LLM Temperature
What is LLM Temperature?
In recent years, Large Language Models (LLMs) have stood out as revolutionary tools that are capable of crafting human-quality texts, including producing coherent and contextually relevant text, translating languages elegantly, and dreaming up creative content on demand. Beneath the surface, there lies a fascinating factor that affects the nature and quality of the generated output, which is known as LLM temperature.
At its core, LLM temperature controls the balance between playing more safely and exploring new possibilities - exploration versus exploitation in the model's output. Lower temperatures favor exploiting the patterns LLMs have already learned and mastered, making the outputs more predictable and reliable. This is ideal when accurate and factual information is needed. Conversely, higher temperatures encourage exploration, meaning that the LLMs get adventurous. It ventures beyond the familiar patterns and increases the chance of being surprising and creative, potentially yielding more diverse, albeit riskier, outputs. This can be useful for brainstorming ideas.
Example of adjusting LLM Temperature in ChatGPT playground
How does LLM Temperature work?
LLMs are usually trained on large amounts of text data. They learn the patterns of how likely words appear together or apart, building a complex network of possibilities. When LLMs generate output, there are usually a few candidates in the vocabulary for each word and each candidate word has a certain likelihood of being chosen. Those likelihoods are represented by a set of logits. Then the softmax function takes the set of logits and transforms them into probabilities that sum to 1. A temperature value in the softmax function scales these logits, influencing the final possibilities calculated for each candidate word and affecting the selection of the next word in the output.
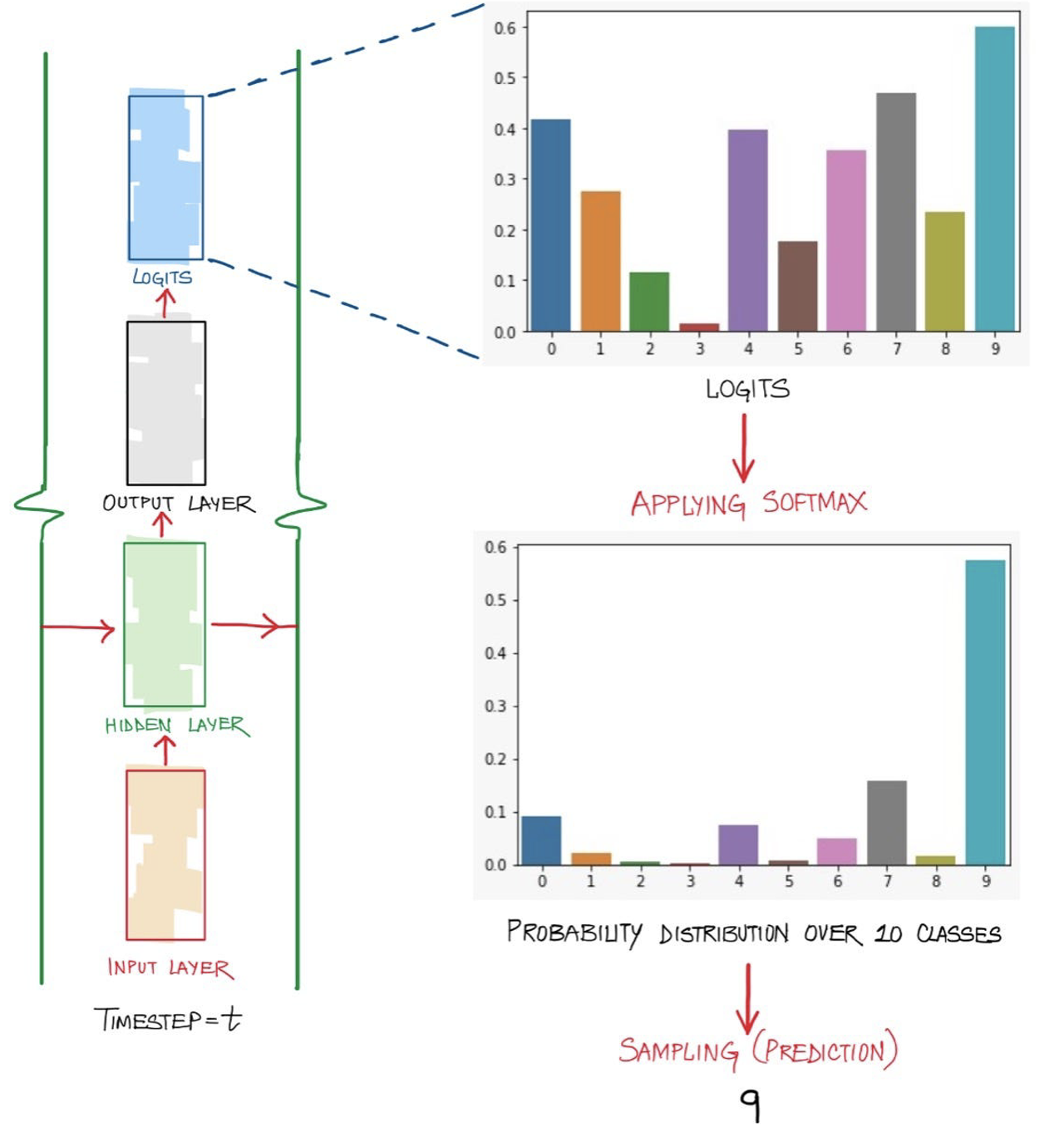
