Hello Asynchronous Search for PySpark
Read how Hopsworks supports easy hyperparameter optimization (both synchronous and asynchronous search), distributed training using PySpark.

“Methods that scale with computation are the future of AI” [1],
“The two (general purpose) methods that .. scale ...are search and learning.” [2]
- Prof Rich Sutton, Father of Reinforcement Learning in “The Bitter Lesson”
Deep learning is a powerful supervised learning method for building predictive models when there are sufficient amounts of high-quality labelled training data available. When an organization chooses a platform for deep learning, it needs to cater for as many potential use cases as possible, and one use case that is appearing more and more frequently is the use of larger models with more training data [3]. Empirical studies in different domains such as neural machine translation and image classification have shown that predictive models have a logarithmic improvement in their accuracy for every order of magnitude more training data that becomes available. AutoML, the automating of building machine learning models, has been shown to outperform humans in designing model architectures, and the most accurate models for the ImageNet classification challenge have been designed by search algorithms. The only conclusion we can draw is that, long term, more data and more compute will yield better models, and the companies with better models will have a competitive advantage in their field of business.
Horizontally Scaling Machine Learning
In Figure 1, we can see the challenges in scaling out deep learning. In the InnerLoop, the current best practice for reducing the time required to train models by adding lots of GPUs is data-parallel, synchronous stochastic gradient descent. To find good hyperparameters (before we train the model with lots of GPUs), directed search algorithms (such as genetic algorithms, Bayesian optimization, HyperOpt, ASHA) are considered the state -of-the-art.
