Goodbye Horovod, Hello TensorFlow
Hopsworks is replacing Horovod with Keras/TensorFlow’s new CollectiveAllReduceStrategy, a part of Keras/TensorFlow Estimator framework.

I usually tell my students that time in the Deep Learning community is measured in dog years. The rate of advancement is so rapid that methods, frameworks, and algorithms that were state-of-the-art just one year ago (in human years) may already be obsolete. However, one constant among all the changes is that deep learning is going distributed.
“ICLR 2019 lessons thus far: The deep neural nets have to be BIGGER and they’re hungry for data, memory and compute.”
Prof Nando de Freitas, Oxford Univeristy (Oct 2018)
“It is starting to look like deep learning workflows of the future feature autotuned architectures running with autotuned compute schedules across arbitrary backends.”
__Andrej Karpathy - Head of AI @ Tesla (March 2017)
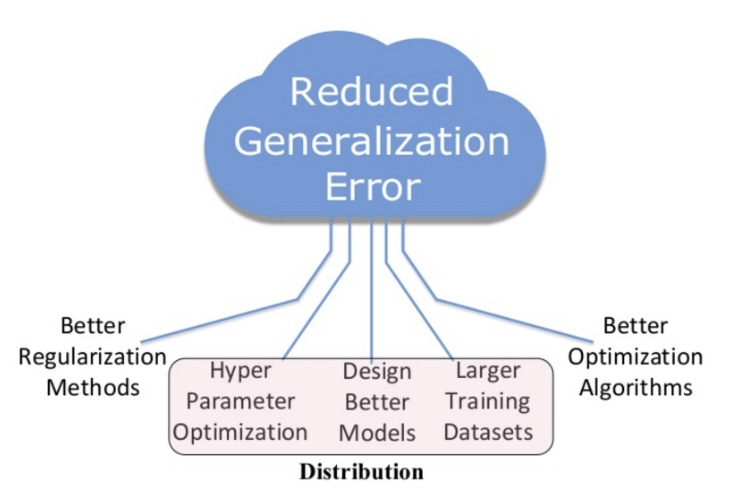
As we can see from the figure above, if we want to train state-of-the-art (SoTA) models, there are five common approaches. Improving algorithms for regularization and optimization tends to be the focus of academia and hyperscale AI companies. For the remaining three approaches, just going distributed enables you to improve the accuracy of your models by
- discovering better hyperparameters (the adam/amsgrad controversy shows their importance),
- training with larger amounts of training data (see how Facebook improved the SoTA in ImageNet by adding 2bn more images), and
- discovering better neural network architectures with AutoML techniques (see here how Google used genetic algorithms to design a SoTA Deep Neural Network (DNN) for ImageNet).
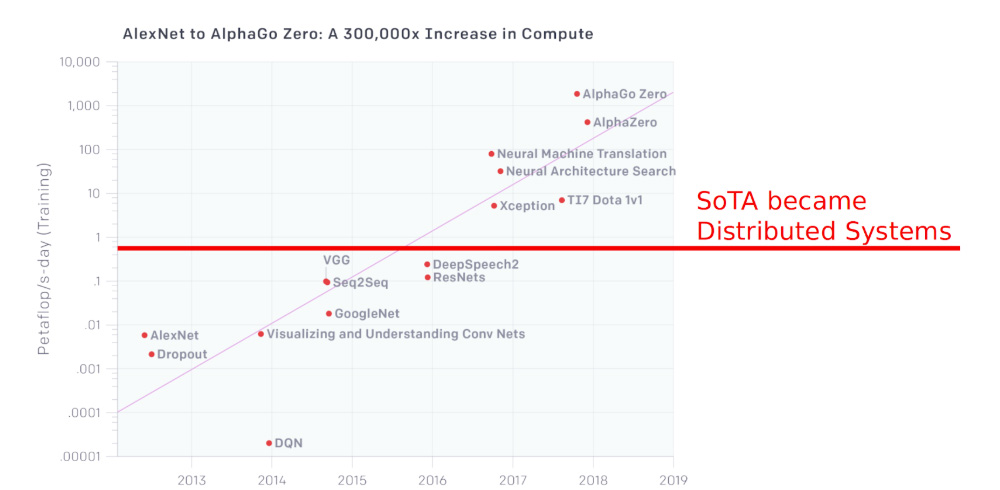
[Adapted from OpenAI]
Distributed deep learning has been pushing the SoTA in AI for several years. As you can see in the diagram above from OpenAI, there has been a 3.5 month doubling time for the amount of compute (number FLOPs) required to train state-of-the-art machine learning systems since 2012. That is, AlphaGo Zero required 300,000x more compute in 2017 than AlexNet required in 2012. While Nvidia, Google, and, more recently, AMD have been doing a good job increasing the transistor count for their hardware accelerators, they are not doubling their compute every 3.5 months. What has happened is that training of DNNs has gone distributed. For example, in October 2018, Google introduced a new framework for