Point-in-Time Correct Joins
What is a Point-in-Time (PiT) Correct Join?
In SQL, a PiT Join is an ASOF LEFT JOIN. That is, a point-in-time correct join is a temporal join between two tables where the output reflects the state of the both tables at a specific point in time defined by timestamps from the left table (containing the labels). ASOF LEFT JOINS start with a table containing both the labels/observations (for training) and a timestamp column (the timestamp for each observation), and the ASOF LEFT JOIN joins feature values from another table (containing feature data) with every row in the output table containing the feature AS OF the value of the point in time of timestamp value from the label table.
When is a Point-in-Time (PiT) Correct Join needed when creating training data?
When constructing a snapshot of data (e.g., training data or batch inference data) from precomputed features spread across different feature groups, we often need to construct a snapshot of feature values at a specific point in time. For example, a training dataset for supervised ML is a snapshot of feature values at the time of the observation of each label in each row in the training dataset.
A problem with creating a point-in-time-correct training data snapshot is that the underlying tables (feature groups) are typically updated at different cadences by different data pipelines. As such, it is not always possible to utilize an exact time-based join to obtain the desired result. The solution is a Point-in-Time correct Join that starts with the timestamps for the labels and retrieves the most recent feature values for the features from all the tables joined with the table containing the labels.
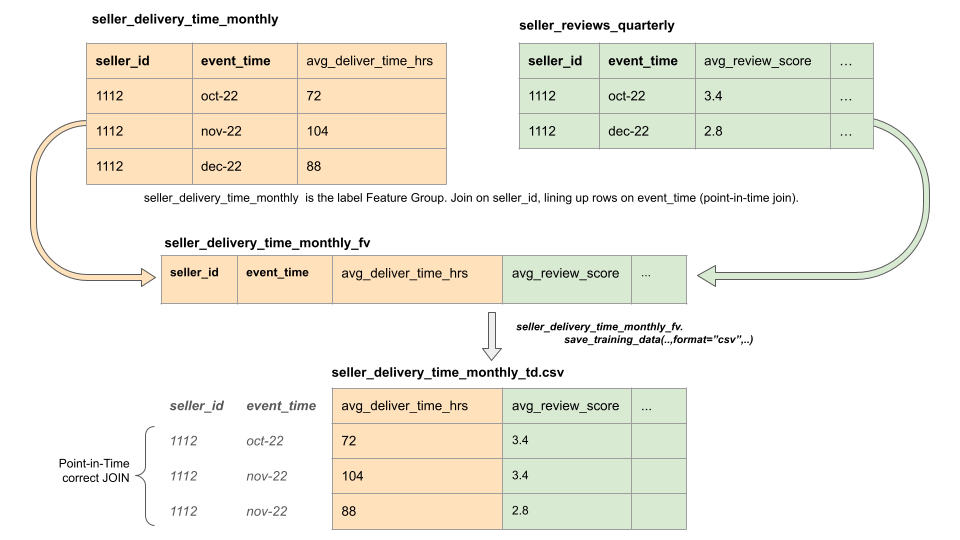
What are the advantages of using a PIT-Correct Join?
- Avoiding label leakage: Ensuring that the features used for training are only derived from data available at the point in time corresponding to the label prevents label leakage. Label leakage occurs when information from the future is unintentionally used for training, leading to over-optimistic model performance that does not generalize well to real-world scenarios.
- Reproducibility: PIT-Correct Join makes it possible to recreate historical snapshots of data consistently, which is essential for model reproducibility, debugging, and auditing purposes.