ROI of Feature Stores
This blog analyses the cost-benefits of Feature Stores for Machine Learning and estimates your return on investment with our Feature Store ROI Calculator.

When you invest money in machine learning (ML), you typically start by investing in people. You hire data scientists, data engineers, and ML engineers to transform your data into insights that can help you both reduce costs and increase revenue. However, if you do not manage the ML assets you create (the feature engineering jobs, the feature data, the models, and the CI/CD pipelines), the cost of each ML project will be roughly constant - every new project will start over from scratch and your ML - readiness will grow slower that the leading companies in your field. That is because the leading ML companies have all invested in building a data platform for ML (aka a feature store).
In this blog, we make a cost-benefit analysis for a Feature Store for ML, identifying some of the cost reductions and productivity improvement metrics they bring:
- reduced cost of ML projects through feature reuse;
- reduced time-to-market for models;
- reduced cost of ML operations through more efficient feature engineering;
- reduced model risk by early detection of bias in data. .
Reduced cost of ML projects through feature reuse
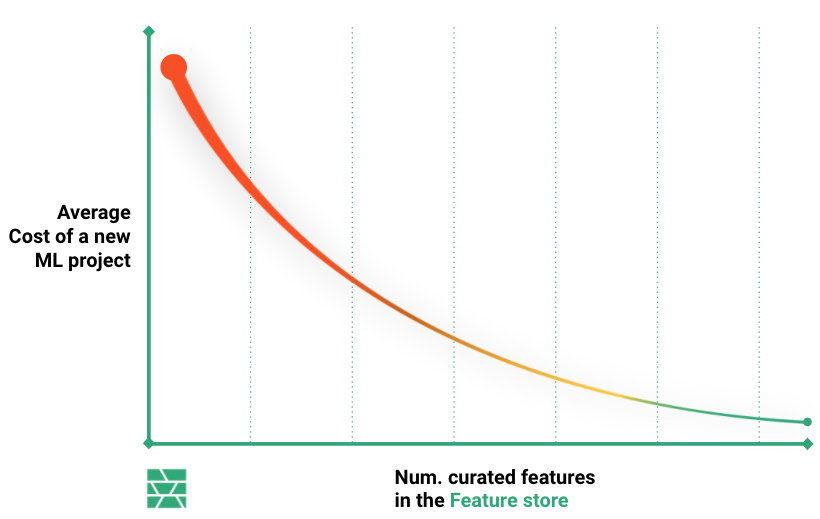
The cost of performing the first few ML projects will not be substantially reduced if a company has a feature store. However, as more engineered features become available in the feature store, they can be reused by different teams in many different ML pipelines. As it has been estimated that 80% of the effort of ML projects is feature engineering, the reuse of features leads to substantial reductions in the cost of both developing and maintaining ML projects. With a well-populated feature store, organizations can expect to be able to productionize many more models at much reduced cost with fewer data scientists.

Twitter evaluates the success of their feature store based on how widely features are shared across teams.
Reduced time-to-market for models
As 80% of the effort of ML projects is typically feature engineering, the availability of ready-made features in the feature store enables organizations to release models in significantly less time than if no feature store is available. The feature store also reduces the time needed by eliminating the need for exploratory data analysis (EDA), as feature distributions and descriptive statistics are precomputed and available in the feature store. On top of this, there is an improved division of labor. Data engineers are more skilled at writing features pipelines for ingesting and transforming raw data from backend databases, data warehouses, and data lakes, and this increases the time available for data scientists to develop more models and better models.
Reduced cost of ML Operations through more efficient feature engineering
A feature store gives an immediate 50% reduction in the cost of maintaining feature engineering pipelines for online applications, as only one feature pipeline is needed to fill both the online and offline feature stores, not two. Without a feature store, features are computed (and often implemented) twice: once to serve features to the online application (performing model inference) and once to build train/test datasets for training models. Without a feature store, you can expect increased operational costs to ensure the consistency of both implementations of the features (serving and training). This consistency problem is technical debt that can be paid down ahead of time by having a feature store.
Reduced model risk by early detection of bias in data
“Data is biased..But learning algorithms themselves are not biased...Bias in data can be fixed.”
Yann Le Cunn on how to tackle the bias problem in ML
When features have not been battle-tested and validated, there is a risk that features will either reveal sensitive information or models will introduce biased predictions (for example, predictions on slices of the data will perform differently than others). For example, models that produce different prediction results based on the race or gender of users are particularly high-risk for consumer companies.
A feature store, integrated into a ML pipeline can provide early warning for anomalies in training and serving data. One mechanism is to automate the identification and notification of feature drift - anomalous changes in the values or distribution of feature values. The feature store also enables Data Scientists to more easily build more extensive experiments analyzing models and linking the performance or bias of models to individual features from the feature store.
Hopsworks Feature Store
The Hopsworks Feature Store enables teams to work effectively together, sharing outputs and assets at all stages in ML pipelines. In effect, our Hopsworks Feature Store:
- acts as an API between Data Engineering and Data Science, enabling improved collaboration between Data Engineers, who engineer the features, with Data Scientists, who use the features to train models;
- enables features to be registered, discovered, validated, and used as part of ML pipelines, thus making it easier to transform and validate the training data that is fed into machine learning systems;
- meets traditional Enterprise Computing requirements with support for access control, feature versioning, governance (e.g., terms of use), model interpretability, privacy, and auditing;
- is horizontally scalable and highly available;
- fits seamlessly into existing development environments and ML pipelines – whether you are in the cloud or on-premises, with integrations for Databricks, AWS Sagemaker, and Kubeflow.
Summary
To summarize, a way to look at the value that a feature store can bring is shown in the table below.