MLOps Wars: Versioned Feature Data with a Lakehouse
With support to Apache Hudi, the Hopsworks Feature Store offers lakehouse capabilities to improve automated feature pipelines and training pipelines (MLOps).

The MLOps Wars series of articles chronicles the struggles that you, as a Data Scientist/Engineer, must surmount to bring your machine learning models to production. This first article covers the challenge of working with versioned data.
Introduction
Machine Learning Operations (MLOps) is a process that applies DevOps principles to automate the building, testing, and deployment of machine learning (ML) models through its entire life cycle. However, in contrast to DevOps, MLOps has to deal with versioned data, not just versioned code. When new data becomes available, we may want to trigger automated feature pipelines to compute the new feature data, keeping features as fresh as possible. The availability of new feature data may, in turn, trigger training pipelines to build and deploy new models that include the new feature data.
Given that feature data for training models is stored in the offline feature store, how can a feature store know about the availability of new feature data for training models?
Firstly, we will look at how feature data is made available in Hopsworks as Feature Groups (tables containing sets of features). In Hopsworks, we support two sources for this offline feature data:
- external tables from databases like Snowflake, Delta Lake, JDBC sources can be mounted as on-demand Feature Groups, and
- cached Feature Groups are stored as Apache Hudi tables (parquet files with additional metadata, stored in S3 or Azure Blob Storage using HopsFS).
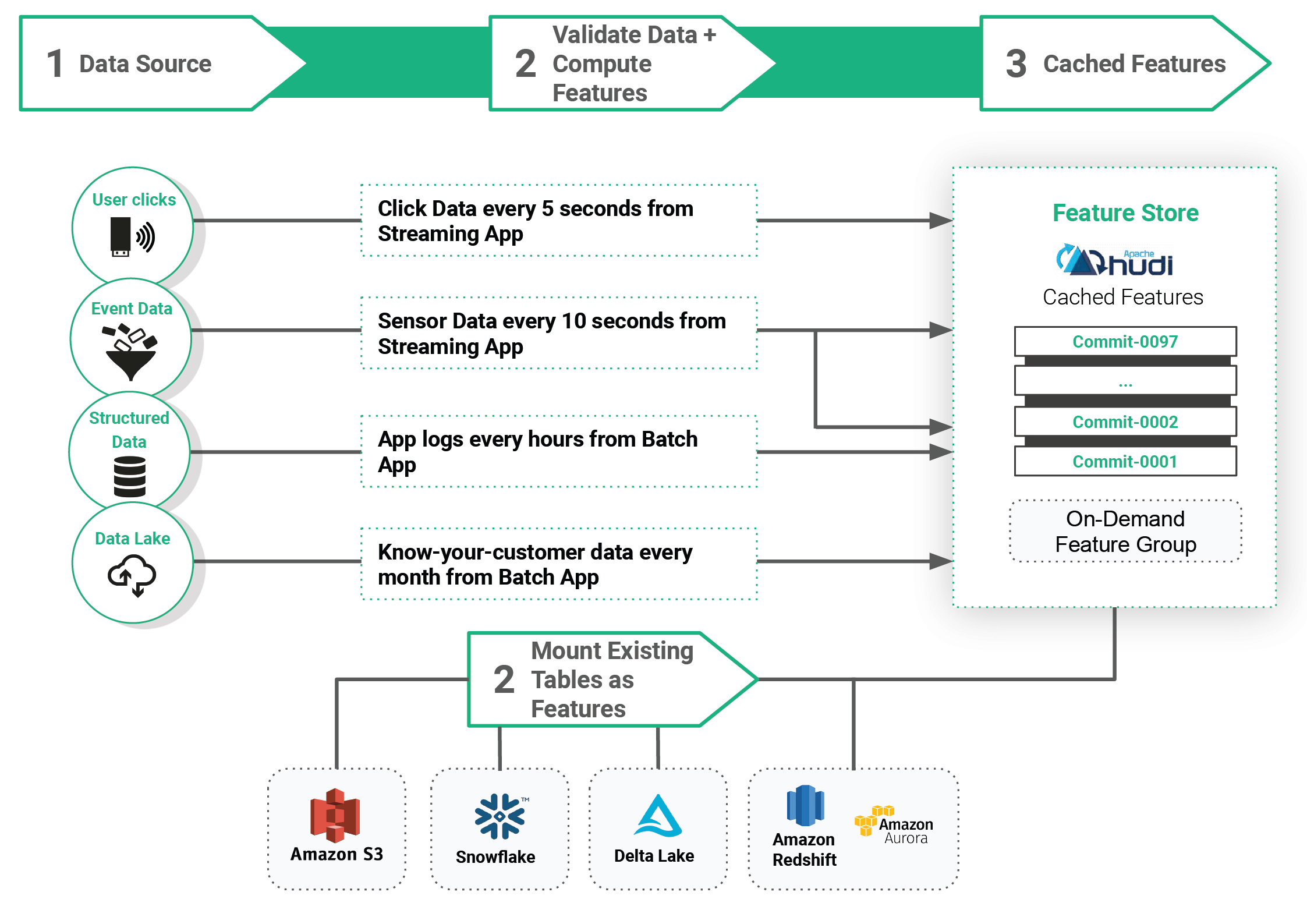
Figure 1. Feature Data as Feature Groups
Offline features include the historical values of features and are used to (1) create training datasets and (2) score batch applications with analytical models. When you join features together to create training datasets, you can transparently mix features from on-demand Feature Groups and cached Feature Groups. For completeness, online features (the latest feature data values that are served to online models) are stored in RonDB - the world’s fastest key-value store with SQL capabilities.
