Machine Learning Logs
What are Machine Learning Logs?
Machine learning (ML) has become a significant tool used by various industries, such as self-driving cars and personalized chatbot. ML models are continuously evolving and driving innovation at an unprecedented pace. As more and more ML models are being deployed into complex systems, the tracking, monitoring, and analyzing the ML pipeline becomes necessary.
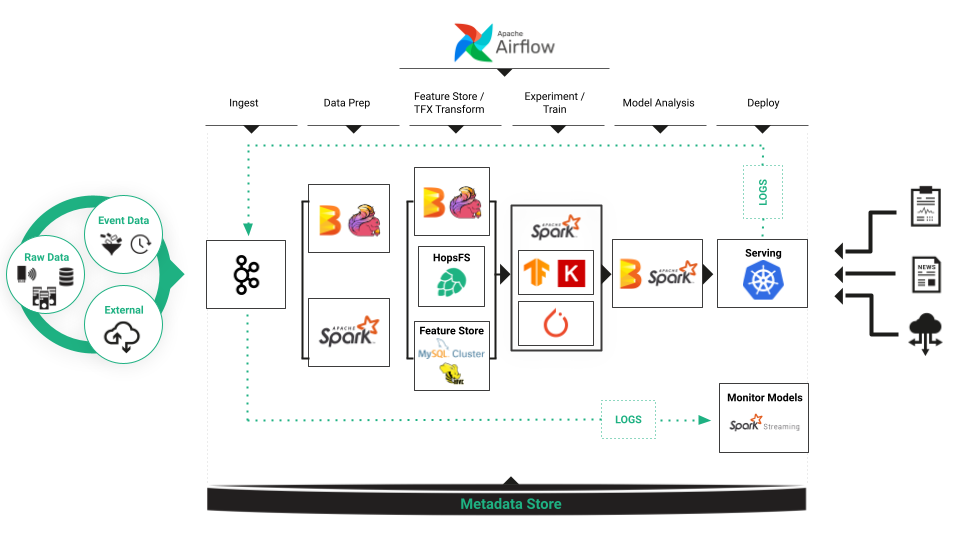
Machine learning logs, or ML logs, serve as valuable records that document the entire process. ML logs are structured records that capture essential information about the training, testing, and deployment phases of ML models. These logs serve as a comprehensive repository of data, providing insights into the performance, behavior, and effectiveness of ML systems.
What are the types of Machine Learning Logs?
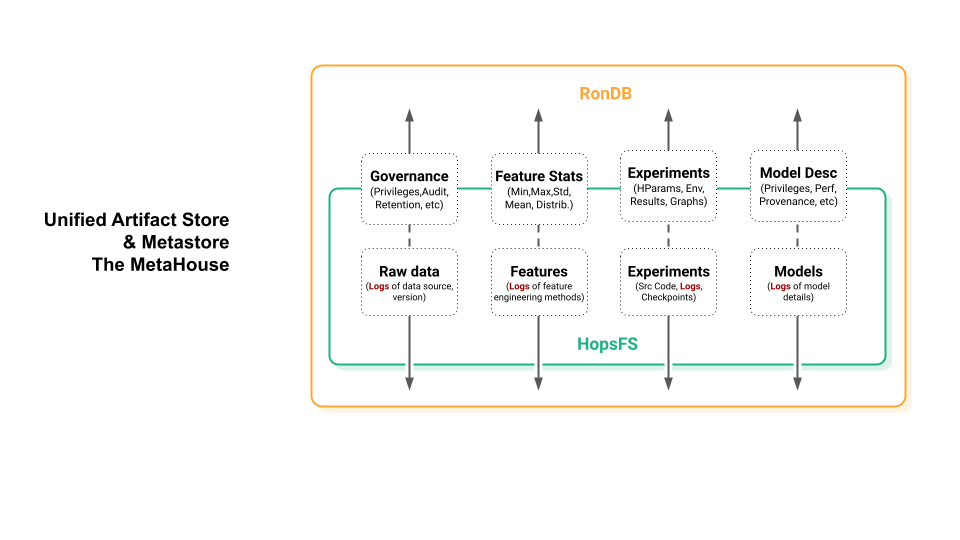
Training Logs
During the training phase, the details of ML models and their performance are often thoroughly monitored. The ML model information usually consists of:
- Training data, the information of the data used for ML model training, such as the data source, number of samples, feature information, data processing procedure, etc.
