How to transform Amazon Redshift data into features with Hopsworks Feature Store
Connect the Hopsworks Feature Store to Amazon Redshift to transform your data into features to train models and make predictions.

Introduction
Amazon Redshift is a popular managed data warehouse on AWS. Companies use Redshift to store structured data for traditional data analytics. This makes Redshift a popular source of raw data for computing features for training machine learning models.
The Hopsworks Feature Store is the leading open-source feature store for machine learning. It is provided as a managed service on AWS and it includes all the tools needed to transform data in Redshift into features that will be used when training and serving ML models.
In this blog post, we show how you can configure the Redshift storage connector to ingest data, transform that data into features (feature engineering) and save the pre-computed features in the Hopsworks Feature Store.
Prerequisites
To follow this tutorial users should have an Hopsworks Feature Store instance running on Hopsworks. You can register for free with no credit-card and receive 300 USD of credits to get started.
Users should also have an existing Redshift cluster. If you don't have an existing cluster, you can create one by following the AWS Documentation.
Step 1 - Configure the Redshift Storage Connector
The first step to be able to ingest Redshift data into the feature store is to configure a storage connector. The Redshift connector requires you to specify the following properties. Most of them are available in the properties area of your cluster in the Redshift UI.
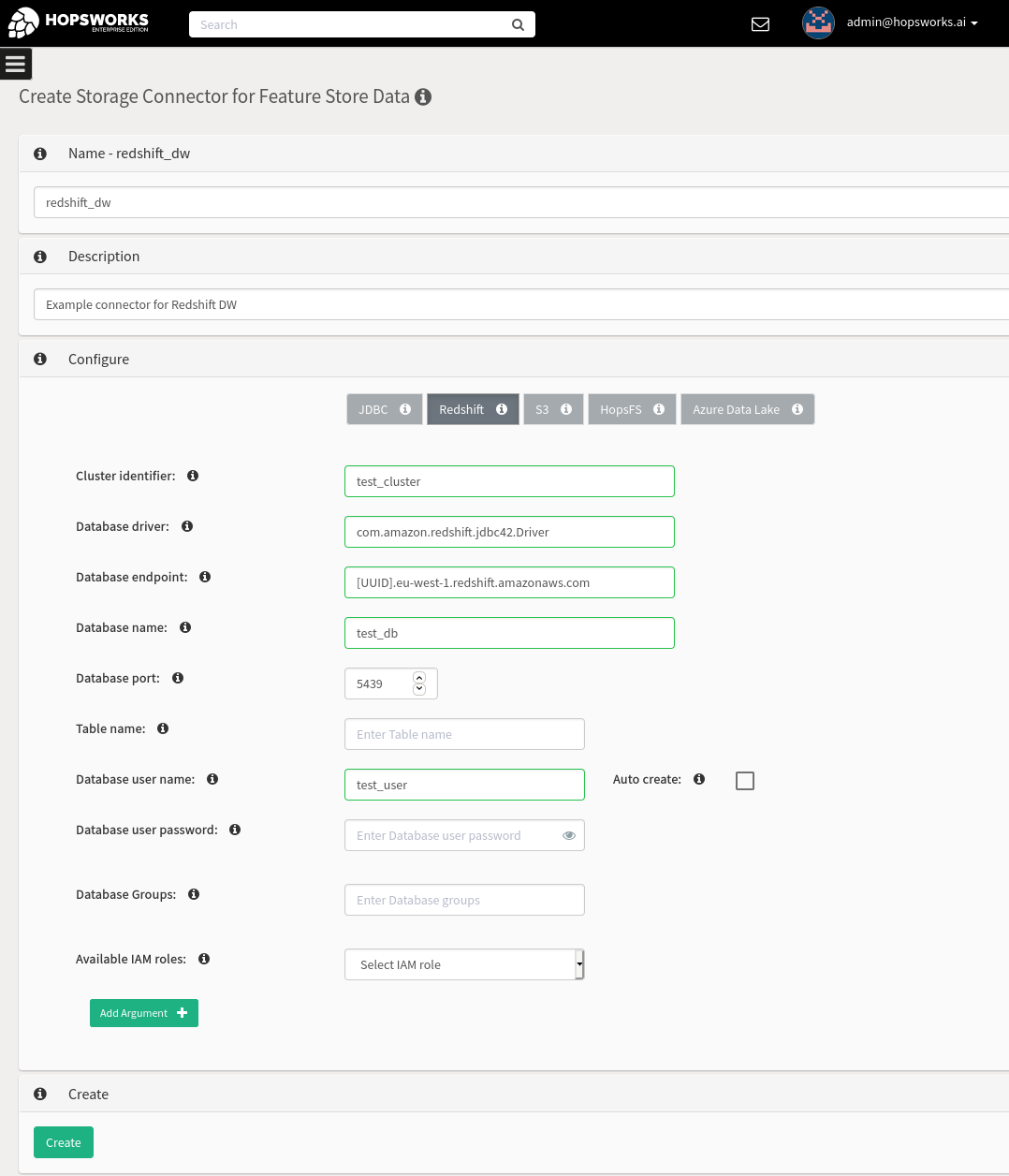
- Cluster identifier: The name of the cluster
- Database driver: You can use the default JDBC Redshift Driver `com.amazon.redshift.jdbc42.Driver` (More on this later)
