Data Lakehouse
What is a Data Lakehouse?
In the field of data management, data lakes and data warehouses have long dominated the landscape. The data lake, vast and seemingly limitless, promises to hold all your data riches. But venturing in can be treacherous, with information scattered and analysis a challenging task. The data warehouse, on the other hand, offers a meticulously organized oasis, perfect for immediate analysis. However, its rigid structure can leave valuable, unexplored data sources behind.
A Data Lakehouse is a hybrid that combines the best of both data lakes and data warehouses. By merging the strengths of both sides, Data Lakehouse aims to deliver a more unified, efficient, and versatile platform for handling diverse data needs.
Before diving into the intricacies of the Data Lakehouse, it’s essential to understand the foundational elements it integrates: data lakes and data warehouses.
Data Lakes
The digital age has unleashed a torrent of data – structured, unstructured, and everything in between. Businesses generate data from customer interactions, social media streams, sensor readings, and a multitude of other sources. This data deluge holds immense potential for uncovering hidden patterns, driving innovation, and making data-driven decisions. Especially with the ever-evolved machine learning (ML) techniques, data storage and management become increasingly important.
Data Lakes are vast repositories designed to store raw, unstructured, and structured data at scale. They are highly flexible, allowing organizations to store data in its native format until it is needed for analysis. This approach offers cost efficiency and agility, making data lakes popular for big data analytics, ML, and real-time data processing. However, data stored in data lakes can be difficult to retrieve by querying and performing analysis.
Data Warehouses
Data Warehouses, on the other hand, are structured environments optimized for reporting and analysis, such as business intelligence. They store processed and refined data, where the raw data goes through the Extract-Transform-Load process (ETL process), ensuring high performance and reliability for complex queries. Data warehouses are traditionally used for tasks that highly require efficiency and data quality. However, they are more durable for small-scale and less frequently updated data. For big data, it can be expensive to maintain and not as flexible for storing different data types or data from different sources.
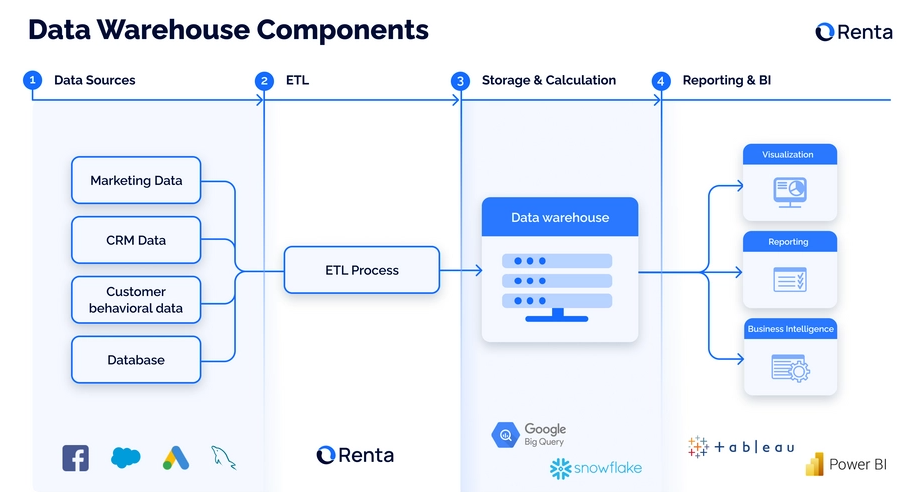
What are the Key Components of a Data Lakehouse?
The Data Lakehouse emerged as a response to the limitations and challenges posed by data lakes and data warehouses. Organizations often use both systems: data lake for storing raw data, and data warehouse for storing processed structured data. However, they usually find themselves duplicating data and efforts across these systems. Or their analysts often end up spending precious time wrangling data into a usable form before they can even begin to glean insights. These lead to increased complexity and cost. The Data Lakehouse aims to unify these environments, allowing the storage of large amounts of data in a cost-effective way, like a data lake, but also provides some of the structure and data management features of a data warehouse. This enables organizations to store all the data (structured or unstructured) in one place, while enabling SQL-like querying capabilities, making it easier to analyze later for various purposes like ML or BI.
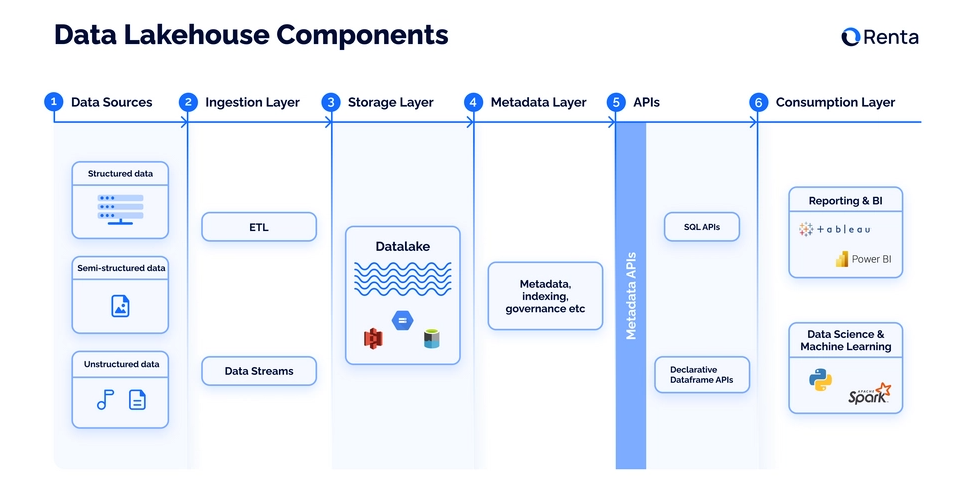
Key components of a Data Lakehouse
Storage Layer
At the core of the Data Lakehouse is a unified storage layer, similar to a data lake, that supports both structured (or ETL processed) and unstructured data. This layer allows seamless access to raw and processed data, enabling a wide range of analytics and ML requirements.
