Show me the code; how we linked notebooks to features
We are introducing a new feature in Hopsworks UI - feature code preview - ability to view the notebook used to create a Feature Group or Training Dataset.
Introduction
A key capability of feature stores is that they enable users to understand their features; where features come from - both the source of their data and the code used to create the features. Since Hopsworks version 1.2, users have been able to see which compute jobs run in the Hopsworks platform create which Feature Groups. However, an increasing number of users are running their feature engineering code on Jupyter notebooks and on external platforms, such as Databricks. To this end, we have introduced new functionality in the Feature Store UI, where you can view the notebook code used to create features or training data directly in the Feature Registry.
This new quick feature code view will help data scientists become more productive when they are in the EDA (exploratory data analysis) phase of their work. They will not have to navigate to a source code repository or Jobs UI to understand how a feature is computed. This new capability is part of our ongoing effort to make the Hopsworks Feature Store the most open and modular feature store on the market. Not only do we support the widest number of platforms for feature engineering (Python, Spark, SQL), but we also support the widest number of data sources, where you can store features computed from data stored in many different data platforms, including data warehouses, databases, object stores, graph databases, message buses, and free-text search databases. You do not have to bring your data for AI to a single data warehouse to be able to use our feature store. Keep the data in place, and centralize the features computed from it.
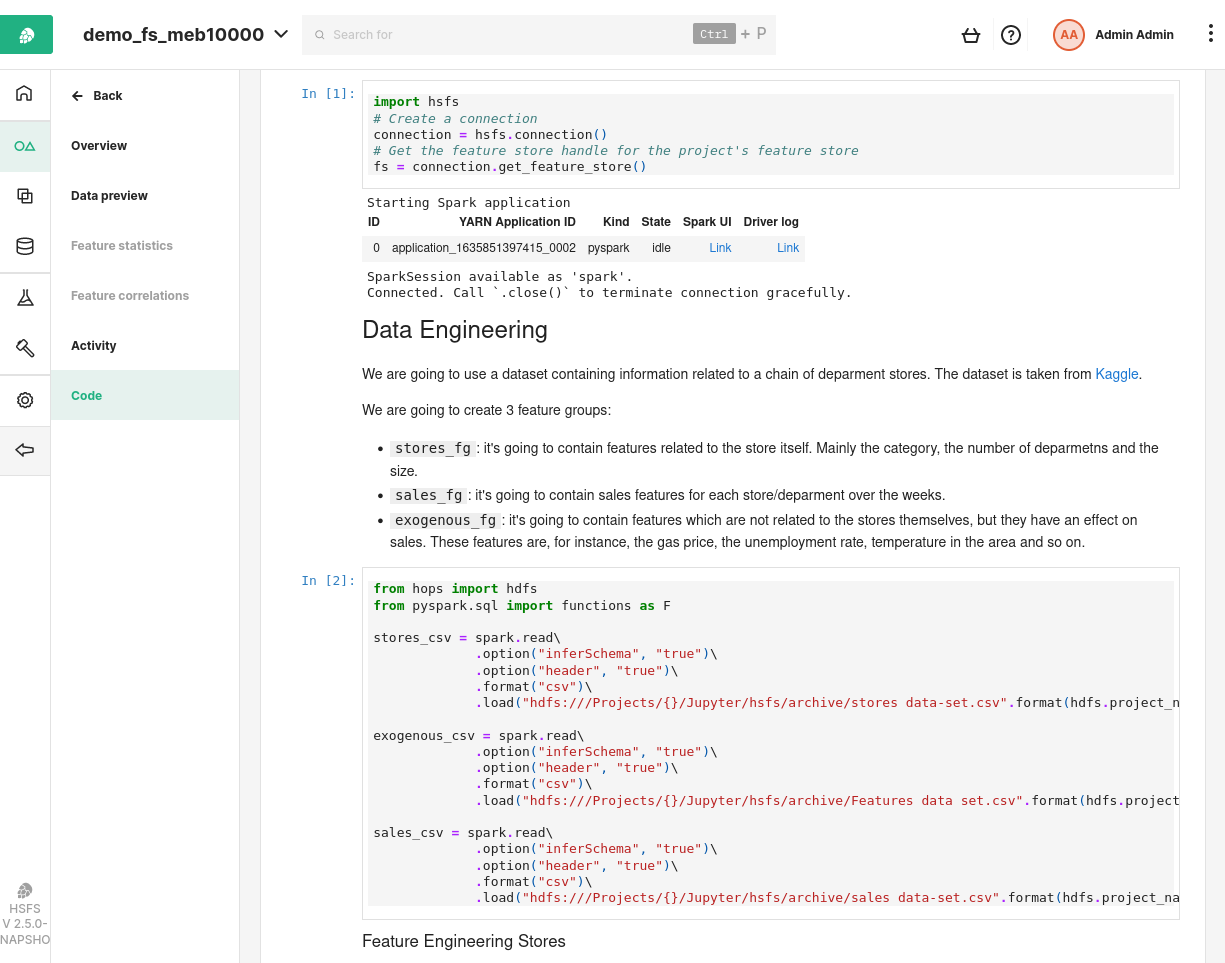
Figure 1. New Code View Feature
How you compute features for Hopsworks
Hopsworks supports general-purpose programming languages and frameworks for computing features, including Python/Pandas, Apache Spark (PySpark, Scala/Java, SQL), and Apache Flink. You can work with your existing workflow orchestrator tool (Hopsworks comes with Airflow built-in, but you can use an external Airflow, Dagster, Azure Data Factory, Jenkins and many more).