NLP called BERT which both heralds new possibilities for transfer learning in NLP and pushes out the SoTA in well known NLP problems. Tim Dettmers’ analysis of BERT training times shows that it would require about 396 days to train on a single GPU - the latest Nvidia RTX 2080 Ti. However, by going distributed (and buying 20 DeepLearning11 servers - the price in Oct 2018 is roughly $12k dollars each when using Nvidia 1080Ti cards), you could reduce training time to just 1-2 days. Although this type of investment is impossible for most developers, there are many enterprises that can afford such an investment in hardware, not just the hyperscale AI companies.
Data Parallel Distributed Training
Much existing enterprise data resides in data lakes (Hadoop and S3). It is currently still a challenge to build scale-out end-to-end workflows for Deep Learning and Machine Learning (ML) on such data lakes. Hopsworks is a platform designed to help enterprises build a scale-out AI platform around a data lake. In previous blogs, we talked about the importance of a distributed filesystem for an AI platform and how we optimize the use of GPUs in ML workflows. In the rest of this blog, we discuss distributed training. In particular, data parallel training with stochastic gradient descent (aka data parallel training). In data parallel training, we expect that our ML model being trained will fit in the memory of a single GPU. When we add more GPUs to training, we expect to reduce overall training time by dividing each training batch among the available GPUs, and have them process data in parallel. Data parallel training is, however, a strong scaling problem, in that communication is required between the GPUs. The batch size limits the amount of parallelism possible in data-parallel training, and therefore it is common to increase the batch size as more GPUs are added. (Also, many follow the linear scaling rule, increasing the learning rate linearly with the batch size). When the amount of time required to communicate updates in weights between GPUs grows linearly, network I/O can quickly become a bottleneck preventing training from scaling further.
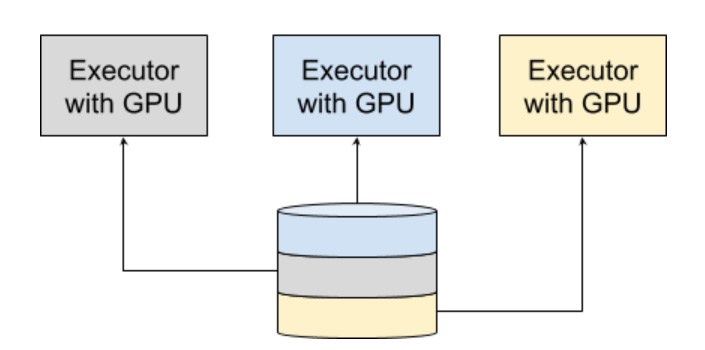
In data-parallel training, for each training iteration, each Executor/GPU receives a non-overlapping partition of samples from the batch. This is most easily achieved using a shared, distributed filesystem that holds the training data, such as HopsFS.