How a word is output by an LLM
The Softmax Function with LLM Temperature
Mathematically, the softmax function for a given candidate word i with logits _yi_ is defined as:
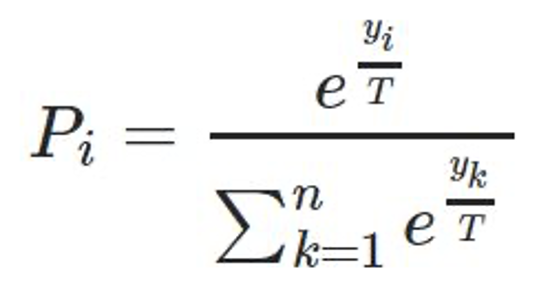
Where:
e is Euler's number (approximately 2.71828).
T is the LLM temperature parameter.
n is the size of the vocabulary.
From the above softmax function, we can see that the LLM temperature acts as a control mechanism. It affects the probabilities assigned to each candidate word by scaling the logits.
The Impact of LLM Temperature
Lower Temperature (𝑇<1): When 𝑇 is small, the softmax function magnifies differences between logits, leading to sharper probability distributions. This means that the model becomes more confident in selecting words with higher logits, making the LLM prioritize the most probable next word and effectively reducing randomness in the generated text. As a result, lower temperatures promote the exploitation of high-confidence predictions, often yielding more deterministic and conservative outputs.
Higher Temperature (𝑇>1): On the other hand, increasing 𝑇 softens the differences between logits, resulting in flatter probability distributions. Less probable words become more likely contenders. This encourages the model to explore a wider range of word choices, even those with lower logits. Consequently, higher temperatures foster diversity in the generated text, allowing the model to produce more varied and creative outputs.
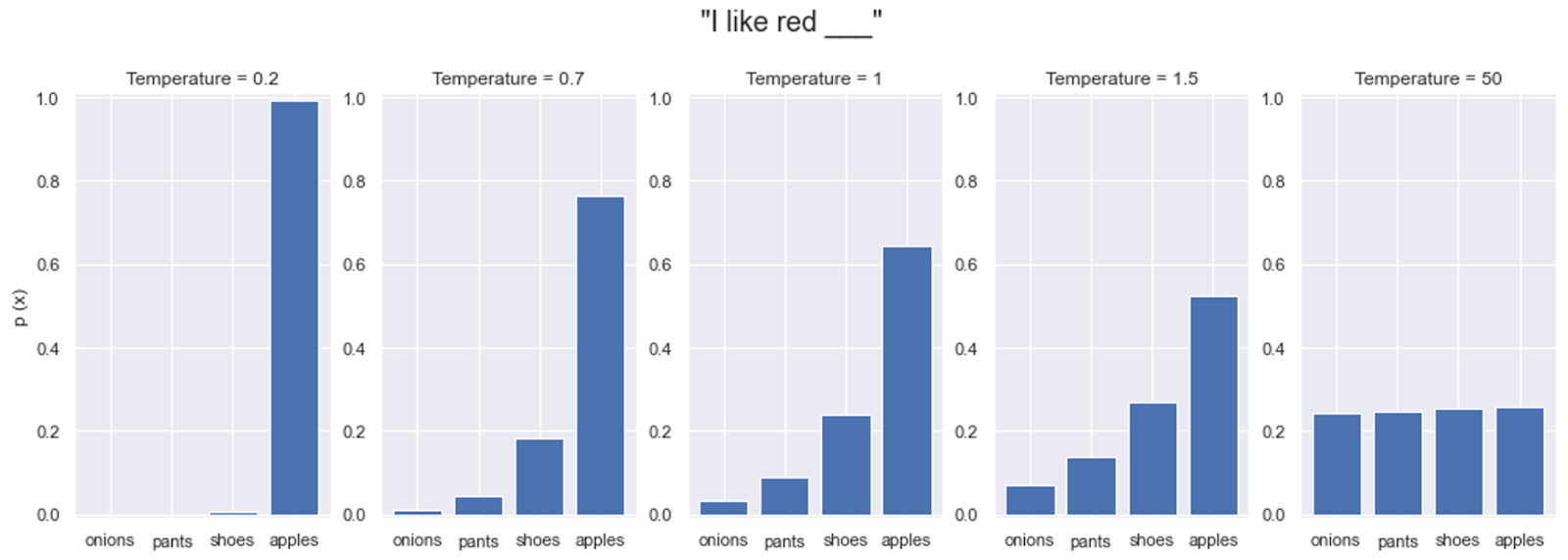
Illustration on different temperatures resulting in different possibility distributions
Sampling Strategies
In practice, LLMs may employ different sampling strategies to incorporate LLM temperature during text generation. For example, at 𝑇=0, greedy sampling is usually employed. The model selects the word with the highest probability, effectively choosing the most confident prediction at each step.