In Hopsworks, we use PySpark to scale out both the inner loop and the outer loop for Machine Learning, see Figure 1 (below). The inner loop is where we train models - scaling out here means adding more GPUs to make training go faster (data-parallel training). The outer loop is where we run many experiments to establish good hyperparameters for the model we are going to train. We typically run many experiments as we need to search for good hyperparameters - hyperparameters are not updated during training and hyperparameter space is typically not smooth, so gradient-based approaches often do not work - undirected and directed search typically work better.
Spark provides a bulk-synchronous parallel computation framework for distributed computing that maps well to the Inner Loop (synchronous stochastic Gradient Descent is the state of the art for distributed training), but Spark does not scale efficiently for directed search for hyperparameter tuning. To this end, we later introduce a new framework, Maggy, and describe Maggy’s new asynchronous task-based compute model for more efficient hyperparameter tuning. But most importantly, we show how, with just a few lines of code, you can update your single-host Python program to become a monster job that can have its hyperparameters tuned using hundreds of GPUs in parallel or be trained in parallel on hundreds of GPUs. We show how you can do it all in a Jupyter notebook - even though the GPUs will be in the cluster, and you will be able to view the logs from the parallel training tasks in real-time from the comfort of your Jupyter notebook cell.
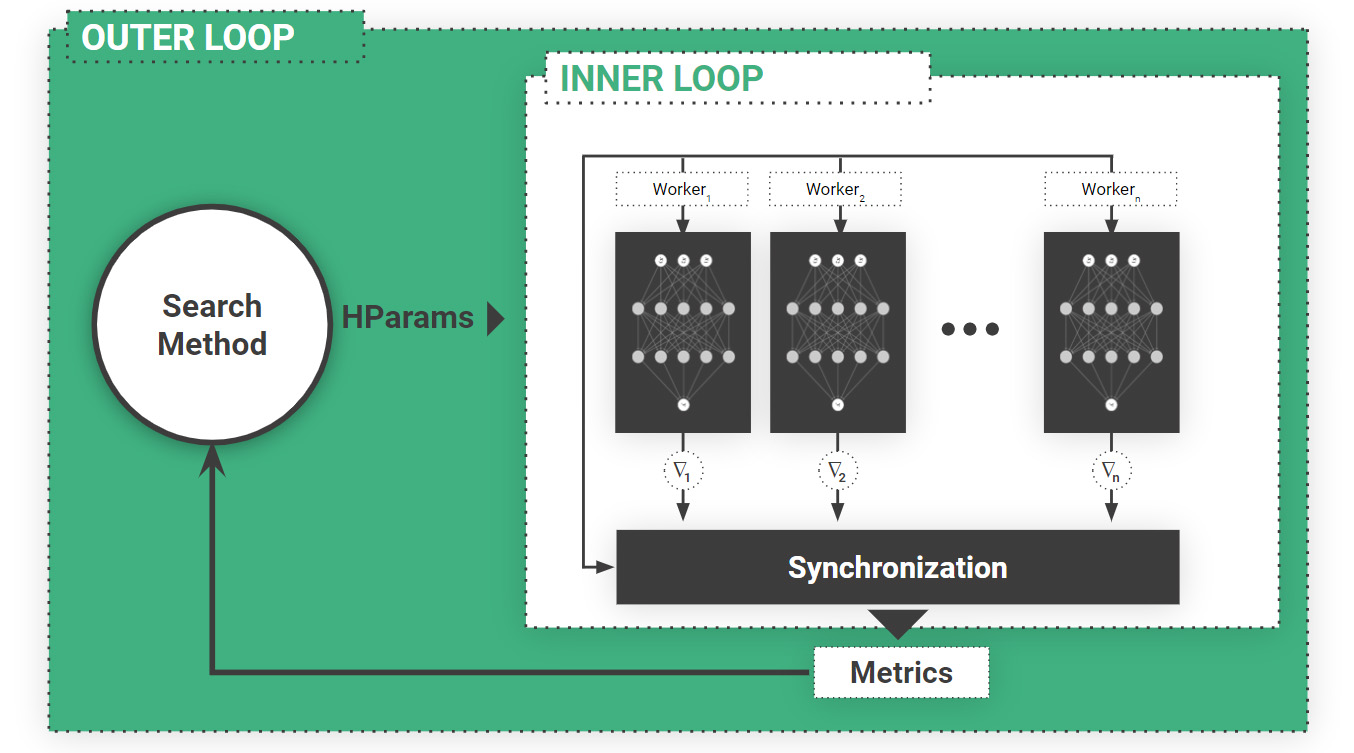