This layer leverages open-source file formats like Apache Parquet, ORC, and Avro for efficient data storage. These formats typically store data in a columnar fashion, where data for each column is grouped together rather than storing full rows. This columnar organization significantly improves query performance by allowing data analysts to retrieve specific columns without needing to scan the entire dataset.
Metadata Layer
Efficient metadata management is crucial for the Data Lakehouse.The metadata layer sits on top of the storage layer and acts as a catalog for your data. To manage and interpret the stored data, this critical layer relies on open-source table formats such as:
Apache Iceberg: Known for its focus on open standards and vendor neutrality. It's a good choice for portability and future-proofing your data storage. It features advanced partitioning strategies that do not require manual intervention to enhance query performance. Apache Iceberg is supported by Snowflake and AWS.
Delta Lake: Developed by Databricks and tightly integrated with their ecosystem. It offers strong performance optimizations and ease of use within the Databricks environment. It offers Atomicity, Consistency, Isolation, and Durability (ACID) transactions natively, providing strong guarantees for complex, multi-step data operations, and supports data optimization techniques like Z-ordering, which improves query performance by clustering related data together.
Apache Hudi: Designed with an emphasis on real-time data ingestion and updates. It's ideal for scenarios where you need to continuously ingest and process data streams. It provides a feature called Hudi Incremental Pull, which allows users to pull only the changed data since the last pull. Furthermore, it also includes built-in data clustering to optimize query performance by co-locating data that is frequently accessed together. Apache Hudi is supported by AWS, Hopsworks, and Onehouse.
These three formats offer richer functionalities besides the basic details provided by the underlying file formats (like Parquet or ORC), for example:
Data Location: All three formats track the physical location of the data files within the storage layer. This ensures efficient data retrieval when running queries or performing other operations.
Schema: Similar to traditional databases, table formats define the data structure, including data types for each column. However, they offer more flexibility for schema evolution, allowing modifications to the schema over time (such as adding new columns or changing data types) without completely rewriting your data. Iceberg and Delta Lake excel at schema evolution, while Hudi focuses on keeping the schema consistent for real-time data updates.
Partitioning: All three formats allow you to logically organize your data based on specific columns. For instance, you can partition your data by year and month for faster queries that focus on specific timeframes. This significantly improves query performance by allowing the system to quickly locate relevant data files without scanning the entire dataset.
Versioning History: This feature is crucial for maintaining data lineage and ensuring data quality. Iceberg, Delta Lake, and Hudi track changes made to the data over time, creating different versions of your data. This allows you to revert to previous versions if errors are discovered or if you need to analyze historical data.
Access Control Rules: Data governance is paramount, and all three formats provide mechanisms to define user permissions for data access. This ensures that only authorized users can access and modify specific datasets, complying with data security and privacy regulations.
APIs
The API layer facilitates seamless interaction between the Data Lakehouse and external applications, tools, and services. This layer provides standardized interfaces for data ingestion, extraction, and querying, enabling integration with business intelligence tools, data science and ML platforms, and other systems. This layer can also incorporate robust governance and security features, ensuring data compliance and protection. This includes role-based access controls, encryption, and audit logging. Furthermore, as some APIs require complex data operations, such as performing complex data transformations or running analytical queries, a versatile computation engine is also essential. The engine should be capable of scaling with the data volume and complexity.
What are the Benefits of a Data Lakehouse?
Simplified Architecture
By consolidating data storage and processing capabilities, the Data Lakehouse simplifies the overall architecture, reducing the need for data duplication and siloed systems. This leads to lower operational costs and streamlined data management.
Flexibility and Scalability
The Data Lakehouse can handle diverse data types and workloads, from batch processing to real-time analytics. Organizations can store all their data, regardless of format, and easily scale up or down dynamically as needed. Data Lakehouse often uses low-cost cloud storage which is cost-efficient and sustainable for small-scale needs.
Data Access and Analytics
With a unified data platform, users can access both raw and refined data from a single source. This improves the efficiency of data exploration and analysis. It also makes it easier for cross-team collaborations. Besides, Data Lakehouse supports advanced analytics and ML applications. The structure and data management features make it suitable for tasks that require complex data transformation and operations across diverse data types.
Summary
The Data Lakehouse represents a significant advancement in data management by bridging the gap between data lakes and data warehouses. This innovative architecture provides a unified platform that supports a wide variety of data types and workloads. By integrating these capabilities, the Data Lakehouse allows organizations to streamline their data architecture, enhance flexibility, and drive advanced analytics. This enables them to fully leverage the potential of their data assets. As data continues to play a crucial role in strategic decision-making and machine learning, the importance of the Data Lakehouse will only grow, making it a key driver in the future of data-driven innovation.