Hopsworks does not force you to define your features in a domain specific language (DSL). We meet you where you like to work - write your feature pipeline as a program in any Python/Spark/SQL environment. Extracting the feature computation code from a DSL is a straightforward task. However, as we support general purpose compute frameworks for feature computation, we had to solve the more general problem of storing and attaching the code for the notebook to the features in the feature store.
A code snippet in Python is shown below that uses the hsfs API (Hopsworks Feature Store) to write a dataframe to a feature group. First, we read data into a Pandas dataframe from a bucket in s3, then we perform feature engineering on the dataframe (elided for brevity), and the dataframe is finally saved to the feature group - an ACID update on the Hudi table for the offline feature store.
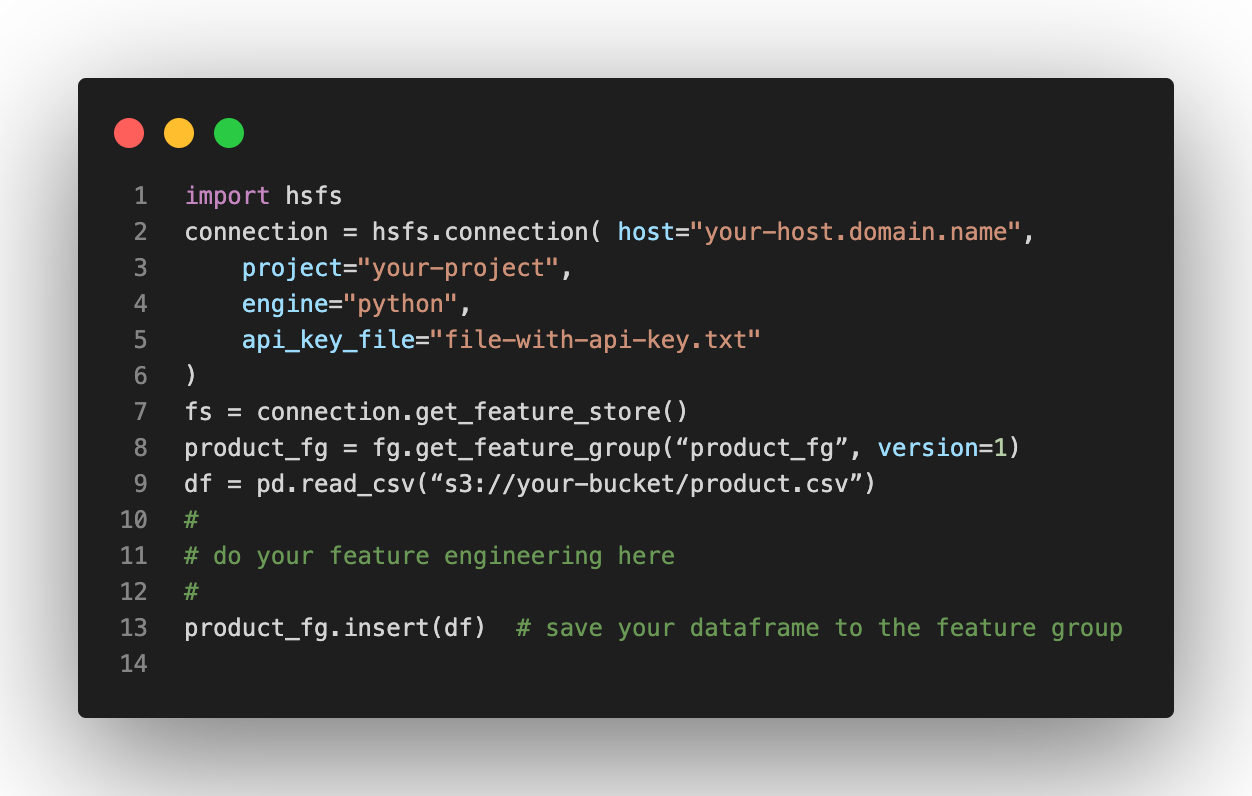
Figure 2. Hsfs API to write a dataframe to a feature group
Notebook Snapshots and Time-Travel in Hudi-enabled Feature Groups
The feature group shown in the code above stores its historical feature values in an offline feature store - a Hudi table. Hudi is a file format that extends Parquet to give it ACID properties and time-travel capabilities. Our new feature code