Figure1: Scaling out Training ML/DL requires scaling out both the Inner Loop (dataparallel training with synchronous stochastic gradient descent) and the OuterLoop (hyperparameter search – directed or undirected). Scaling out the OuterLoop enables you to run lots of experiments in parallel to find good models with good hyperparameters. Scaling out the Inner Loop will reduce the time required to train a model, with more gains seen when training large models on large volumes of data.
Horizontally Scalable ML Pipelines with Hopsworks
Hopsworks is an open-source platform for the development and operation of data-intensive AI applications. Hopsworks leverages PySpark to provide cluster support for Python. With PySpark, a TensorFlow/Keras/PyTorch program can be made to run hyperparameter optimization or distributed training with up to hundreds of GPUs in the cluster, with a few lines of code changes. As can be seen in see Figure 2, by parallelizing ML/DL across many GPUs, we can both speed up our ML pipeline as well as make Data Scientists massively more productive.
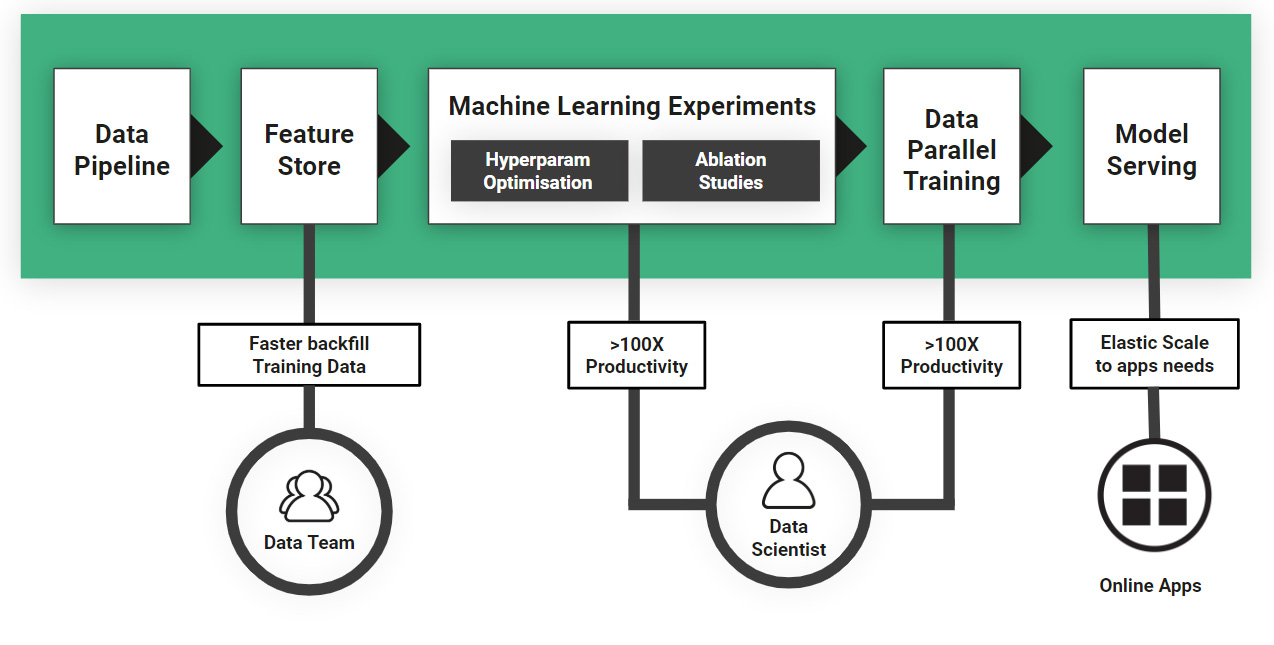
Figure 2: Hopsworks supports building horizontally scalable ML pipelines. Machine Learning stages can be scaled out for both ML Experiments and Training (Data Parallel Training), massively increasing Data Scientist productivity.
Synchronous Hyperparameter Tuning on PySpark
Hopsworks has supported hyperparameter tuning using PySpark since version 0.4 (released in Oct’18). In Figure 3, we can see how Executors in PySpark (workers) run hyperparameter trials in parallel, where each Executor may also have one or more GPUs to run the training function. In hyperparameter tuning, a trial is an experiment (a training run) with a given set of hyperparameters that returns its result as a metric. In synchronous hyperparameter tuning (see Figure 4), the results of trials(metrics) are written to HopsFS, where the Driver reads the results and can then issue new jobs with new trials as Spark tasks to Executors, iterating until hyperparameter optimization is finished.