How do you decide between storing offline features as external tables or cached features? Well, you may already have a feature engineering pipeline in Snowflake that outputs engineering features to a table in Snowflake. You can just mount that table containing the engineered features into Hopsworks as an on-demand Feature Group - only metadata is stored in Hopsworks. Sometimes, however, you will engineer features in either Spark or Python. In this case, you can write your features to the Hopsworks Feature Store directly using the hsfs API. In this case, the offline features are stored in Hopsworks as cached Feature Groups (Hudi tables). Apache Hudi enables reproducible, reliable machine learning pipelines - including support for versioned data, ACID updates/deletes, incremental ingestion, and time-travel. In particular, for MLOps, Hudi enables us to identify when feature data in a cached Feature Group has changed - which you can use to trigger a training pipeline(s).
Extending the Feature Store for MLOps
For cached Feature Groups, feature pipelines keep features up-to-date by either executing on a schedule or in response to an event such as the arrival of new data. In Hopsworks, you can plug in your own pipeline orchestration tool of choice, or use Airflow that comes packaged with Hopsworks.
Modern feature pipelines written in Python, Spark, or Flink store their output features in low-cost object storage that supports efficient querying, incremental writes/updates/deletes of data, and ACID updates. The main storage frameworks/formats that support these properties are known as lakehouses: Apache Hudi, Delta Lake, and Apache Iceberg. Delta lake, supported by Databricks, is perhaps the best known, but the open-source version is not yet feature-complete compared to Databrick’s version. As of July 2021, OSS Delta Lake lacks the following proprietary features: auto compaction, key indexing using Bloom Filters, and Z-Ordering for better file pruning at read time, Therefore, we chose our first file format to be Apache Hudi. You can track our work on adding OSS Delta support here.