- Model architecture, the details of the structure of the model, including the type of the ML model, such as the type of the neural network used (e.g., convolutional neural network, recurrent neural network), the number of layers, the activation functions used, etc.
- Training parameters, hyperparameters of the model, including learning rate, batch size, and optimizer configuration.
- Training metrics, the performance metrics recorded during training and validation, such as losses, accuracy, validation scores, and learning curves. They provide insights into the convergence behavior of the model, helping developers fine-tune hyperparameters and optimize performance.
Experimentation Logs
Machine learning practitioners often conduct numerous experiments, exploring different algorithms, feature engineering techniques, model architectures, and hyperparameters. Experimentation logs capture training details (the above training logs) about each experiment. These logs facilitate reproducibility and aid in the decision-making process when selecting the best-performing model for deployment.
Once training experiments and model selection are complete, the model's performance is evaluated on a separate test dataset. Logs record evaluation metrics like precision, recall, F1-score, and AUC-ROC curve, providing a comprehensive picture of the model's generalizability.
Debugging Logs
Debugging is an integral part of the ML development and deployment lifecycle. Debugging logs capture any errors or warnings encountered during the training and inference stages, containing information about the input data, intermediate computations, and output predictions generated. They help identify and troubleshoot potential issues such as data preprocessing errors, model bugs, and unexpected behavior, ensuring the robustness and reliability of the ML system.
Deployment Logs
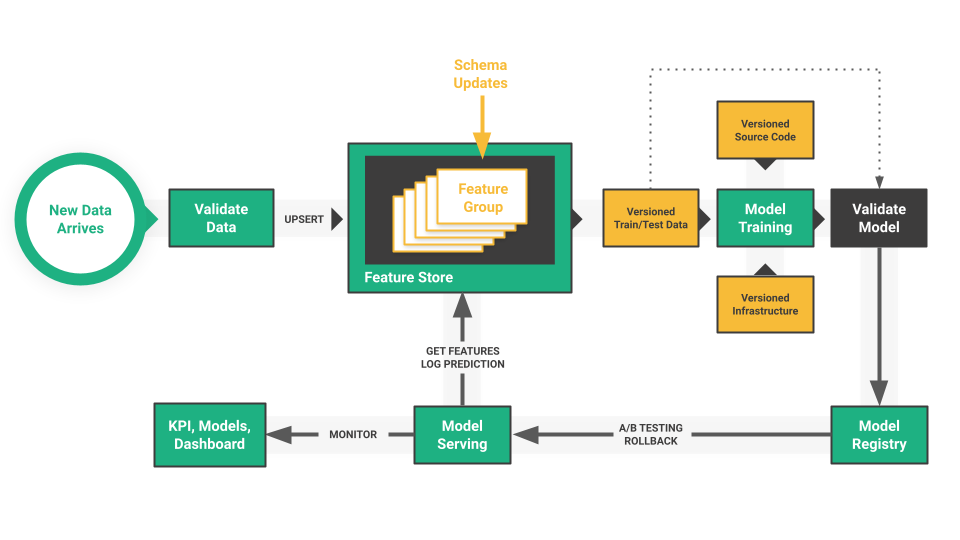
Once a model is deployed into production, monitoring its performance becomes crucial. Deployment logs track various metrics such as inference requests, response times, error rates, and resource utilization. These logs enable ML practitioners to detect anomalies, optimize performance, and ensure the seamless operation of the ML system in production environments.
How do we use Machine Learning Logs effectively?
Performance Monitoring
Machine learning logs provide real-time insights into the performance of models, enabling ML practitioners to monitor key metrics and detect performance degradation or anomalies promptly.
Standardize Logging Practices
Select a well-established logging framework specifically designed for ML projects. Popular options include TensorFlow Summary, MLflow Tracking, and Comet. These frameworks offer structured logging capabilities, capturing all the essential details about the ML model and its training process. Moreover, establishing different logging levels (e.g., info, debug, error) to categorize the information being logged can help prioritize critical messages and reduce clutter within the logs.