- Database endpoint: The endpoint for the database. Should be in the format of `[UUID].eu-west-1.redshift.amazonaws.com`
- Database name: The name of the database to query
- Database port: The port of the cluster. Defaults to 5349
There are two options available for authenticating with the Redshift cluster. The first option is to configure a username and a password. The password is stored in the secret store and made available to all the members of the project.
The second option is to configure an IAM role. With IAM roles, Jobs or notebooks launched on Hopsworks do not need to explicitly authenticate with Redshift, as the HSFS library will transparently use the IAM role to acquire a temporary credential to authenticate the specified user.
In Hopsworks, there are two different ways to configure an IAM role: a per-cluster IAM role or a federated IAM role (role chaining). For the per-cluster IAM role, you select an instance profile for your Hopsworks cluster when launching it in Hopsworks, and all jobs or notebooks will be run with the selected IAM role. For the federated IAM role, you create a head IAM role for the cluster that enables Hopsworks to assume a potentially different IAM role in each project. You can even restrict it so that only certain roles within a project (like a data owner) can assume a given role.
With regards to the database driver, the library to interact with Redshift *is not* included in Hopsworks - you need to upload the driver yourself. First, you need to download the library from here. Select the driver version without the AWS SDK. You then upload the driver files to the “Resources” dataset in your project, see the screenshot below.
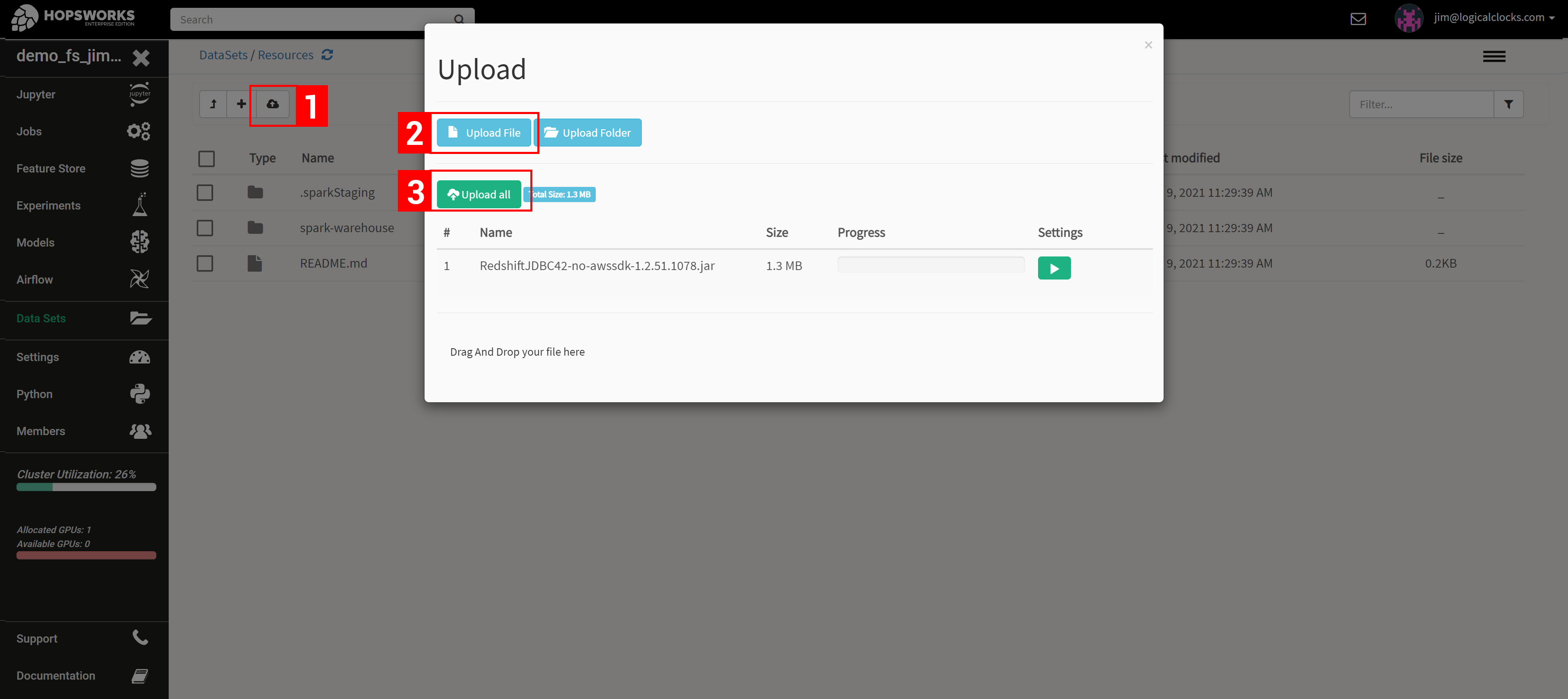
Upload the Redshift Driver (jar file) from your local machine to the Resources dataset.
Then, you add the file to your notebook or job before launching it, as shown in the screenshots below.