preview functionality works as follows. Every time we update a feature group, we snapshot the notebook (Jupyter in Hopsworks or Databricks notebook), and store it alongside the Hudi commit.
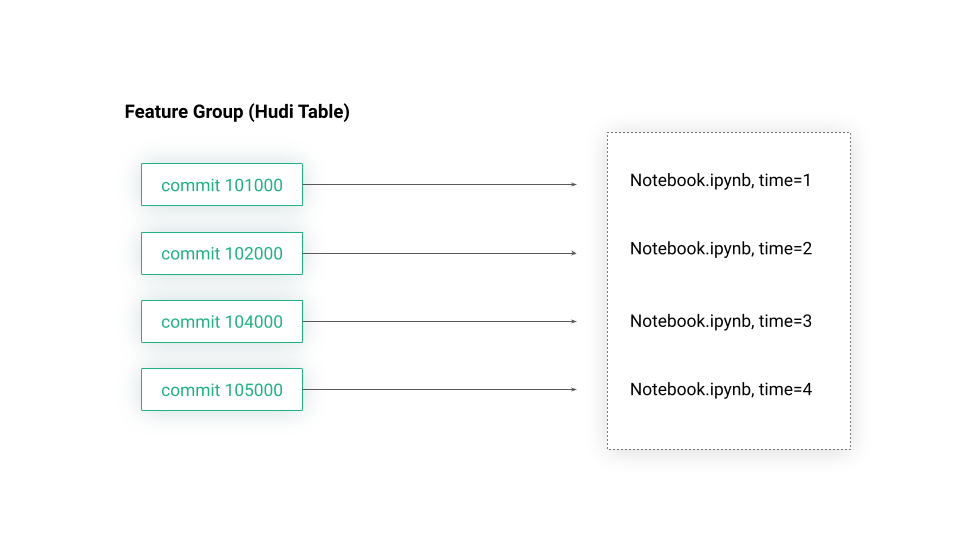
Figure 3. Notebook Snapshots and Time-Travel
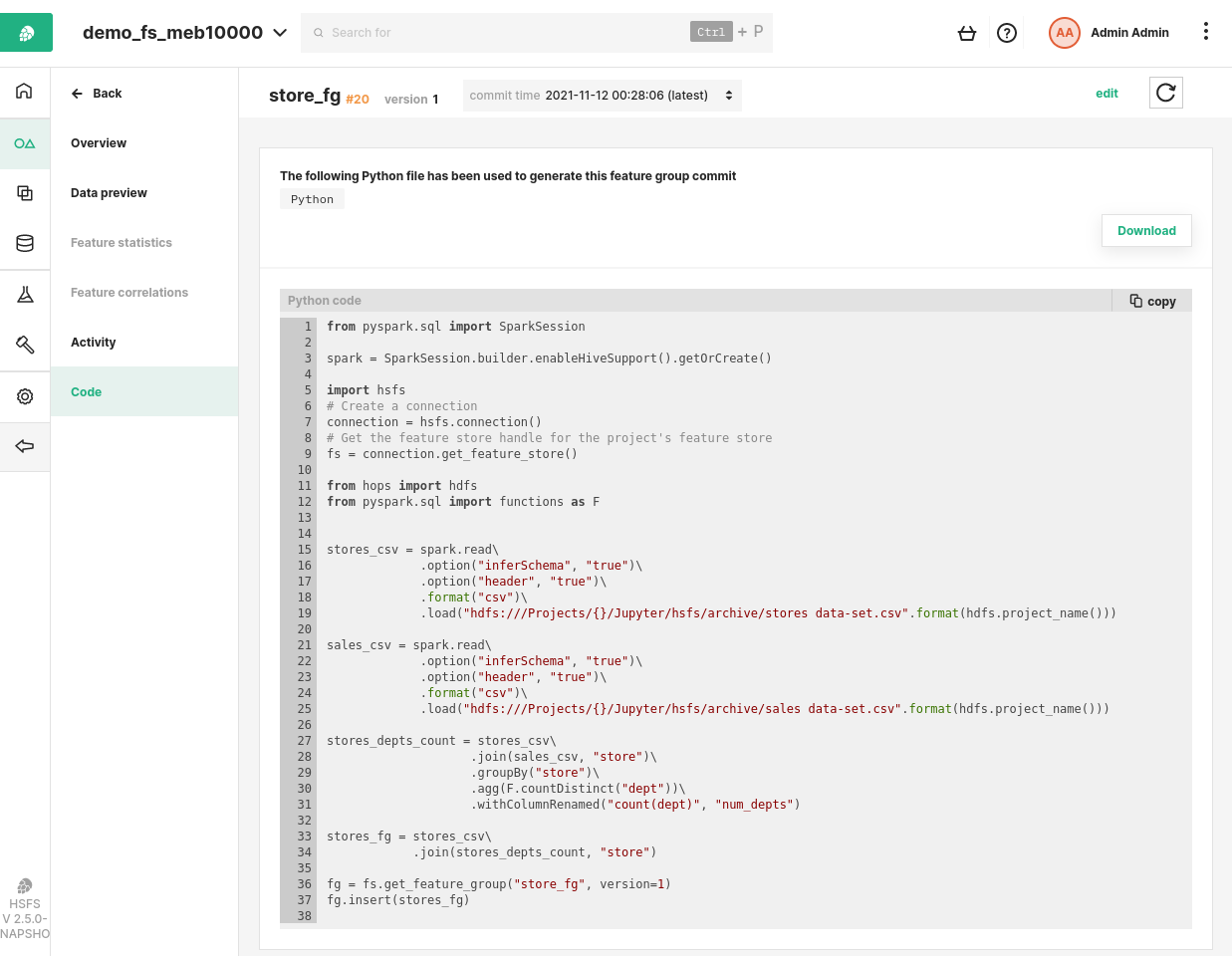
Figure 4. Code Preview Feature
Feature Code Snapshot Capabilities
The ability to easily view the code used to compute a given snapshot for a Feature Group enables new capabilities in Hopsworks:
- Debugging: if you discover a bug in your features, you can easily check the code used to create those features. For example, if you discovered a particular data ingestion run that polluted a feature group, it is now trivial to inspect the code that performed that ingestion.
- Reproducibility: you can reproduce the data used for a given update to a feature group by inspecting the program used to make that update along with the source data;
- Auditing and governance: you can travel back in time to see what code was used to create feature data in a given time period.
The new feature code preview functionality will be available in Hopsworks 2.5, due for release before the end of 2021.