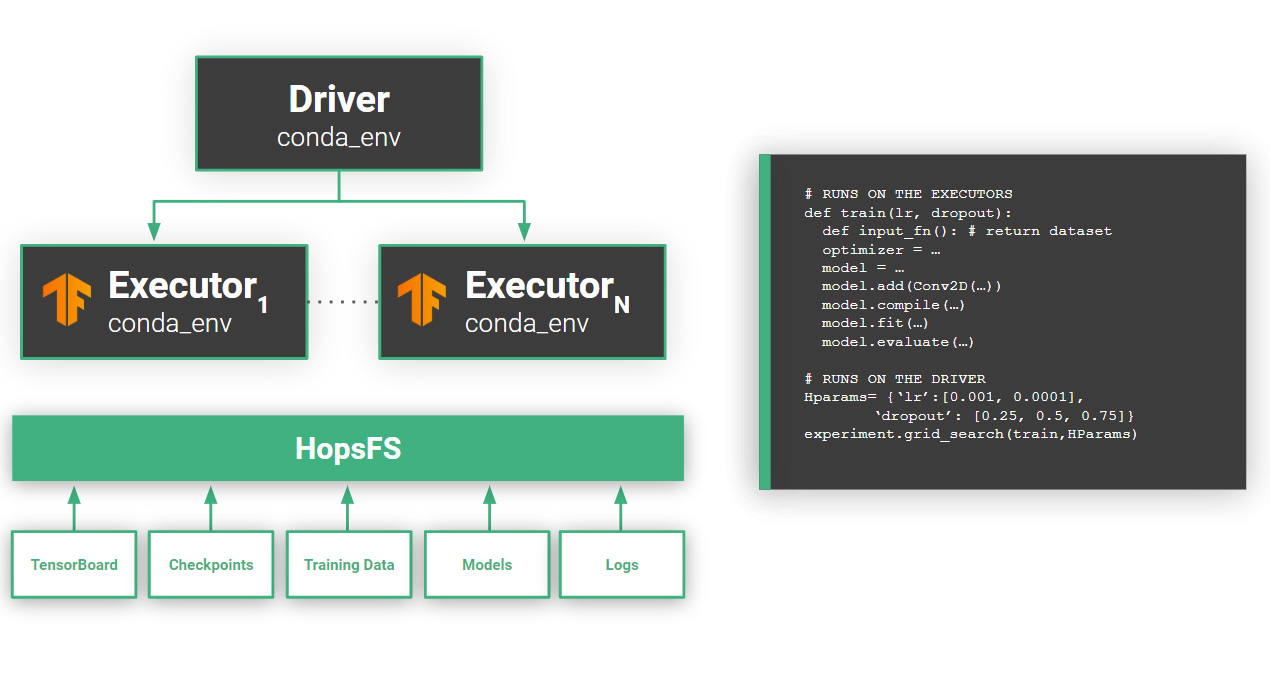
Figure 3: In the example GridSearch code shown on the right, six trials are run with all different possible combinations of learning_rate (lr) and dropout. Executors will run these trials in parallel,so if you run this Gridsearch code with 6 Executors, it will expect to complete6 times faster than running the trials sequentially. HopsFS is used to store results of the trials, logs, any models trained, and any visualization data forTensorBoard.
While the synchronous approach works well for undirected search algorithms, such as grid search and random search, it is less efficient for directed search algorithms (population-based methods, Bayesian optimization, etc). In Figure 4, we can see 3 Spark stages (i.e., 3 barriers) with N Spark tasks each, being executed on separate Spark Executors. In the bulk synchronous execution model of Spark, once a job is started and Spark creates the directed acyclic graph of tasks and stages to be executed, there is no possibility to dynamically stop, add or remove tasks from stages. Furthermore, a new stage can only begin once all tasks in the previous stage have finished. Since we evaluate one trials per task, this introduces inefficiencies -early-stopping will not free up the Executor to take new trials, it can only receive a new trial at the start of the next stage. If any executor is slow(straggler) or fails, it will slow down all other Executors. Trials will naturally have varying training times due to the differing hyperparameter settings. Together with the stage based execution, this is suboptimal for directed search algorithms such as BayesianOptimization. A Bayesian Optimizer is able to incorporate the feedback in terms of the final performance metric of a trial as soon as it finishes to produce better new samples. However, the meta-level Bayesian Optimizer, will only be updated with all the metrics of a stage once it finishes. Therefore, we would like to update our knowledge as soon as a trial finishes.
