Grouped Query Attention
What is Grouped Query Attention?
Large language models (LLMs) are revolutionizing various domains. However, their power comes at a cost – they can be computationally expensive, especially during the inference stage, where the model applies its learned knowledge to new tasks. This is where techniques like grouped query attention (GQA, first introduced in the paper “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints”) come in.
How does Grouped Query Attention work?
Before diving into grouped query attention, let's first revisit the fundamental concept of attention mechanisms in LLMs. At its core, attention allows models to selectively focus on different parts of the input sequence, enabling them to weigh the importance of each element when making predictions or generating outputs. In a typical attention mechanism, each query (e.g., a word or token representation) computes its attention scores concerning all keys (usually encoder representations), resulting in a weighted sum that captures the relevance of each key to the current query. While powerful, traditional attention mechanisms, like multi-head attention (MHA), can be computationally demanding. MHA uses multiple "heads" to attend to different aspects of the input, leading to increased memory usage and processing time.
Multi-Head Attention
MHA enables parallel processing, each process focusing on a different aspect of the input sequence by utilizing several "heads," each with its own set of projections for the query, key, and value elements. Each head can calculate attention scores simultaneously, leading to a richer and more comprehensive understanding of the input.
While powerful, MHA can be computationally expensive. The multiple calculations involved in each head and the need to store separate key-value pairs for each head can lead to slower inference times and higher memory usage.
Multi-Query Attention
Multi-query attention (MQA) offers a more streamlined way to handle attention. Here, a shared key and value pair are used for all the queries. Unlike MHA, MQA only works with the same key and value information. This reduces the number of calculations needed and potentially improves efficiency.
While MQA is faster, it might not capture as much detail from different aspects as MHA. The shared information source can limit performance.
Grouped Query Attention
GQA emerges as an innovative extension of traditional attention mechanisms, aiming to address several challenges associated with processing long sequences efficiently. It acts as a bridge between MHA and MQA.
The key idea behind GQA is to partition queries into distinct groups or clusters and compute attention within each group independently. To be more specific, GQA takes the multiple query heads used in MHA and groups them. Each group then shares a single set of key and value heads. This reduces the number of distinct key-value pairs the model needs to process, leading to significant efficiency gains while still capturing meaningful relationships within the data.
The number of groups created plays a crucial role. A higher number of groups leads to faster inference times but can potentially impact the quality of the model's output. Conversely, fewer groups provide better performance but sacrifice speed. Finding the optimal balance between group numbers and performance requires fine-tuning the model.
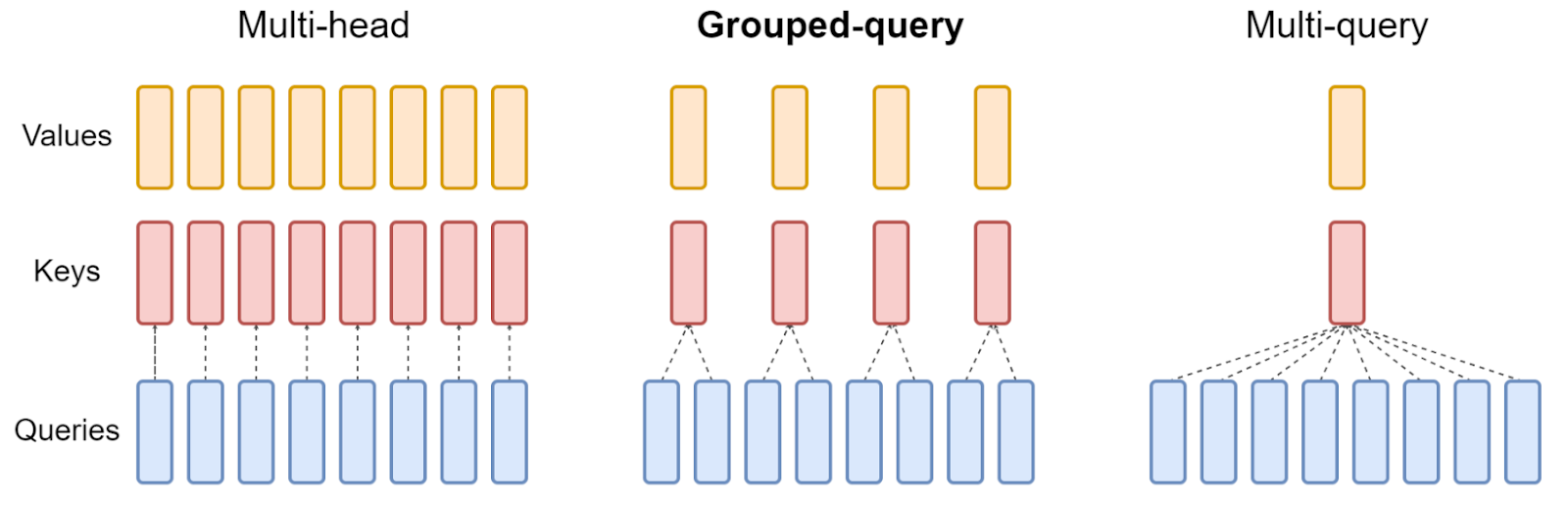
Overview and comparison of the Multi-head attention, Grouped-query attention, and Multi-query attention.
What are the Key Techniques when implementing Grouped Query Attention?
Several techniques underpin the implementation and effectiveness of grouped query attention:
-
Query Grouping Strategies: The process of grouping queries is crucial in grouped query attention. Various strategies can be employed, including grouping based on semantic similarity, syntactic structure, or positional information within the input sequence. Each grouping strategy introduces unique trade-offs in terms of computational efficiency and the model's ability to capture relevant dependencies.
-
Group-Level Attention Computation: Once queries are grouped, attention scores are computed within each group independently. This step typically involves calculating the compatibility between each query and the keys within its group, followed by applying a softmax function to obtain normalized attention weights. Group-level attention computation allows the model to focus on local patterns and dependencies within the input sequence, facilitating more effective information processing.
-
Integration with Neural Architectures: Grouped query attention can be seamlessly integrated into various neural network architectures, including transformers, recurrent neural networks (RNNs), and convolutional neural networks (CNNs). By replacing or augmenting traditional attention mechanisms with grouped query attention modules, these architectures can leverage the benefits of localized attention while preserving their overall structure and functionality. Note that the authors of the paper mentioned that GQA is not applied to the encoder self-attention layers as the encoder representations are computed in parallel already.
-
Parameter Sharing and Efficiency: To optimize memory usage and computational efficiency, grouped query attention often incorporates parameter sharing techniques. By sharing parameters across groups or utilizing sparse attention mechanisms, the model can effectively scale to longer input sequences without incurring a significant increase in computational overhead.
What are the Benefits of Grouped Query Attention?
In the GQA paper, the experiments show that GQA gains a favorable tradeoff compared to the MHA models by achieving higher quality than the similar speed MHA and faster inference than the extra-large MHA model with high performance.