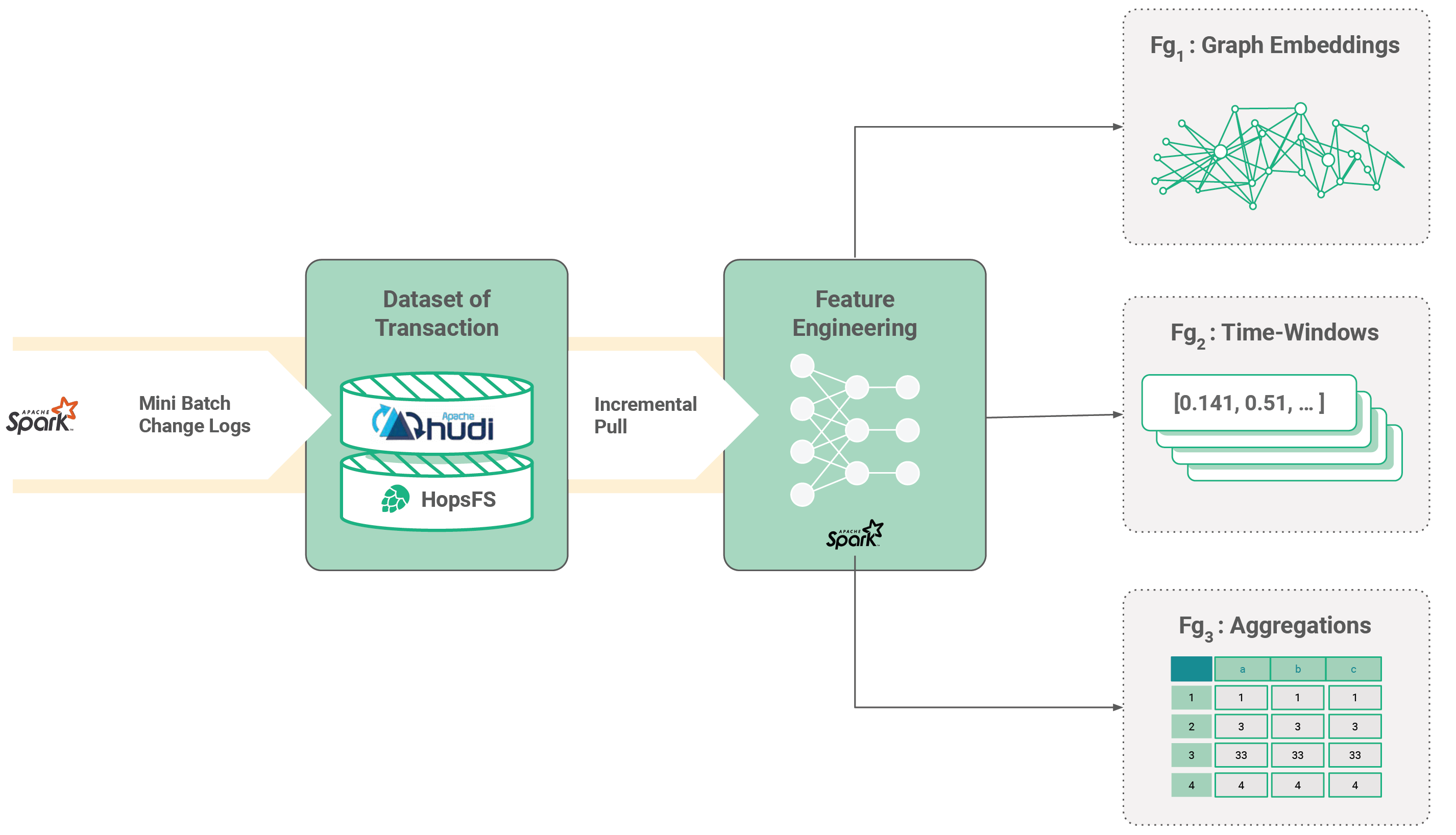
Figure 2. Feature Group stored in Hudi.
In the above diagram, we can see how derived Feature Groups are computed from a base Feature Group stored in Hudi. When new data arrives in the Hudi table, a feature pipeline can pull the incremental changes and update the features for all derived Feature Groups.
Lakehouse formats add extra capabilities to Feature Groups that are key for MLOps: version and temporal information about updates to tables in a commit log (containing the row-level changes to tables). In the above diagram, we can see how this enables feature pipelines that compute changes to derived Feature Groups, when their upstream Feature Groups have changed.
Another useful capability is support for time travel queries, that is, retrieve feature data from a Feature group for a given point-in-time or retrieve all changes in feature data for a given time interval.
Hopsworks Feature Store adds temporal and data-versioning capabilities to Feature Groups using Apache Hudi. Hudi supports Spark, Flink, Presto and Hive as "compute engines", and as of Hopsworks 2.2., we only support Spark, but support for Flink is coming soon.
Data Versioning with Time-Travel Queries and Incremental Pulling
To illustrate the importance of data versioning and time travel capabilities, let's take a hypothetical example from an e-commerce store. We are tasked to create Feature Groups of orders and product views that will be used to create recommendation engines and business reports.
Below code snippet shows how to create a Feature Group metadata object and then register it to the Hopsworks feature store, along with the corresponding dataframe. We are going to set the time travel format to “HUDI” and provide column names that will be used as primary keys. Apache Hudi requires primary keys to uniquely identify each record.