The first generation of data-parallel distributed training was dominated by the parameter-server architecture. In the parameter-server architecture, one or more parameter servers holds the current model and synchronizes it between a set of worker-nodes for each iteration. The problem with this type of training is that the network links between the parameter server and the workers become a bottleneck. The workers cannot utilize their full bandwidth, while the bandwidth of the parameter server becomes a bottleneck, slowing down training. This problem motivated the Ring-AllReduce technique for training.
Ring-AllReduce
Baidu first introduced the Ring-AllReduce algorithm in Feb 2017 to data parallel training for DNNs, first on the PaddlePaddle platform, then later porting it to TensorFlow’s contrib package. (AllReduce was originally developed for HPC applications.) In Ring-AllReduce, each node corresponds to a hardware accelerator (GPU), see illustration below. During training, the servers work in lockstep processing a large minibatch of training data. Each server computes gradients on its local shard (partition) of the minibatch and each server then both sends and receives gradients to/from their neighbours on the ring, in a bandwidth-optimal manner, utilizing each node’s upload and download capacity. All gradients travel in the same direction on the ring, and when all servers have received all the gradients computed for the minibatch, they update the weights for their local copy of the model using an optimization algorithm such as stochastic gradient descent. Note that all servers will have the same copy of the model after this update step. In effect, the model is replicated at all servers in the system.
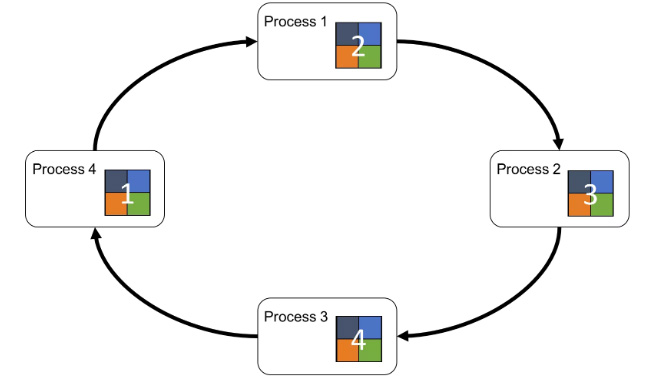
Ring-AllReduce Algorithm for Data Parallel Training
[From https://preferredresearch.jp/2018/07/10/technologies-behind-distributed-deep-learning-allreduce]
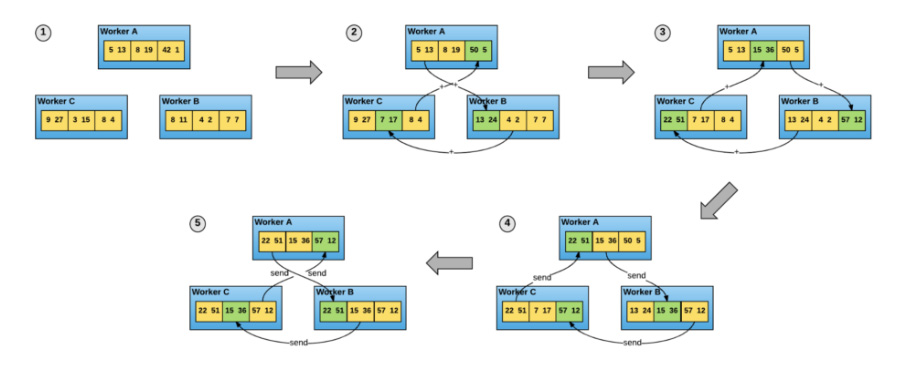
Ring-AllReduce Algorithm for Data Parallel Training in 5 steps. Workers compute and share gradients without any Parameter Servers [From https://eng.uber.com/horovod/]
Horovod

In August 2017, Uber released Horovod as a faster, easier to use library for distributed training of DNNs on TensorFlow. Horovod has since been extended to support Keras and PyTorch. Alexander Sergeev, the main developer, produced a great API for distributed training, and great quality software, that for the first time made distributed training easy to use for Data Scientists (compared to the previous parameter server models by TensorFlow and TensorFlowOnSpark). As can be seen from the table below, the amount of code required to write a “HelloWorld” distributed training example was reduced dramatically.