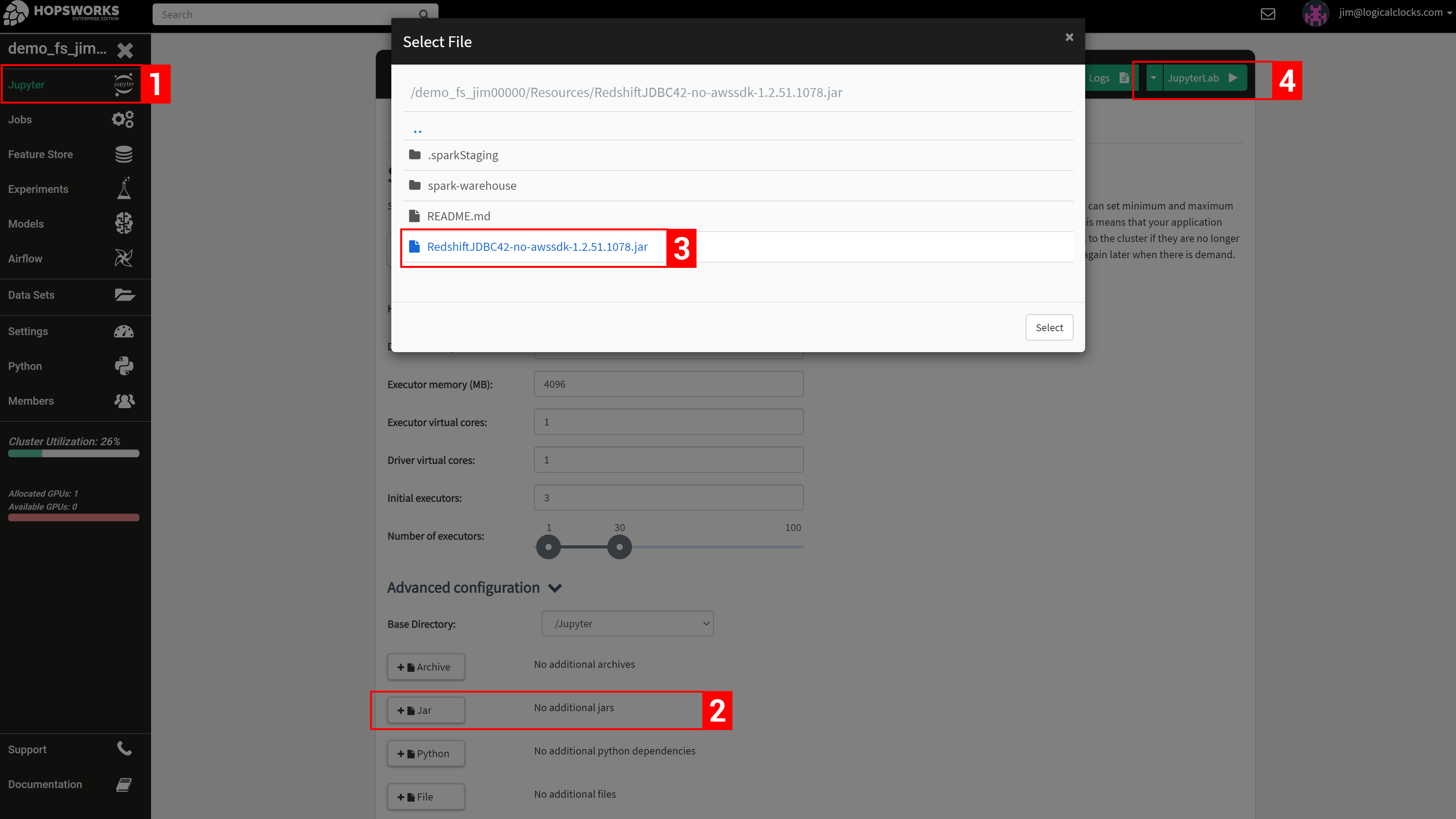
Before starting the JupyterLab server, add the Redshift driver jar file, so that it becomes available to jobs run in the notebook.
Step 2- Define an external (on-demand) Feature Group
Hopsworks supports the creation of (a) cached feature groups and (b) external (on-demand) feature groups. For cached feature groups, the features are stored in Hopsworks feature store. For external feature groups, only metadata for features is stored in the feature store - not the actual feature data which is read from the external database/object-store. When the external feature group is accessed from a Spark or Python job, the feature data is read on-demand using a connector from the external store. On AWS, Hopsworks supports the creation of external feature groups from a large number of data stores, including Redshift, RDS, Snowflake, S3, and any JDBC-enabled source.
In this example, we will define an external feature group for a table in Redshift. External feature groups in Hopsworks support “provenance” in the Hopsworks Web UI, you can track which features are stored on which external systems and how they are computed. Additionally HSFS (the Python/Scala library used to interact with the feature store) provides the same APIs for external feature groups as for cached feature groups.
An external (on-demand) feature group can be defined as follow:
When running `save()` the metadata is stored in the feature store and statistics for the data are computed and made available through the Hopsworks UI. Statistics helps data scientists in the quest of building better features from raw data.
Step 3 - Engineer features and save to the Feature Store
On-demand feature groups can be used directly as a source for creating training datasets. This is often the case if a company is migrating to Hopsworks and there are already feature engineering pipelines in production writing data to Redshift.
