The Coding Data & AI Stack
is generally available
Claude Code and Codex, inside the platform. Raw data to production AI in minutes.
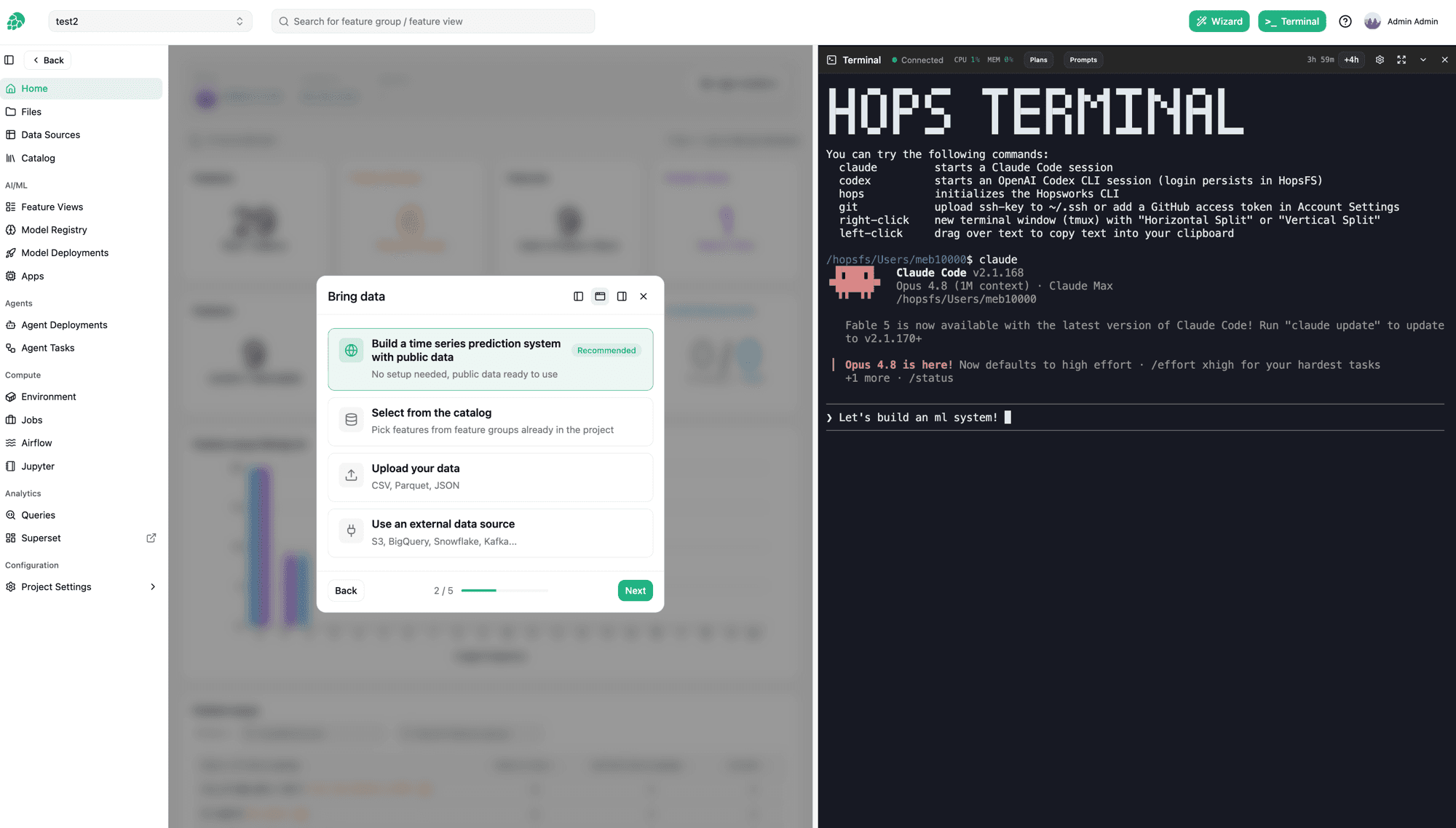
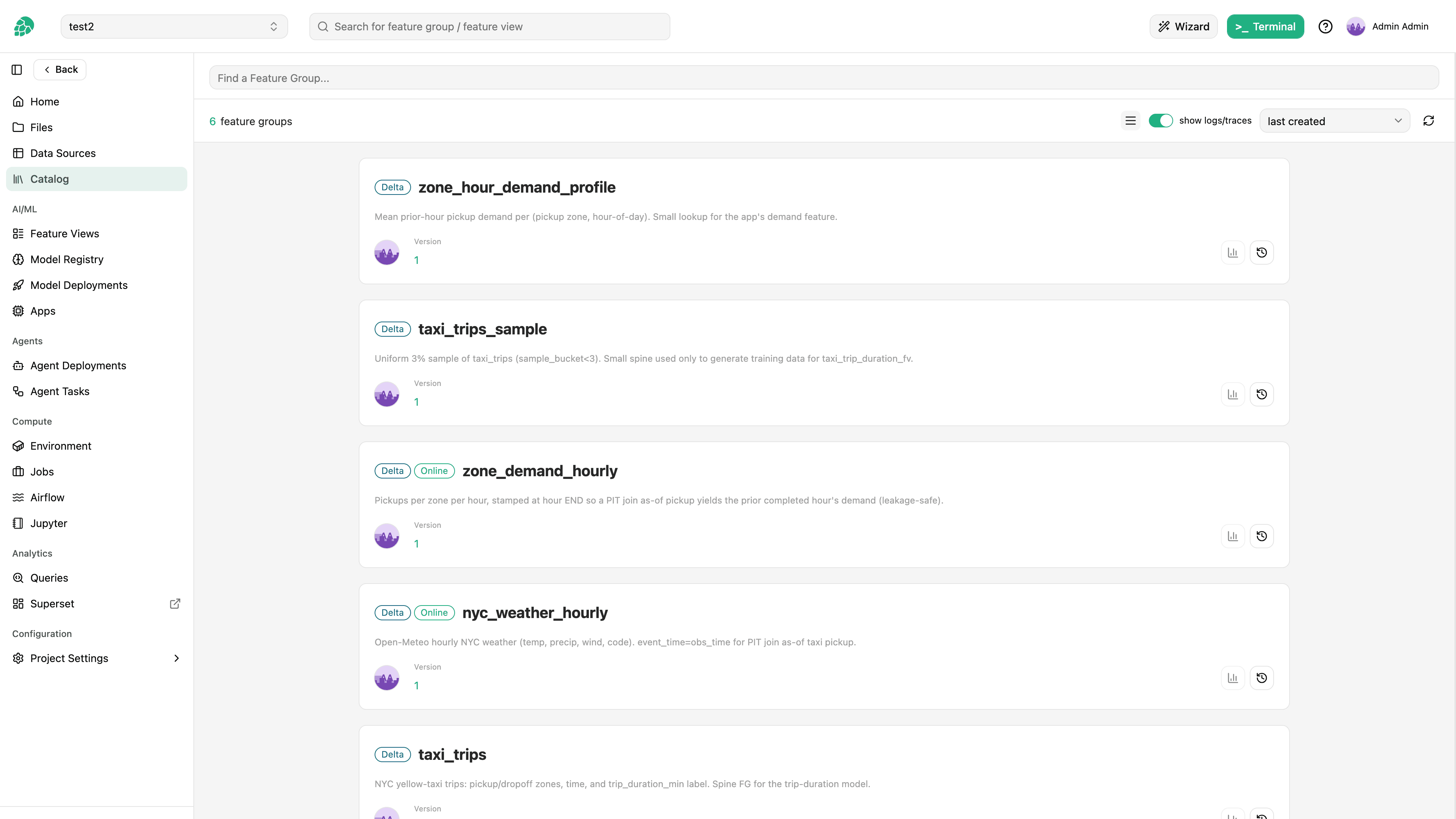
Feature Store
The backbone of production ML
<1ms
LATENCY
Central repository for feature data with sub-millisecond retrieval. Reuse features across models - Meta reports their top 100 features are used in over 100 models.
Sub-millisecond - Powered by RonDB
AI Lakehouse
Your data, your formats, AI-ready
9-45x
FASTER READS
Work directly with Iceberg, Delta, and Hudi tables. Python-native query engine with faster reads than Databricks or Sagemaker.
Open formats - Delta, Iceberg, Hudi
MLOps Platform
From experiment to production
10x
FASTER DEPLOYMENT
Complete lifecycle management for your ML models. Experiment tracking, model registry, and deployment pipelines in one unified platform.
End-to-End - Train, deploy, monitor
Trusted by leading AI teams
Built for Quality
Instant Data, Infinite Compute.
Real-time AI
Sub-millisecond latency with RonDB - the fastest open-source key-value store. SIGMOD 2024 benchmarks show 10x lower latency than Sagemaker and Vertex.
80%
cost reduction
by reusing features and streamlining development
Feature Freshness
Millisecond latency for end-to-end data retrieval with the best-in-class feature store.
GPUs at Any Scale
GPU and compute management for LLMs and other ML models. Maximize GPU utilization with smart scheduling and quota management. Train at scale with Ray, serve with KServe/vLLM.
The AI Lakehouse