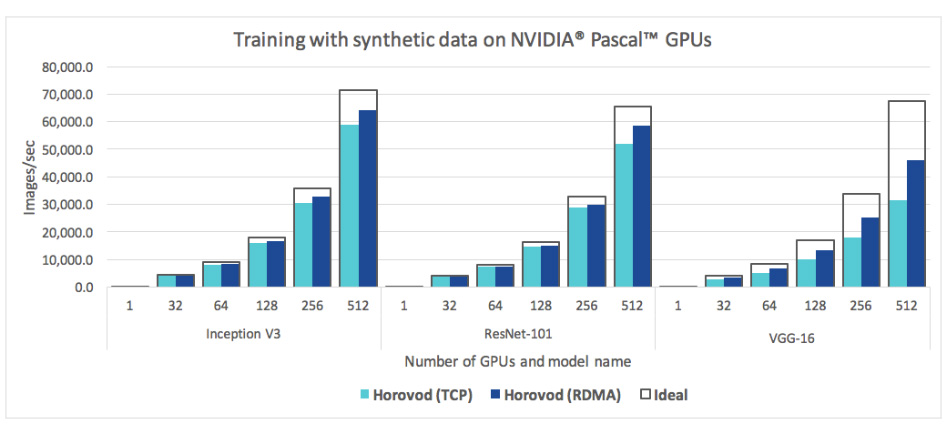
[Horovod Performance, from https://github.com/uber/horovod]
CollectiveAllReduceStrategy in Keras/TensorFlow
As we saw with the introduction of eager mode in TensorFlow to counter the rapid adoption of PyTorch (with its more Pythonic API), the TensorFlow team is flexible enough to co-opt external innovations into their platform. Ring-AllReduce has shown itself to be, in general, a better algorithm for data parallel training than the original parameter server model.
As such, in TensorFlow 1.11 (September 2018), Google introduced a new CollectiveAllReduceStrategy to the DistributedTraining part of the Estimator framework, providing Ring-AllReduce distributed training on both Keras/TensorFlow and TensorFlow. Google called it a distribution strategy that uses collective ops for all-reduce. Google has not yet released any official benchmarks for CollectiveAllReduceStrategy, but we at Hopsworks were just too curious, and jumped in to perform our own benchmarks. But before we look at the numbers, let us look at how we support programming with CollectiveAllReduceStrategy.
Firstly, we run TensorFlow inside PySpark applications - so applications are written fully in Python. You can see the pseudo-code for distributed training below. In the example below, the distributed_training function will run on an Executor in PySpark and have its own dedicated GPU (managed by Hops-YARN). We can launch PySpark applications with anything from 1 to 100s of Executors, and distributed training will scale to use the GPUs available - the code below will not change when we change the number of executors.
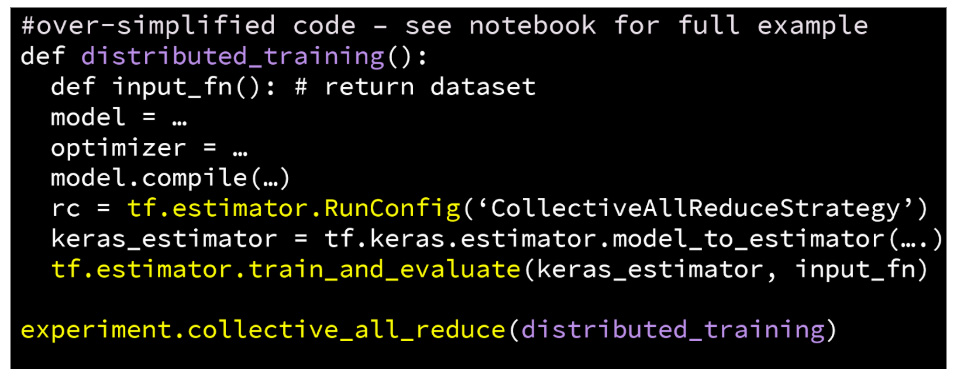
All of the workers that execute the above code snippet will write to shared directories in our distributed filesystem. This relieves us, the Data Scientists/Engineers, from having to collect and aggregate logs, models, and checkpoints from all workers - as you would have to do when working with the local filesystem.
