Hopsworks AI Lakehouse Now Supports NVIDIA NIM Microservices
Run thousands of LLMs with enterprise-grade reliability on your own infrastructure.
Hopsworks now supports NVIDIA’s new NIM microservices, letting you deploy thousands of Hugging Face LLMs - like Mistral and Llama - on your own infrastructure in just a few minutes.

We at Hopsworks are pleased to announce our integration with NVIDIA's newly released NVIDIA NIM capability, unveiled at GTC Paris. This advancement enables deployment of a broad range of LLMs from Hugging Face for enterprise-ready inference on NVIDIA accelerated infrastructure. One container, thousands of models, optimized automatically.
We've embedded this capability into the Hopsworks AI Lakehouse to address a critical challenge: making LLMs genuinely useful with real data, proper governance, and cost-effective infrastructure utilization.
What This Means
European enterprises pursuing AI sovereignty need practical solutions. The integration of Hopsworks with NIM microservices delivers:
- Your models, your infrastructure: Deploy Mistral, Llama, or specialized European language models your team has fine-tuned. On-premises, in your cloud, or hybrid deployments.
- Production-ready from day one: NVIDIA handles optimization automatically, selecting between TensorRT-LLM, vLLM, or SGLang based on model requirements.
- Real data integration: Your LLM connects directly to your feature store, real-time data pipelines, and knowledge graphs through the Hopsworks platform.
The Architecture
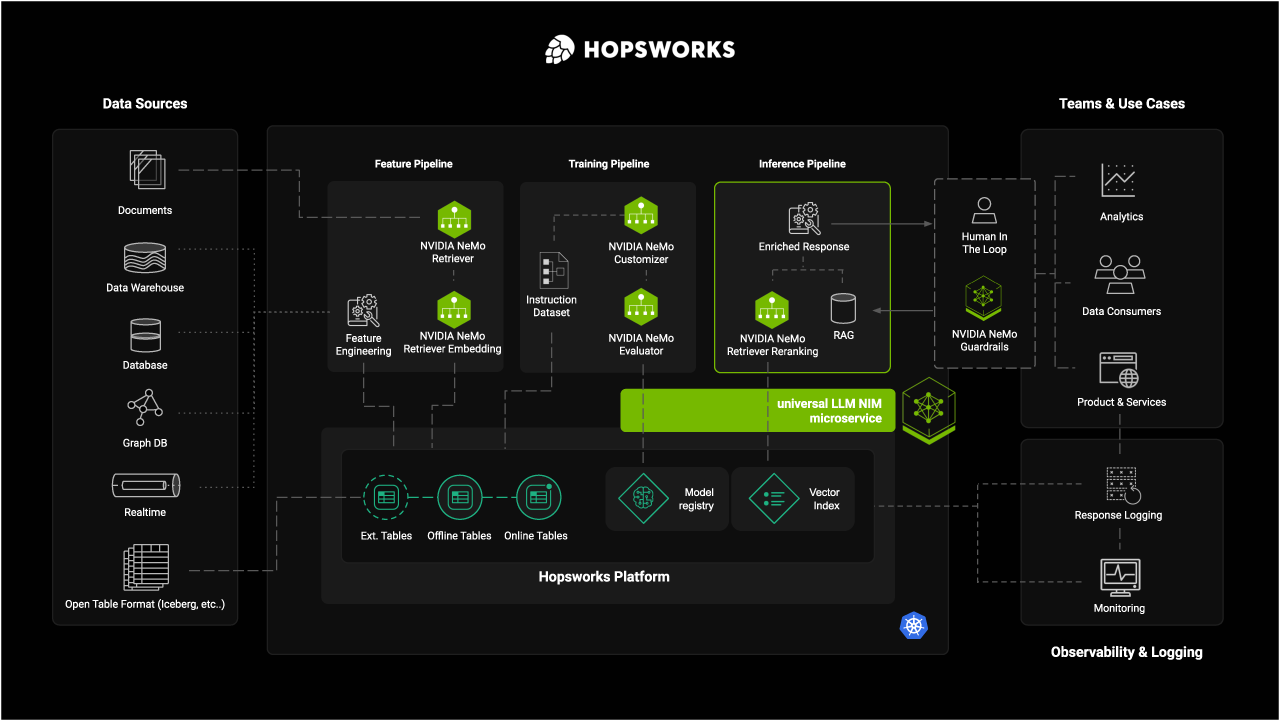
Image 1. Reference Arch - Nvidia Hopsworks GTC Paris
In the Hopsworks FTI architecture (feature, training, inference pipelines), the LLM (via a single NIM microservice container) operates within the inference pipeline, powered by:
- Feature Store: Real-time and historical context including user behavior, recent transactions, and domain-specific data,
- Vector Index: High-performance semantic search and RAG capabilities,
- Knowledge Graph: Structured relationships for enhanced reasoning.
The NIM microservice enables model switching without pipeline reconstruction. Change models via configuration, run A/B tests seamlessly.
Function Calling: Enhanced Capabilities
Function calling transforms LLM capabilities by enabling:
- Real-time feature store queries for user context
- Structured data retrieval from data warehouses
- Business logic execution through existing APIs
We've observed 10x accuracy improvements when LLMs access structured context compared to pure document retrieval.
Why This Works
- NVIDIA provides: Optimized inference, hardware acceleration, enterprise support for high-performance model serving.
- Hopsworks provides: Data pipelines, feature engineering, monitoring, governance - the infrastructure that transforms models into products.
- You maintain: Complete control over data, use cases, and compliance requirements.
Getting Started
Five minutes to deploy, another ten to connect your data.
Bottom Line
We're excited to bring this integration to our customers. Sovereign AI requires maintaining control, while leveraging best-in-class tools. NIM microservices provide access to a broad range of open models. Hopsworks makes those models production-ready with your data.
The combination delivers what enterprises need: flexibility, control, and reliability.
Learn more
- Try Hopsworks AI Lakehouse: run.hopsworks.ai
- NVIDIA NIM microservice for deploying a broad range of LLMs: build.nvidia.com
- Technical Documentation: docs.hopsworks.ai