Integrating or establishing a consistent logging framework, with well-defined logging levels, to capture relevant information during training and evaluation ensures ease of analysis and simplifies the comparison of different models.
Version Control Integration
It is beneficial to integrate the previously mentioned logging framework with your chosen version control system (VCS) like Git or Hopsworks. This allows you to store model-specific logs and logs corresponding to certain versions of training scripts. For example, when configuring your logging framework to associate each log entry with the specific version of the model code it corresponds to, it enables you to trace the evolution of your model and understand how changes to the code impacted its performance reflected in the logs.
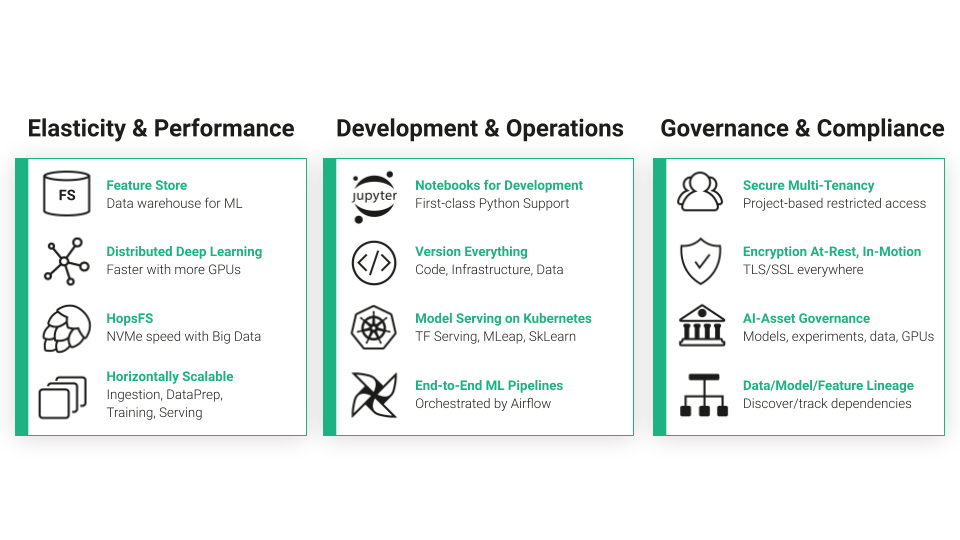
Furthermore, VCS branching strategies allow the creation of separate branches for experimentation, where you can track logs associated with different hyperparameter configurations or training data variations.
Alert and Debugging
Alerts for critical events within the logs that warrant immediate attention can be set up. These could be significant drops in accuracy, unexpected spikes in the loss function, or specific error messages indicating potential issues. Based on different logging levels, alerts can be set up to receive via email notifications, messages in communication platforms like Slack, or monitoring dashboards for real-time visualization.
When alerts arise during the development or deployment of ML models, logs provide sufficient context for troubleshooting. By analyzing log data, developers can identify the root cause of problems and implement appropriate solutions.
By applying these best practices, you can turn your Machine learning logs from a passive record into an active tool for enhancing model development, deployment, and maintenance. Keep in mind that having a well-organized, informative, and readily available logging system enables you to create strong, dependable systems with ML models that live up to their expectations.
Summary
ML models are often viewed as black boxes, but logs provide crucial visibility into the development and deployment process, offering insights into data, models, hyperparameters, and performance over time. This transparency aids in model training and selection, issue diagnosis, understanding strengths and weaknesses of models, and iterative improvement of ML model versions. In addition, post-deployment monitoring ensures continued performance, with logs providing a window into real-world behavior and early detection of potential issues.
In summary, machine learning logs play a pivotal role in the development, deployment, and maintenance of ML models. By capturing essential information about model performance, behavior, and operational metrics, machine learning logs empower practitioners to monitor, troubleshoot, and optimize ML systems effectively. Adopting best practices for logging and leveraging advanced analytics techniques can further enhance the value derived from machine learning logs, driving continuous improvement and innovation in the field of ML.