There are a few gotchas in CollectiveAllReduce, as this feature is still currently alpha in TensorFlow. Firstly, you have to specify the GPU order in the ring statically, using the gpu_indices parameter. Luckily, the hops API will do this for you, transparently. For performance, you may also need to configure the batch size for merging tensors, allreduce_merge_scope. You can set allreduce_merge_scope to ‘1’ for no merging, or set it to ’32’ for higher throughput. Hops sets allreduce_merge_scope to a sensible default of ‘32’, trading off a small increase in latency when aggregating gradients for increased network I/O throughput.
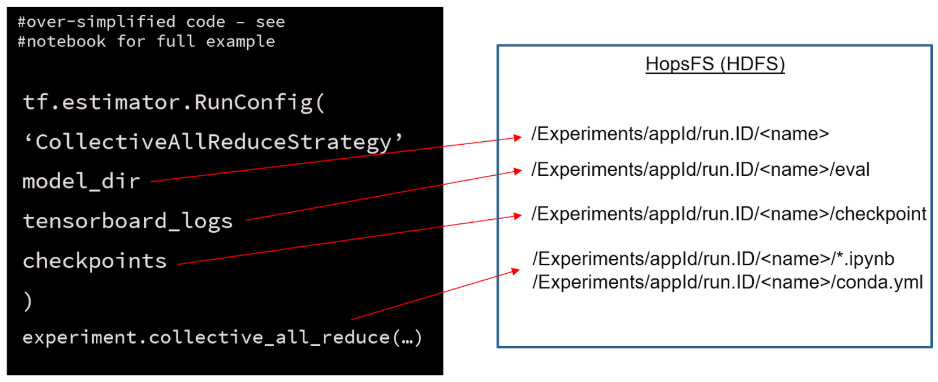
The Estimator framework in TensorFlow relieves the programmer from having to aggregate all the application logs, tensorboard logs, manage checkpoints, and export models - provided you have a distributed filesystem. Due to its HDFS compatibility, HopsFS works seamlessly with the TensorFlow Estimator Framework. HopsML’s experiment API also adds additional information needed to reproduce experiments, such as the version of the IPython notebook and the conda environment used for this experiment.
Benchmarks

Big model => High Network Traffic

Small model => Low Network Traffic
Network I/O is the most common bottleneck when training. GPUs idle waiting for gradient updates from their neighbors. This is more likely to happen if you have a large model, too low network bandwidth between hosts, and/or too low memory bus bandwidth.
The easiest way to prevent network I/O bottlenecks is to make more bandwidth available between GPUs - use 25 Gb/s or better networking and high memory-bandwidth buses, like NVLink or PCIe 4.0.
