KServe
What is KServe?
KServe is an open-source model serving platform that operates on Kubernetes. KServe excels in scalability, enabling the deployment of a wide variety of ML models as network-accessible services on a Kubernetes clusters including Tensorflow, XGBoost, Scikit-Learn, PyTorch, ONNX, and large language models (LLMs).
To provide high performance support for the different ML frameworks, KServe supports many different model serving engines, including Nvidia Triton, vLLM, Seldon, Torch Serve, and TensorFlow Model Serving.
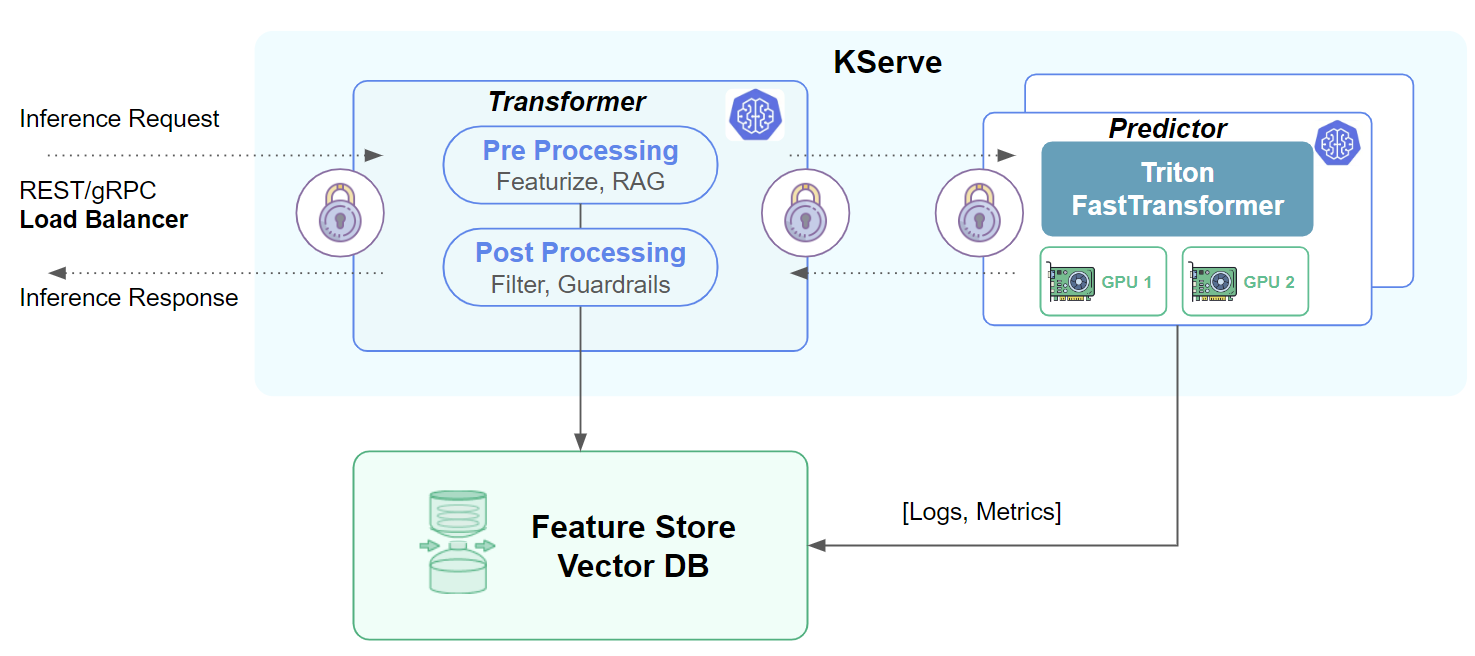
Figure 1: KServe makes ML models available as network accessible services via a REST or gRPC API. ML models typically require external data sources, such as a feature store or Vector DB, for enriched feature vectors or retrieval augmented generation (RAG).
What are the key Features of KServe?
Standard Model Inference Platform
KServe is a cloud-agnostic platform designed for scalable deployment and efficient scaling of ML models, accommodating high-demand prediction scenarios seamlessly across various cloud platforms.
Performant, Standardized Inference Protocol
KServe ensures that the process of making predictions or inference is both fast and follows a set of standard rules across various ML frameworks. This standardization inference protocol makes it easier to work with different types of models without having to change the way you interact with them.
Support for Modern Serverless Workloads
KServe is equipped to handle the modern trend of serverless computing, where the platform automatically adjusts the number of servers based on the incoming requests. It can scale down to zero servers when there is no demand, optimizing resource usage. This feature is applicable to both regular processors (CPU) and specialized graphics processors (GPU).
