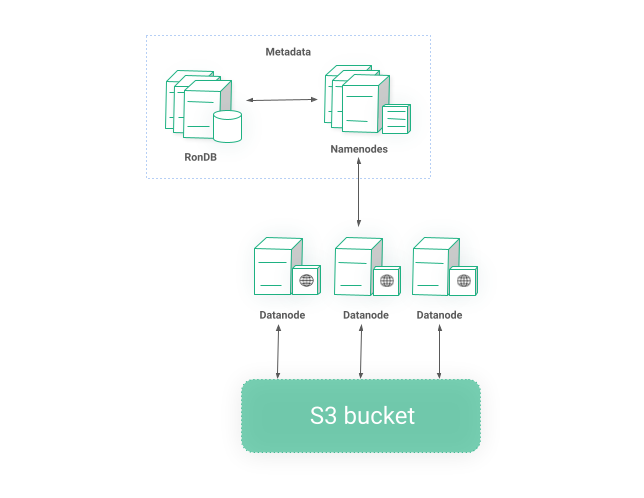
Figure 6: POSIX compliant distributed storage layer on top of S3
Due to the popularity of S3 more and more organizations prefer solutions such as Scality, Cohesity or MinIO which are on-premise S3 compatible object stores. In such cases, Workers act as a cache layer while the actual blocks are stored in the configured storage as shown in Figure 6. Replicating the blocks is obviously not required in this case and we rely on the underlying storage for availability.
Conclusion
Looking at Hopsworks Feature Store from 30000 feet above we can identify three subsystems. The Online Feature Store, the Offline Feature Store and a Metadata Layer. In this article we described how we achieve high availability for the aforementioned systems and making Hopsworks a real operational ML system both for on-premise and Cloud infrastructure. In the next article we will go one step further and explain a multi-region setup catered for Tier 1 applications.