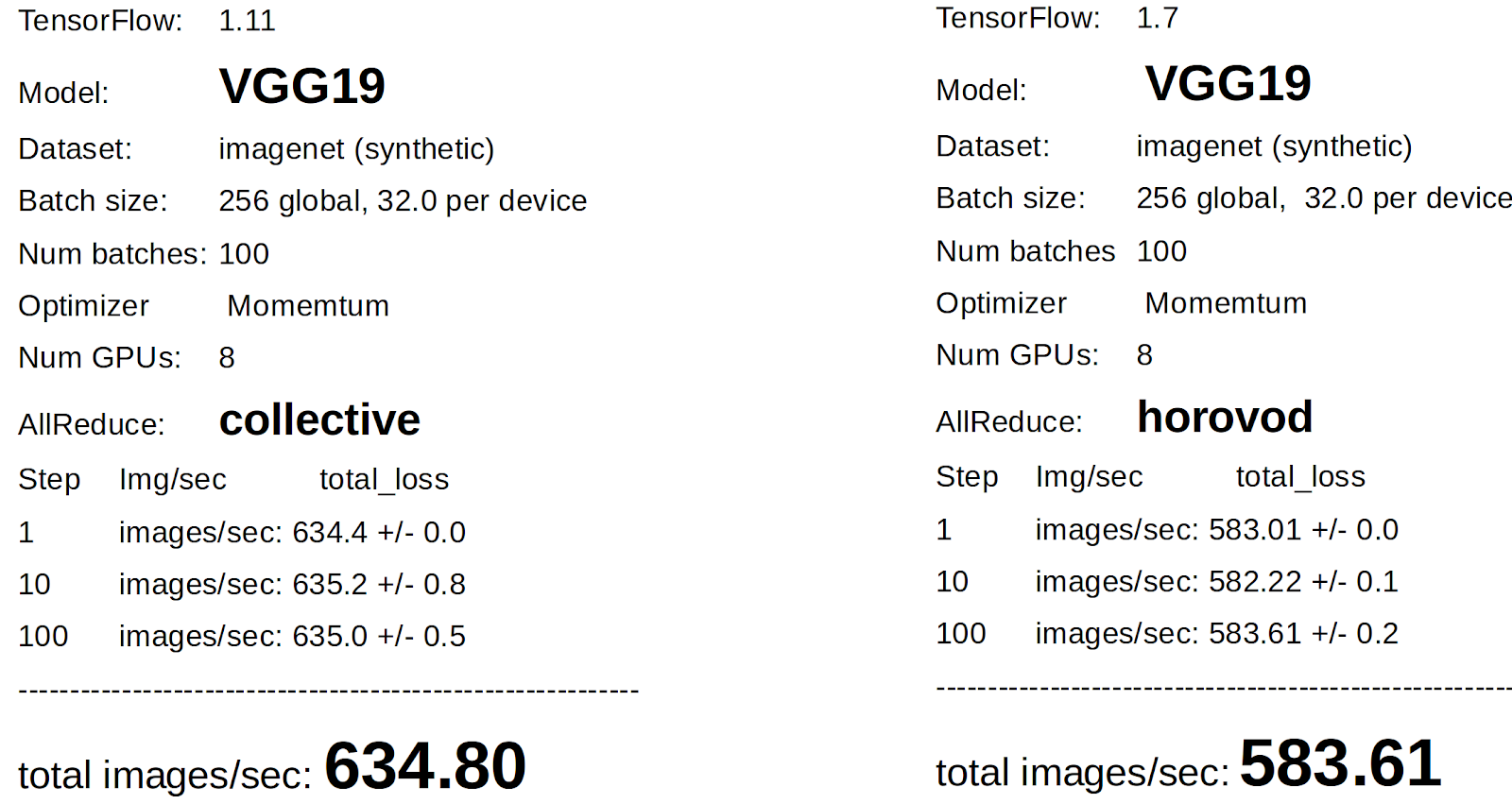
We benchmarked Horovod against CollectiveAllReduceStrategy for both a small model (GoogleLeNet, aka Inception v1) and a big model (VGG19) to see if the additional communication overhead would lead to different results. In each experiment, we tested with 8 GPUs each. Note, our results are not yet good enough for peer review, so caveat emptor. For example, we had different versions of TensorFlow (Horovod experiments were done earlier in the year), and we haven’t tested on multiple GPU servers yet.

