Embedding
What is an embedding in ML?
An embedding is a compressed representation of data such as text or images as continuous vectors in a lower-dimensional space. Embeddings should capture the semantic relationships and similarities between the original uncompressed objects while reducing the dimensionality of the data.
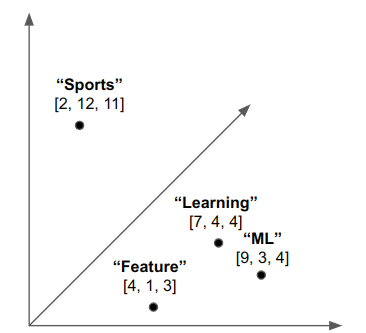
The above figure shows a Word Embedding with Dimensionality of Length 3. That is, each word is encoded as a vector of length 3 using a Word Embedding model. Notice that “ML” and “Learning” are close in embedding space, but “Sports” is far away. “Feature” is close to “Learning” and “ML”. In this example, if you searched for the closest word to “ML”, you would find the word “Learning”.
What type of data can be compressed into an embedding?
The most common embedding models are for text data, image data, audio data, and many types of structured data (such as DNA data, your purchase history at an ecommerce store, and any historical sequence of events that have identifiable patterns).
Similarity search for embeddings in Vector Databases
A vector database can be used to store embeddings and provide support for searching for similar embeddings.
How are embeddings created?
Embeddings are created by training a deep learning model to generate continuous vector representations of complex objects, such as words or images. For example, Word2Vec is an unsupervised learning method that uses a shallow neural network to learn word embeddings.
How are embeddings related to latent space?
Embeddings are similar to latent space in that they both are a compressed representation of higher dimensional data that maintains the relationships in the original data. Embeddings are essentially points or coordinates in the latent space.