Dimensional Modeling and Feature Stores
What is dimensional modeling and how does it relate to feature stores?
Data modeling for feature stores involves organizing your entities and features into feature groups. In data warehousing, dimensional modeling is a data modeling technique that identifies entities and then decomposes your data into “facts” and “dimensions” related to those entities.
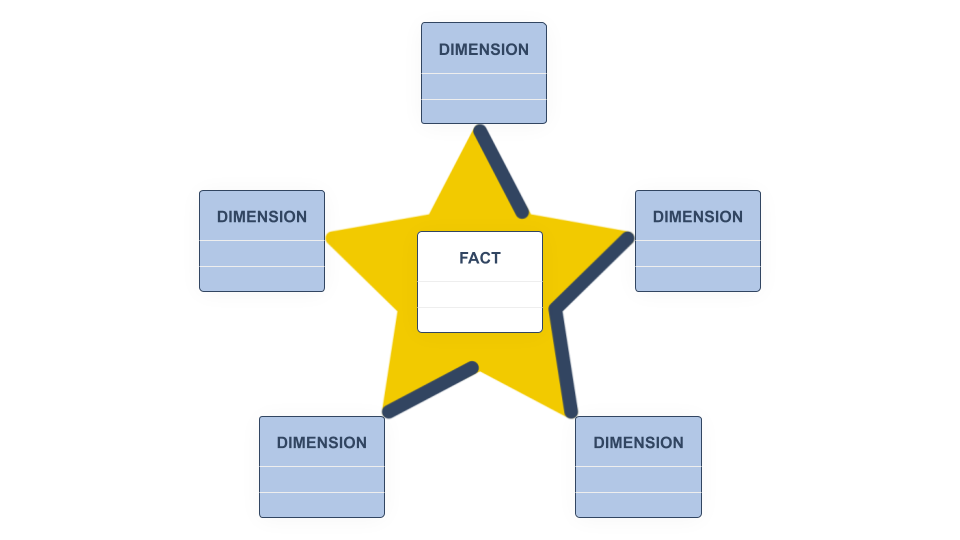
Facts and dimensions can be organized into a star or snowflake schema, as shown in the figure above.
But what about features and labels - what are the “facts” and “dimensions” in a feature store?
Firstly, if your feature store has lots of features and models using it, it is likely that a label in one model could also be a feature in a different model.
The basic principle behind a feature store is that you can select the features and labels, join them together and you get a feature view for a model. The feature view is the schema (input features and output label(s)) for training and inference with models.
In a feature view, a label is a “fact” and a feature is a “dimension”.
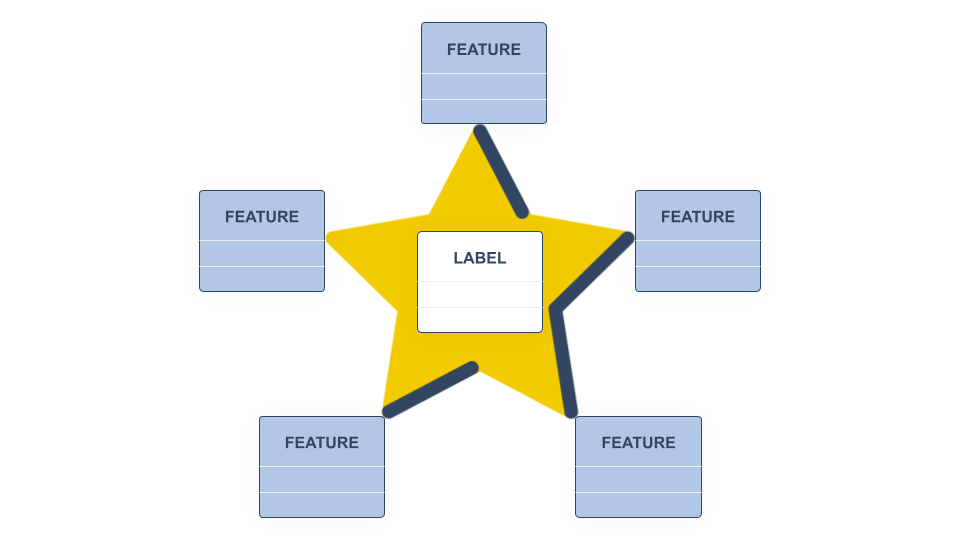
A feature view organizes features and labels into a star schema, as shown in the figure above. Here, the features and label(s) come from one or more different feature groups. When you create training data with a feature view, the feature store executes a point-in-time-correct Join to materialize the training data before it is returned as either a DataFrame or files to a (Python) client.
One data modeling design question that is still hotly debated in the data warehousing community is whether you should keep your labels and features in separate feature groups or create wide, joined feature groups? Wide, joined feature groups may remove the need for point-in-time-correct Joins across feature groups (as training data can be read directly from a single feature group), but at the cost of denormalized (redundant) feature data.