How to choose the perfect LLM Temperature?
There's no magic number for LLM temperature. The ideal setting is based on the specific goal. Choosing the most suitable LLM temperature involves balancing various factors such as coherence, diversity, and specific task requirements. While there's no one-number-fits-all solution, here are some strategies:
Task Requirements
Coherence: If your task requires generating text that closely follows the input context or maintains a formal tone, such as summarizing research papers or writing technical reports, lower temperatures (𝑇<1 or maybe around 0.5) may be preferable to ensure high coherence and accuracy.
Creativity and Diversity: For tasks where creativity and diversity are valued, such as creative writing or brainstorming, higher temperatures (𝑇>1) can encourage the generation of more varied and innovative outputs.
Experiments
Experiment with different temperature values and evaluate the quality of the generated outputs. The evaluation can be done via human or user feedback. Monitor and observe how varying temperature selections impact the qualitative feedback on the performance of the LLMs. It is also worth noting that the optimal LLM temperature may not stay the same as the context or tasks evolve. Periodic reassessment and iteration are often beneficial.
Task-Specific Tuning
In some cases, fine-tuning the LLM temperature parameter for specific tasks or datasets may be necessary to achieve optimal performance. Train the LLM on domain-specific data and adjust the temperature based on the specific requirements of the task.
Finding the ideal temperature for an LLM is a delicate balancing act. Push it too high, and you risk nonsensical outputs; too low, and it becomes repetitive. It takes practice and experimentation to find the sweet spot. Furthermore, the LLM temperature value isn't the only factor affecting output. The prompt or question you provide to the LLM also plays a crucial role. A strong prompt with clear instructions might work well with a higher temperature, while a more open-ended one could benefit from a lower temperature for better exploration.
Understanding the Impact of LLM Temperature on Output Variability
The temperature parameter in Large Language Models (LLMs) directly affects the variability and randomness of generated responses. A lower LLM temperature value (close to 0) produces more deterministic and focused outputs, ideal for tasks requiring factual accuracy, such as summarization or translation. Conversely, a higher temperature value (e.g., 1.0 or above) introduces more diversity and creativity, as the model samples from a broader range of possible answers. This makes higher temperatures suitable for creative writing or brainstorming applications, where variety is preferred. Adjusting the LLM temperature allows practitioners to customize the behavior of the model based on specific output needs, making it a key tuning parameter for optimizing user experience.
Best Practices for Setting LLM Temperature in Production
Choosing the right temperature for LLMs is essential in production environments, where consistency, accuracy, and relevance are crucial. For applications needing highly reliable and reproducible outputs, such as customer service automation, setting a lower LLM temperature (e.g., 0.2-0.3) helps maintain quality and reduces unexpected responses. In contrast, interactive applications like chatbots, content creation, or gaming can benefit from a mid-range temperature (e.g., 0.7-0.9), allowing the model to be engaging without straying too far from meaningful responses. Testing and fine-tuning the temperature parameter based on the application's specific requirements can help teams strike the right balance between creativity and accuracy, ensuring the model's output aligns with the end-user's expectations.
Summary
In our exploration of the LLM temperature, we uncover its crucial impact on the performance of LLMs. The LLM temperature serves as a critical parameter influencing the balance between predictability and creativity in generated text. Lower temperatures prioritize exploiting learned patterns, yielding more deterministic outputs, while higher temperatures encourage exploration, fostering diversity and innovation. Understanding and fine-tuning LLM temperature enables practitioners to tailor text generation to specific requirements, striking the optimal balance between coherence and novelty.