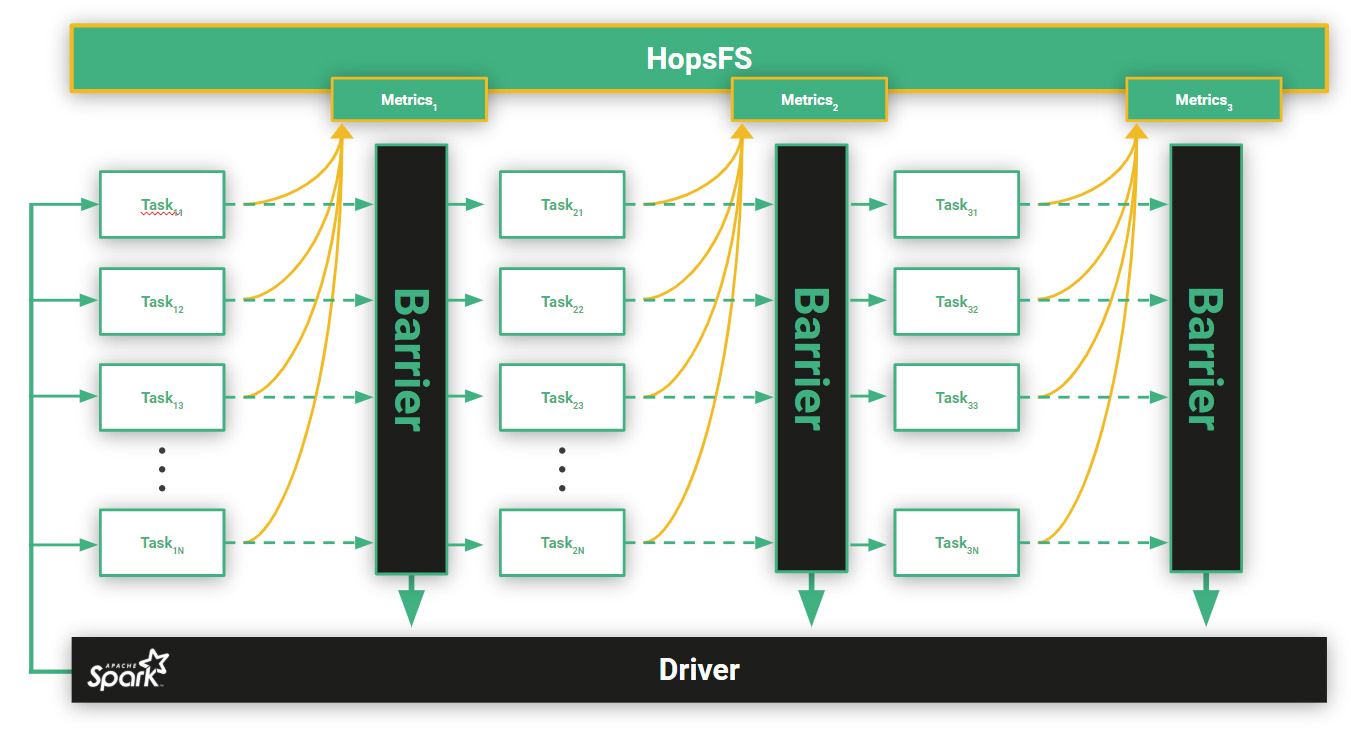
Figure 4: A Spark job consisting of 3stages with N tasks in each stage. Each task is a trial, evaluating some combination of hyperparameters. The trials for a stage are only finished whenall the tasks in a stage have completed. That is, the driver reads the results of all trials from the shared filesystem, and then can issue new trials as tasks to Executors. If a trial is performing poorly, early-stopping will not help as the Executor will have to wait anyway until the end of the stage before it can receive a new trial.
Early-Stopping with Wasted GPUs
In hyperparameter tuning, some trials will perform poorly and early during the trial’s execution it will be clear that the trial can be stopped, because its performance is very poor relative to the other executing trials. In experiments with RESNET-50 on Hyperband, they saw savings of up to 96.5% in cost with early stopping. However, to get those savings early-stopping requires sharing the current performance of trials between Executors, to know if a trial’s relative performance is poor. In Figure 5, we introduce early-stopping to Spark - the red arrows indicate trials that are stopped early. Here, we can see that there is a significant amount of wasted compute (GPUs), where the Executor idles until the end of the stage after the trial has been stopped. In this example, early-stopping decisions are not optimal as they are taken locally by the Executor – the Executor has no knowledge of the performance of other Executor trials. In Spark, tasks are independent units of work, without communication between them. One could potentially free up resources by blacklisting the idle executor to make the resources available to other jobs, but on a multi-tenant platform it will be hard to reacquire those resources.