The following code snippet can be run in either Python (with a Pandas Dataframe) or in PySpark (with a Spark Dataframe):
These two Feature Groups are updated at different cadences: product catalog is updated monthly while product views receive e-commerce streams in micro batches every five minutes. When new data arrives we are able to add it to existing Feature Groups using insert method:
Streaming data involves handling duplicate events, data insertions and updates, as well as reinstating late arriving data. In our hypothetical example first batch of product orders contains data from 2021-06-22 23:35:34 to 2021-06-22 23:55:00

The second batch contains data from 2021-06-23 00:05:08 to 2021-06-23 00:15:56

As you can see, the second microbach contains a late arrival event from 2021-06-22 23:59:00. We partitioned our Feature Groups based on hour of event time and Apache Hudi will update partition 2021-06-22-23, while in case of non time travel enabled Feature Groups we might have been forced to overwrite the 2021-06-22-23 partition or the entire dataset. We would have ended in the same situation if the microbatch contained a duplicated event.
In time travel enabled Feature Groups every write operation is automatically versioned. During the insert call if values of primary and partition key combination matches that of already existing ones then rest of the corresponding feature values will be “UPDATE”-d, otherwise an “INSERT” operation will be performed. This is called the “UPSERT” - a combination of “UPDATE” and “INSERT”.
When you define a Feature Group using hsfs, you can enable the computation of statistics for that Feature Group. In this case, for every commit, hsfs will compute statistics over the data being ingested and all the data in the Feature group, and it will store it together with other commit metadata, such as number of rows inserted, updated and/or deleted as an activity timeline.
In Hopsworks, the feature store activity timeline metadata is accessible both from UI and hsfs.
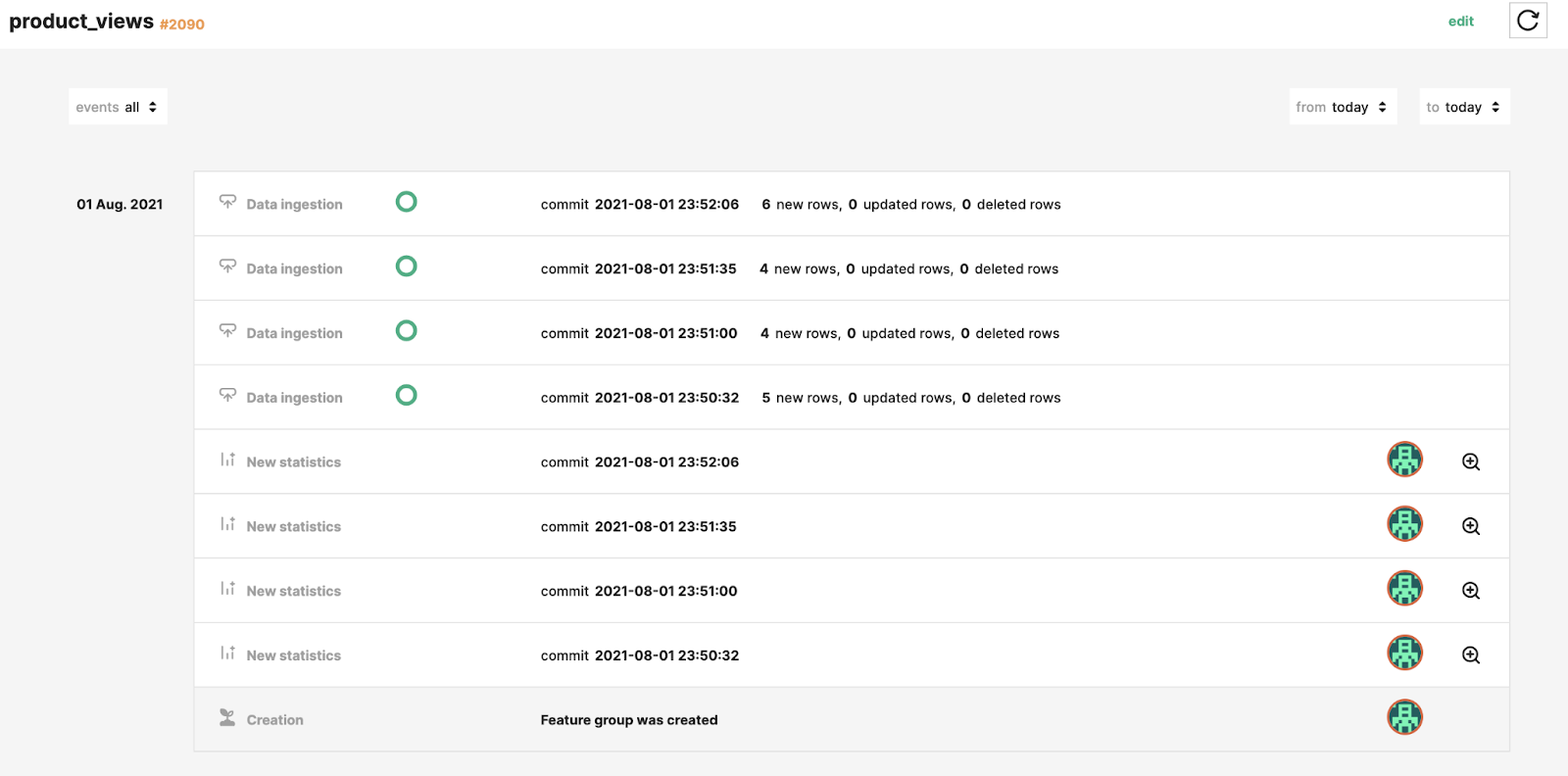
Figure 3. Hopsworks Feature Groups
From hsfs user can call the commit_details() method on Feature Group object to access its commit details:
Another type of update operation is to delete a record(s) from a Feature Group. This is achieved by calling delete_commit() method with a data frame containing primary keys on the hudi time travel enabled Feature Group. The following code snippet will delete records of user with id 524325294 from product views Feature Group:
Polling for Data-Change Triggers in MLOps
Time-based triggers are always available in orchestration platforms, such as Apache Airflow, where a feature engineering or training pipeline can be scheduled to run at a user-specified interval, e.g., hourly or daily. In contrast, data-change triggers can be used to run pipelines if data in a Hudi table is changed, for example.
Polling Triggers for Pipelines
A client can easily track changes in Feature Groups by storing the most recently processed commit-id for a Feature Group, and then polling for changes.
