Online-Offline Feature Skew
What is online-offline feature skew?
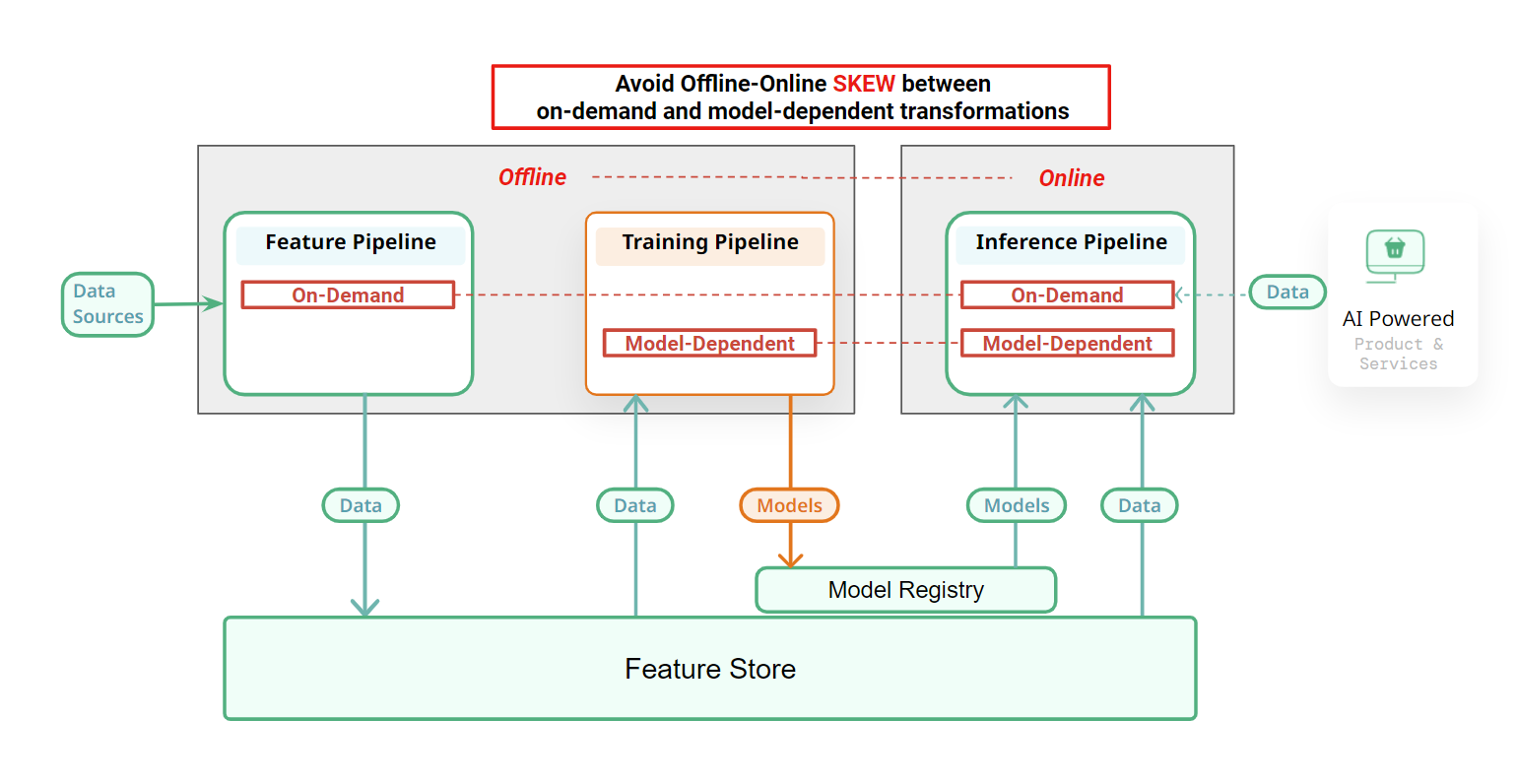
Skew occurs when there is a difference in the implementation of a transformation in an online inference pipeline and the corresponding transformation in either the training pipeline (model-dependent transformation) or the feature pipeline (on-demand transformation).
Feature skew is when there are significant differences between the feature logic executed in an offline ML pipeline (the feature or training pipeline) and the feature logic executed in the corresponding online inference pipeline.
The necessary conditions for feature skew are:
- the feature logic (either model-dependent or model-independent transformations) is non DRY between an offline (feature or training) pipeline and the corresponding online inference pipeline;
- there are unintended differences between the two implementations of the feature logic leading to significantly different feature values being computed for the same input data.
On-demand feature transformations are applied in both the feature and online-inference pipelines and different implementations can result in on-demand feature skews. Training-inference skew can occur when model-dependent transformations are implemented differently in the training and online inference pipelines. Feature skew can silently and negatively affect model performance making such issues difficult to detect.
Why is it important to prevent feature skew?
Feature skew can result in silently degraded model performance that is difficult to discover. It will show up during online inference, as the model may not generalize well to the new data during inference due to the discrepancies in feature transformations.
Example of training-inference skew
Consider a feature transformation where the raw data is scaled using the mean and standard deviation calculated from the training dataset. Suppose the following code snippets are used for the transformations during the training pipeline and online inference pipeline:
Feature Pipeline:
Online inference pipeline:
In this example, the feature transformation at the inference stage incorrectly calculates the mean and standard deviation from the new data instead of using the values from the training dataset. This discrepancy leads to training/inference skew and can negatively impact the model's performance during inference.