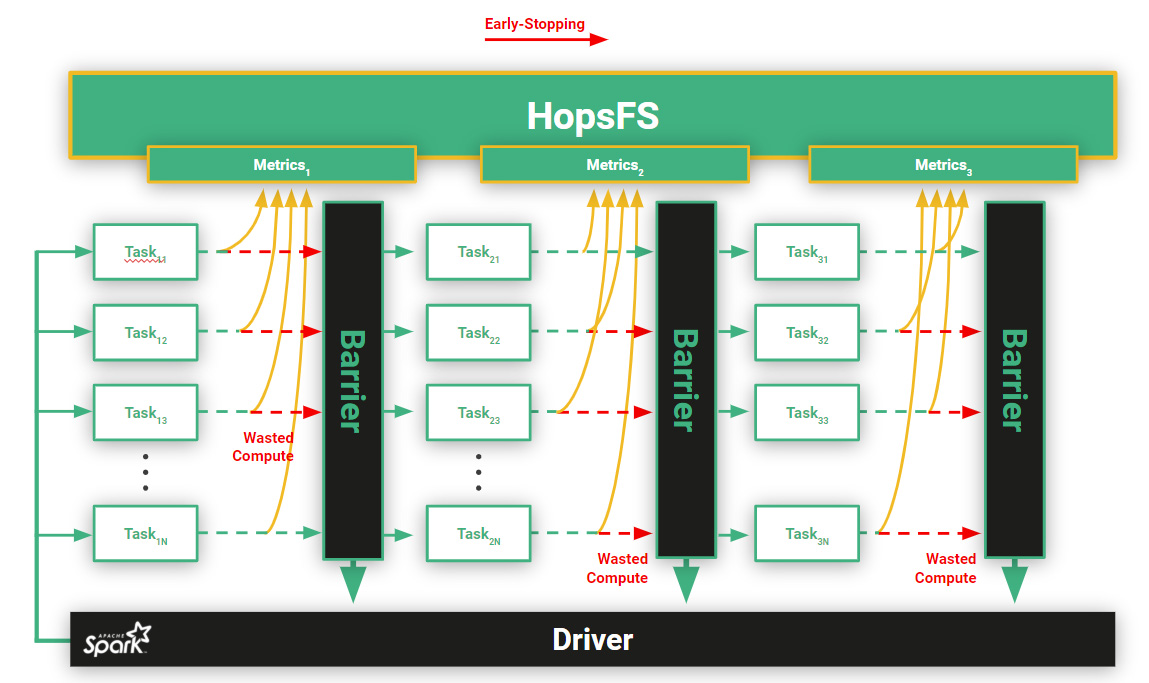
Figure 5: Hyperparameter Search with early-stopping leads to lots of wasted GPU cycles. Executors in PySpark have to wait until the next stage (Barrier) is reached before a new Trial can be executed. For early-stopping to work well, Executors should continually share the current performance of their trial, so the worst relative performers can be stopped early.
Asynchronous Hyperparameter Search with Maggy
Maggy is a framework for asynchronous trials and early-stopping with global knowledge, guided by an Optimizer. Developers can use an existing Optimizer, such as asynchronous successive halving (ASHA), or provide their own one. The basic approach we followed, see Figure 6, was to add support for the Driver and Executors to communicate via RPCs. The Optimizer that guides hyperparameter search is located on the Driver and it assigns trials to Executors. Executors periodically send back to the Driver the current performance of their trial, and the Optimizer can decide to early-stop its ongoing trial, followed by sending the Executor with a new trial. Because of the impedance mismatch between trials and the stage-/task-based execution model of Spark, we are blocking Executors with long running tasks to run multiple trials per task. In this way, Executors are always kept busy running trials, and global information needed for efficient early-stopping is aggregated in the Optimizer.
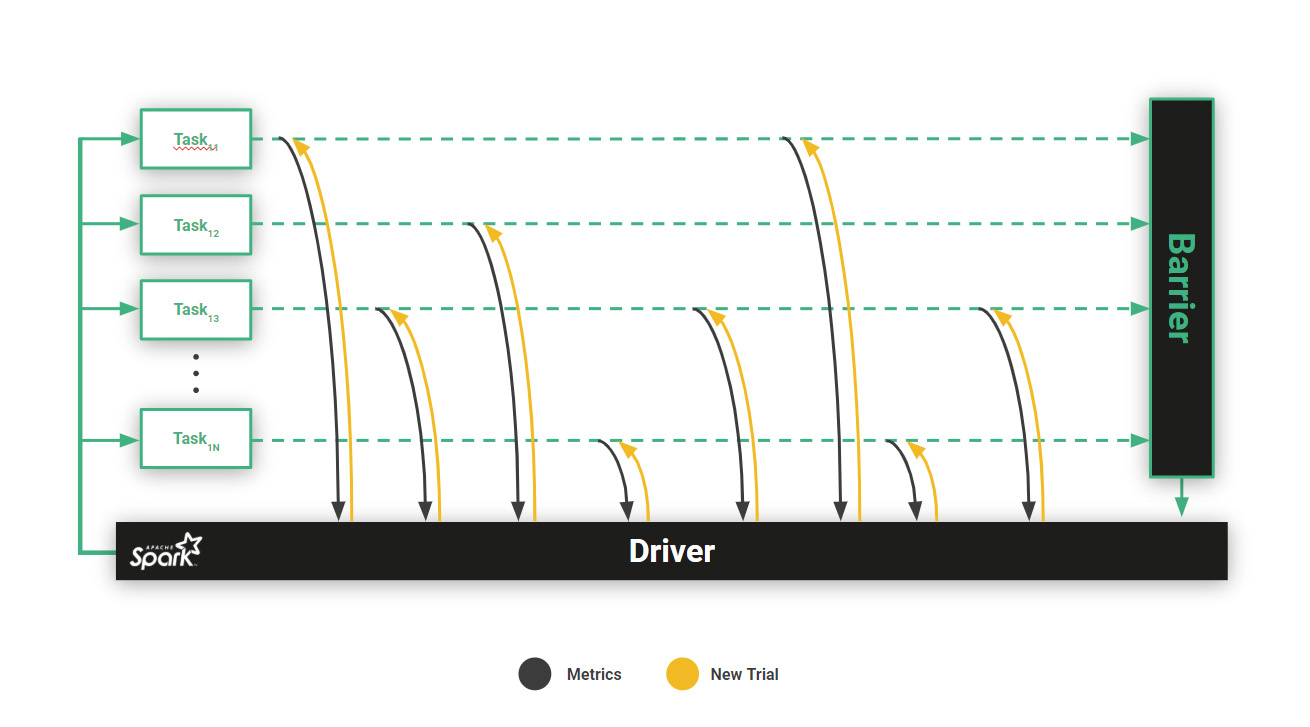
Figure 6 Directed Asynchronous Search using Maggy. Executors run a single long-running task and receive commands from the Driver (Optimizer) for trials to execute. Executors also periodically send metrics to the Driver to enable the Optimizer to take global early-stopping decisions.