If the client itself does not maintain state, this can be easily offloaded to Hopsworks using custom tags. For example, if an Airflow DAG polls to check if a new training dataset needs to be created, it can get the latest training dataset version and retrieve the commit-ids for the constituent Feature Groups from the training dataset metadata. It can then compare these commit-ids with the current commit-ids for the Feature Groups, and if a commit-id has changed since the training dataset was built, the logic in your DAG can decide on whether it should recompute a new training dataset or not. As training datasets are immutable, they do not have commit-ids, but instead they have different versions. Similarly, a training pipeline could poll and wait for the appearance of a new training dataset before model training is run.
The following code snippet shows Airflow sensor class for feature group commits. Commit-id from previous training DAG will be saved and if polling identifies a higher commit-id in the current DAG, then it will trigger a pipeline to train a new model with a new version of the training dataset.
Exploratory Data Analysis on time travel enabled Feature Groups
Data scientists may want to look into what happened from point in time A to point in time B and perform exploratory data analysis using time travel queries for debugging and analysing model performance. Business analysts may want to create time series reports.
By default if we don’t specify any point in time the feature store will return the latest snapshot of the Feature Group. This is called Snapshot Query:
Incremental queries provide a way to retrieve data from a given commit or point in time and perform incremental feature engineering. In Hopsworks feature store incremental reads are performed by calling read_change method on Feature Group metadata object:
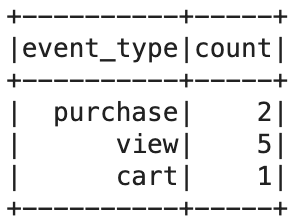
Feature Store is about sharing and reusing features and JOINs enable Feature Reuse. Hopsworks' Feature Store enables users to join Feature Groups that correspond to specific points in time by calling the as_of() method on the Query object. In the following example we are going to join products and product orders Feature Groups that correspond to time as of 2021-06-23 00:15:00.
It is also possible to join Feature Groups that correspond to join Feature Groups that correspond different points in time. For example we may want to join the product Feature Group as of point in time 2021-06-23 00:15:00 to the product orders Feature Group that corresponds to point in time 2021-06-23 00:00:00. In this case one can call as_of separately on each Feature Group and then join them.
Summary
In this article, we described how cached Feature Groups in the Hopsworks Feature Store support time-travel (data-versioning), atomic and incremental upserts using Apache Hudi. These are key enabling properties for a Feature Store as part of an end-to-end MLOps framework - enabling incremental feature engineering, reproducible creation of training datasets, change-data-capture support for when to recompute derived Feature Groups, training datasets, and when to run batch analytics pipelines.
Get started
Get started today on hopsworks.ai by using Hopsworks Feature Store and performing time travel queries with this notebook.