Evaluation
The results surprised us, positively. CollectiveAllReduceStrategy outperformed Horovod. Initially, our results were not good for CollectiveAllReduceStrategy. However, we received help from the TensorFlow mailing list - thanks, telling us we had to set the following switch, which made a huge difference:
As Horovod is a thin layer over NCCL2 for AllReduce, we expected that Nvidia’s implementation would outperform Google's, as Nvidia has access to the lower level bus bandwidth measurements. One of the optimizations that possibly explains the improvement over Horovod is the use of a ScopedAllocator. In Paul Tucker’s words, from the TensorFlow mailing list:
“--allreduce_merge_scope controls a specific case of a general optimization called ScopedAllocator. The idea behind ScopedAllocator is to look for potentially parallel (in the dataflow graph) applications of the same elementwise Op, and where they can be found replace them all by a single Op instance without extra data copying. This is possible if we can arrange for the inputs of those Ops to be computed into adjacent regions of a single previously allocated tensor of the right dimensions. Since CollectiveReduce is elementwise, it fits the model and is the first such Op we've applied this optimization to.
The ScopedAllocator optimization is an improvement if the cost of the Op being merged has a significant min cost or is sublinear with tensor size, and if all the inputs of the nodes it merges are available at roughly the same time, so that we don't stall progress while waiting for the last input to become available. The --allreduce_merge_scope parameter to the benchmark program actually controls the distance in the graph that we're willing to look for potential nodes to merge. When it's 1 no merging will be done. When it's 32 then the gradients subject to all-reduce are batched into groups of 32 based on the order passed into the graph builder and the optimization is limited only to Op instances in the same group. This is obviously crude and non-optimal but seems to work pretty well for now, at least with the benchmark programs. Given time and manpower a more sophisticated approach could be implemented.”
Hopsworks
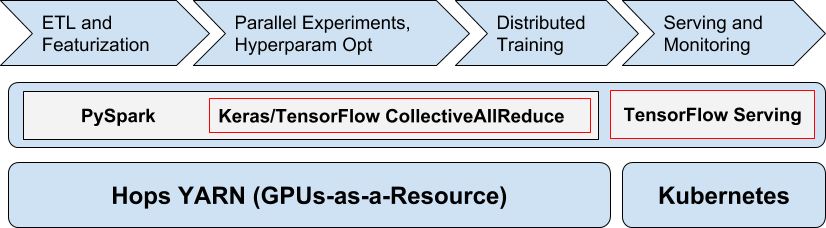
iDistributed Deep Learning Pipeline on Hopsworks
Hopsworks is a full stack Data Science platform that supports distributed deep learning, including Hyperparameter Optimization and Distributed training (see Spark Summit talk). Data Scientists can write end-to-end machine learning pipelines in PySpark, TensorFlow, Keras, PyTorch, and orchestrate multi-job pipelines in Airflow (DAGs written in Python). Hopsworks also supports model serving on Kubernetes, including TensorFlow serving server. In contrast to Google, who promote Apache Beam for the ETL stage of pipelines, we use PySpark in Hopsworks, both for ETL stages and for distributing both hyperparameter optimization and distributed training. PySpark works with Hops YARN to allocate GPUs for executors when they are needed for training DNNs.
Since late 2017, Hopsworks has supported Horovod for distributed training. This is despite the fact that Horovod builds on MPI, which is not natively supported by YARN. In Horovod, MPI transparently sets up the distributed infrastructure necessary for workers to communicate with each other - underneath YARN. This required coordination and cleanup by Hopsworks, resulting in complex, hard-to-maintain code with many failure edge cases (e.g., the Spark driver dies, but the MPI processes live on - Hopsworks now needs to cleanup - even if Hopsworks itself fails while cleaning up)).
In contrast, we were able to integrate TensorFlow CollectiveAllReduce into Hopsworks in a week’s work. We already had the PySpark framework in place, and we had already worked with building and exporting TF_CONFIG for each worker as part of our support for TensorFlowOnSpark (which we are also now deprecating).