Maggy, provides two high-level APIs: one for black-box optimization experiments (hyperparameter tuning) and one for parallel Ablation studies. As Maggy has a general-purpose RPC framework for collecting events from Executors at the Driver, we also collect logs from training generated by Executors, so that those logs can subsequently be displayed in real-time in a Jupyter notebook. That way, users can debug and follow hyperparameter tuning directly from their notebook.
Distributed Training with CollectiveAllReduce
Once good hyperparameters and a good model architecture have been designed, a model can be trained on the full dataset. If training is slow, it can be speeded up by adding more GPUs to train in parallel, in what is known as data-parallel training, where each Worker(Executor) trains on different shards of the training data. This type of distributed training benefits hugely from having a distributed file system (HopsFS in Hopsworks), where Workers can read the same training data, and write to the same directories containing logs for all the workers, checkpoints for recovery if training crashes for some reason, TensorBoard logs, and any models that are produced at the end of training.
Synchronous stochastic Gradient Descent is the current state-of-the-art algorithm for the updating of weights in DeepLearning models, and it maps well to Spark’s stage-based execution model. CollectiveAllReduce is the current state-of-the-art implementation of Synchronous stochastic Gradient Descent, as it is bandwidth optimal (using both upload and download bandwidth for all Workers) compared to the Parameter Server model, which can be I/O bound at the Parameter Server(s).
In CollectiveAllReduce, within a stage, each worker will read its shard of the mini-batch, then send its Gradients (changes to its weights as a result of the learning algorithm) to its successor on the ring, while receiving Gradients from its predecessor on the ring in parallel. Assuming all Workers train on similar batch sizes per iteration and there are no stragglers, there will be excellent efficient in use of GPUs. The code changes required to make a TensorFlow/Keras program distributed are minimal, a scan be seen in Figure 7.