Scalability, Density Packing, and Intelligent Routing
KServe is designed to handle a large number of requests efficiently. It can pack a lot of models into a given space (density packing) and intelligently route requests to the appropriate models. This ensures that the system can handle a high number of requests without compromising on performance.
ModelMesh for Scalability and Routing
KServe leverages ModelMesh, a component that helps with high scalability and intelligent routing. ModelMesh plays a role in efficiently managing and directing the flow of data through the system.
Simple and Pluggable Production Serving
KServe aims to make it straightforward to deploy machine learning models in production. It provides a flexible and customizable system for serving models, including handling the steps before and after making predictions (pre/post processing), monitoring the performance, and explaining the model's decisions.
Advanced Deployment Strategies
KServe supports advanced deployment strategies like canary rollout (gradual deployment to ensure smooth transitions), pipelines (automated workflows), and ensembles (combining multiple models for improved accuracy) through something called InferenceGraph. This allows for more sophisticated and controlled deployment scenarios in real-world applications.
What are the key Components in the KServe Architecture?
KServe Control Plane
The KServe Control Plane is essential for handling the deployment and scaling of ML models. It does this by reconciling custom resources related to ML inferences. This control plane dynamically generates serverless deployments using Knative for predictors, transformers, and explainers. This allows the system to automatically scale up based on incoming requests and, notably, scale down to zero when there's no traffic.
The main player in this process is the KServe Controller, which oversees the life cycle of an inference service. This includes creating resources and containers for model servers, agent containers for logging and batching, and using the Ingress Gateway to route requests efficiently.
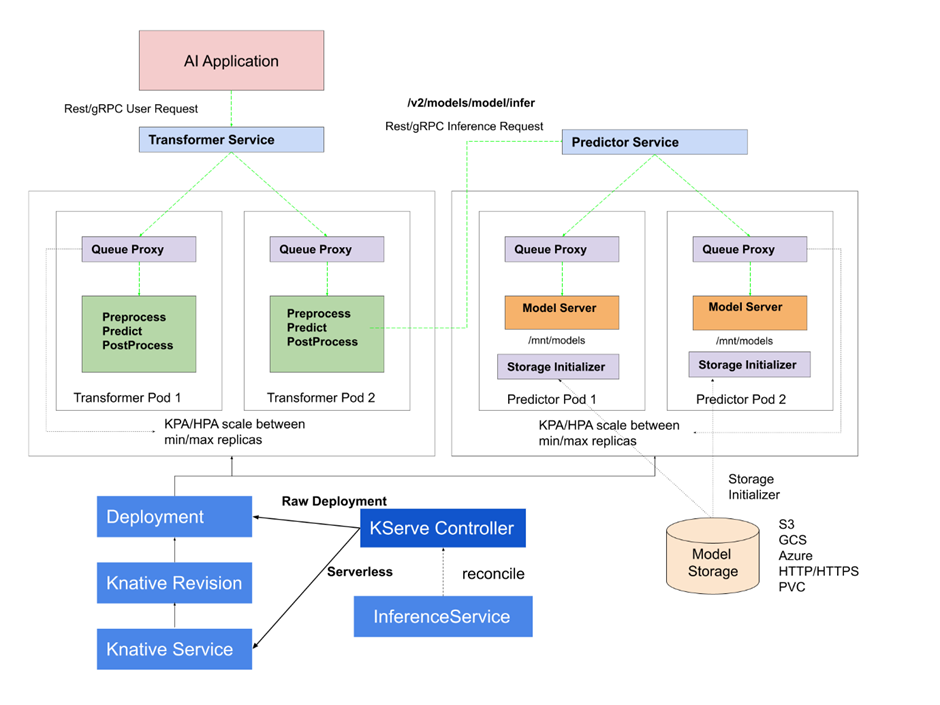
Figure 2: KServe Internals
Model Mesh Serving
To enhance the scalability of platforms, ModelMesh Serving is designed for real-time serving of ML/DL models, catering to high-scale, high-density, and dynamic use cases. It smartly handles the loading and unloading of ML/DL models in memory, striking a balance between responsiveness and computational footprint to maximize resource utilization. An alpha feature for multi-model serving has been introduced in ModelMesh Serving, recently integrated into KServe to boost scalability, though the interface may undergo changes. The platform supports various standard ML/DL model formats, including TensorFlow, PyTorch ScriptModule, ONNX, scikit-learn, XGBoost, LightGBM, and OpenVINO IR. It also allows extension with custom runtimes for arbitrary model formats.