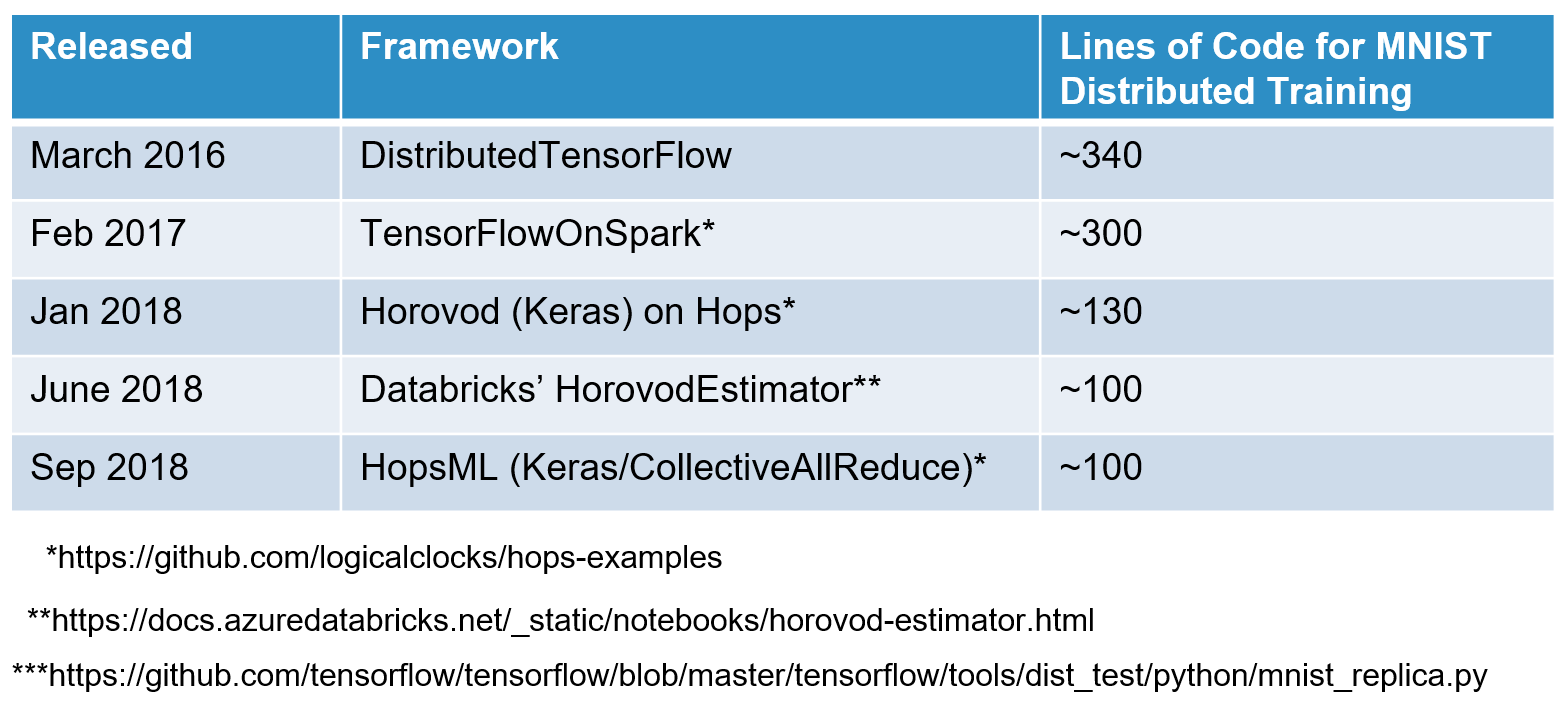
The number of lines of code required to write a MNIST distributed training example in TensorFlow is lower for AllReduce frameworks than for Parameter Server frameworks.
Summary
The deep learning community is moving fast, with new innovations appearing almost weekly. We, at Hopsworks, are keeping at the edge by being the first platform to support TensorFlow’s new CollectiveAllReduceStrategy. As part of bringing in the new, we’re leaving out the old, which means farewell to Horovod and TensorFlowOnSpark.