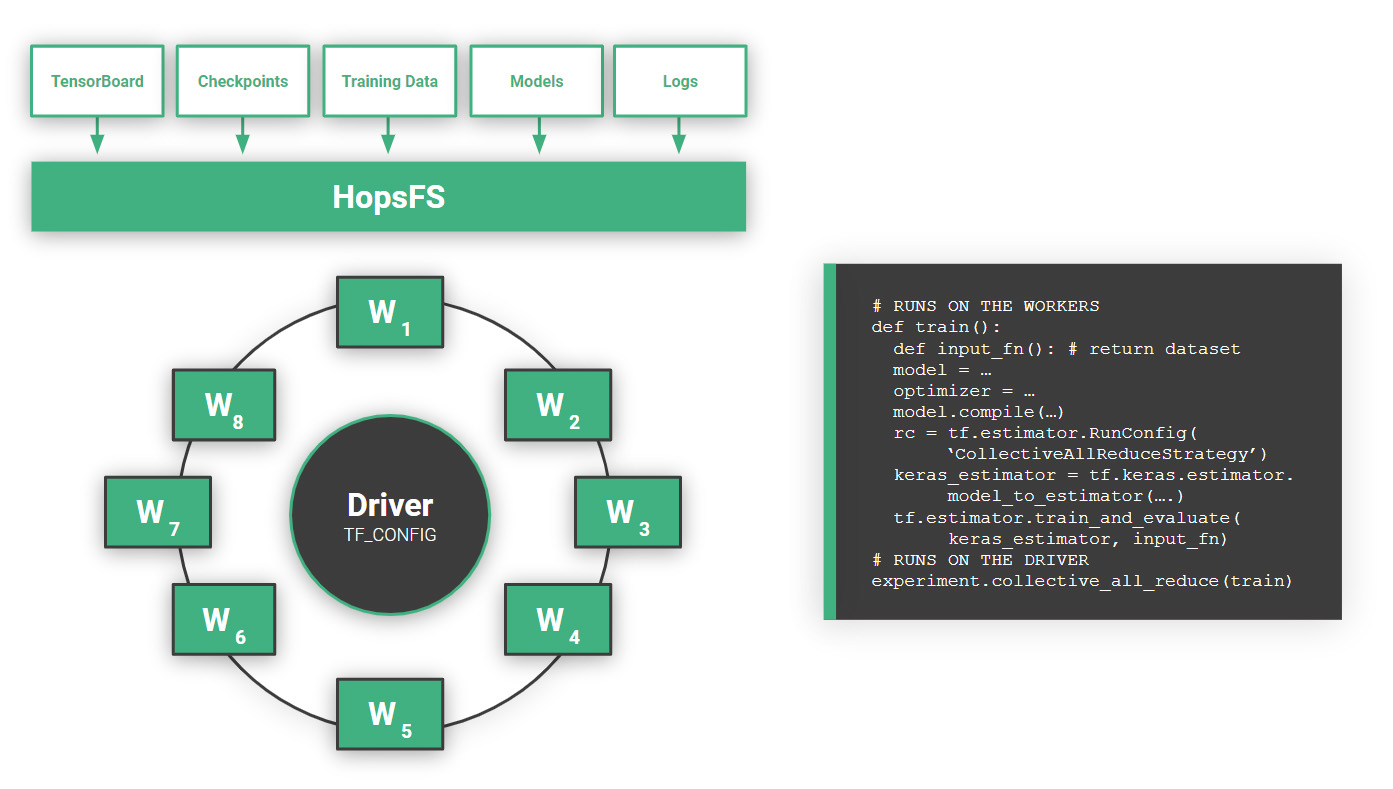
Figure 7 Distributed Training using Ring-AllReduce (CollectiveAllReduce). Hopsworks ensures that the shared TF_CONFIG environment variables, used to build the ring, are distributed to the Spark Executors (or Workers in TensorFlow terminology) by the Driver. The code snippet shown here remains unchanged if you run with 1 or 1000 workers. The train function will be run on the Workers, and each Worker will read its shard of the mini-batches from HopsFS during training.
Takeaway
With PySpark, we can scale ML programs from single-host to clustered applications,enabling us to perform faster experimentation, train models faster and on more data, and be all-round more productive ML engineers. Where PySpark has limitations in supporting asynchronous search, GPU utilization can be affected, and we introduce Maggy as a framework that adding asynchronous tasks to Spark, enabling new efficient directed hyperparameter search algorithms. Hopsworks also provides framework support for easy distributed training, using PySpark and CollectiveAllReduce from TensorFlow, enabling models to be trained faster on more GPUs, enabling more accurate models that can drive the business forward.