This flexibility provided by Hopsworks allows users to hit the ground running from day 1, without having to rewrite their pipelines to take advantage of the benefits the Hopsworks feature store provides.
On-demand feature groups can also be joined with cached feature groups in Hopsworks to create training datasets. This helper guide explains in detail how the HSFS joining APIs work and how they can be used to create training datasets.
If, however, Redshift contains raw data that needs to be feature engineered, you can retrieve a Spark DataFrame backed by the Redshift table using the HSFS API.
You can then transform your `spark_df` into features using feature engineering libraries. It is also possible to retrieve the dataframe as a Pandas dataframe and perform the feature engineering steps in Python code.
You can then save the final dataframe containing the engineered features to the feature store as a cached feature group:
Storing feature groups as cached feature groups within Hopsworks provides several benefits over on-demand feature groups. First it allows users to leverage Hudi for incremental ingestion (with ACID properties, ensuring the integrity of the feature group) and time travel capabilities. As new data is ingested, new commits are tracked by Hopsworks allowing users to see what has changed over time. On each commit, statistics are computed and tracked in Hopsworks, allowing users to understand how the data has changed over time.
Cached feature groups can also be stored in the online feature store (`online_enabled=True`), thus enabling low latency access to the features using the online feature store API.
Get started
Get started today on Hopsworks.ai by configuring your Redshift storage connector and run this notebook.