The architecture involves a controller Pod orchestrating model runtime Deployments and a Service that accepts inferencing requests, with a routing layer ensuring optimal model loading. Incoming requests are directed to ModelMesh Serving, and model data is pulled from external storage instances, currently supporting S3-based object storage with plans for more storage options.
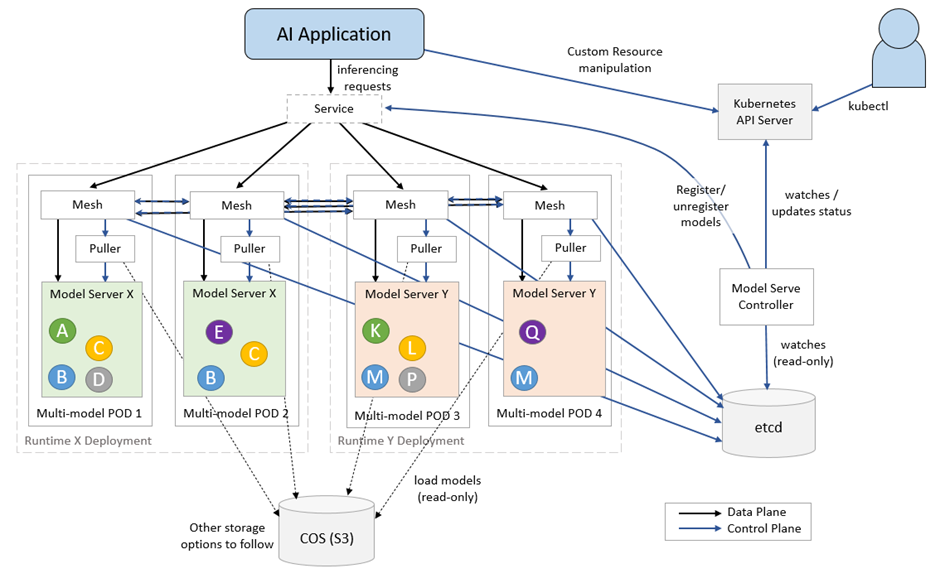
Figure 3: KServe Internals
Inference Graph
The Inference Graph within KServe tackles the intricacies of contemporary ML inference systems, where multiple models work together to make predictions. It facilitates the creation of complex pipelines by defining a graph structure comprising nodes, each with steps that guide to InferenceServices or other nodes.
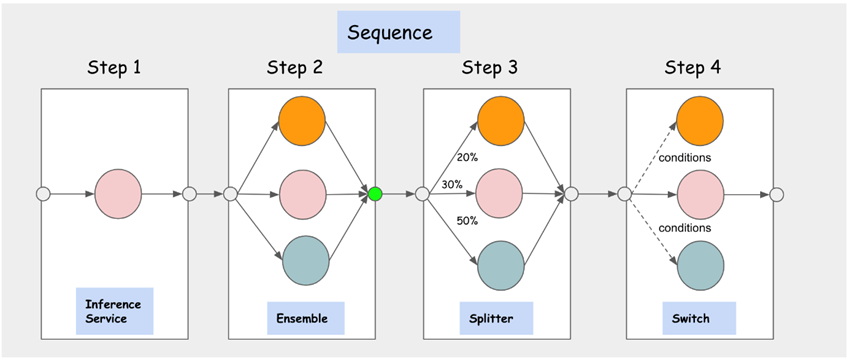
Figure 4: KServe Internals
The Sequence Node processes steps sequentially, passing outputs as inputs to subsequent steps. The Switch Node allows for conditional routing, returning the response from the first matching condition or the original request if none match. Ensemble Nodes support the combination of results from diverse models, while Splitter Nodes distribute traffic to multiple targets based on a weighted distribution. In summary, Inference Graph streamlines complex ML inference systems in KServe, allowing sequential execution, conditional routing, ensemble-based results, and traffic distribution.
Summary
KServe is a versatile open-source tool built on- top of Kubernetes, designed to support the deployment, scaling, and real-time serving of ML models. With components like the Control Plane, ModelMesh Serving, and Inference Graph, KServe excels in managing high-demand prediction scenarios and integrates seamlessly with popular ML frameworks.
KServe provides a comprehensive solution for ML serving in a production environment. It covers everything from making predictions to preprocessing and post-processing data, as well as providing explanations for the model's decisions. KServe is being used by various organizations, indicating that it has gained popularity and trust in the industry for deploying and managing ML models effectively.