Work directly with Delta, Iceberg, and Hudi tables. No migrations, no conversions.
Modular & Scalable
Spark, Flink, Pandas, DuckDB - use any framework. Start small, scale to petabytes.
Sovereign AI
Air-gapped, on-premises, hybrid. Full control over your data and AI operations.
Customer Stories
See how leading teams build AI with Hopsworks
Zalando
Europe's largest online fashion platform reveals how they built a mission-critical ML infrastructure using Hopsworks to power real-time personalization across 25 countries and 50 million customers.
Clicklease
Learn how Clicklease revolutionized their micro-lease approval system using Hopsworks Feature Store - going from a messy microservice architecture with training-production skew to a streamlined ML platform powering real-time fraud detection and credit decisioning.

Building Machine Learning Systems
Batch, Real-Time, and LLM Systems
Learn how to build production ML systems with a unified architecture. From feature pipelines to real-time inference and LLM applications.
Get Started with Tutorials
Production-ready examples to kickstart your AI projects.
Batch AI Systems
Feature pipelines, training pipelines, and batch inference for fraud detection, churn prediction, and more.
Real-Time AI Systems
Online inference with sub-millisecond feature retrieval. Credit card fraud, real-time recommendations.
LLM AI Systems
RAG pipelines, embedding management, and LLM-powered applications with feature store integration.
Ready to get started?
Join teams building production ML systems with Hopsworks.