Data Warehouse
What is a Data Warehouse?
In today's data-driven world, businesses generate and consume vast amounts of data daily. Organizations collect data from a multitude of sources, encompassing sales transactions, customer interactions, social media activity, and sensor readings. With the evolution of data science and machine learning (ML) algorithms, this data has become even more important for decision-making. However, the data often resides in disparate systems, hindering its true potential for revealing valuable insights. To harness its full potential, organizations need a robust system to store, manage, and analyze it efficiently. This is where a data warehouse comes into play.
A data warehouse is a centralized repository designed to store integrated data from multiple disparate sources. It acts as a dedicated environment for historical data, extracted, transformed, and loaded (ETL) from various operational systems. Unlike transactional databases optimized for real-time processing, data warehouses prioritize historical trends and patterns, empowering organizations to gain a comprehensive understanding of their business over time, providing a coherent picture of the business at a point in time or over a period, and facilitating data-driven decision-making. The following are key characteristics of a data warehouse.
- Subject-Oriented: Data warehouses are organized around key subjects or areas of interest, such as sales, finance, or customer information. This organization allows for more effective data analysis and reporting.
- Integrated: Data from different sources is cleaned and integrated into a consistent format within the warehouse, ensuring uniformity and coherence.
- Non-Volatile: Once data is entered into the warehouse, it is not changed or deleted. This immutability ensures historical accuracy and consistency.
- Time-Variant: Data warehouses store historical data, allowing for trend analysis and the examination of changes over time.
What is the Architecture of a Data Warehouse?
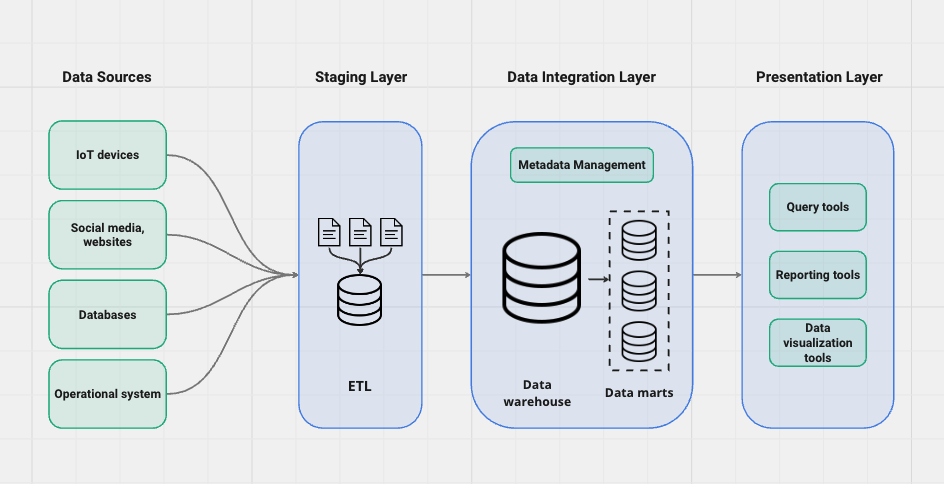
Data warehouse architecture
The foundation of a robust data warehouse hinges on a well-defined architecture. The architecture of a data warehouse can be understood through its three main aspects: the staging layer, the data integration layer, and the presentation layer.
Staging Layer
The staging layer is where raw data from various sources is collected, transformed, and temporarily stored. The temporary storage of the data acts as a buffer for the transformation or loading process before data is loaded into the data warehouse.
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are the two primary methodologies employed here. This process can be scheduled to run at specific intervals or triggered by specific events. The ETL and ELT methodologies play a pivotal role in ensuring data integrity and usability within the data warehouse. While both methods achieve the same end goal, the sequence of steps differs:
- Extract: Data is extracted from different source systems, such as transactional databases, flat files, or external APIs, considering factors like data volume, frequency, and consistency.
- Transform (ETL): In the ETL approach, data is cleansed, standardized, and transformed into a consistent format before being loaded into the data warehouse. This stage may involve: handling missing values; correcting inconsistencies; data validation, enrichment, deduplication, and normalization; deriving new attributes.
- Load (ETL): The transformed data is loaded into the data warehouse, adhering to defined schemas and data models.
- Transform (ELT): In the ELT approach, the raw data is first loaded into the data warehouse in its native format. The transformation process then occurs within the data warehouse itself. This method can be advantageous for large datasets, as it reduces processing time in the staging layer.
Data Integration Layer (data warehouse)
The data integration layer is where the core of the data warehousing process takes place. This layer stores, integrates, and organizes data from different sources into a unified data model for efficient retrieval and analysis. Key components of this layer include:
- Data Modeling: Data warehouses use a dimensional data model, typically employing star schema or snowflake schema designs. These models organize data into fact and dimension tables to optimize query performance and facilitate intuitive data analysis.
- Metadata Management: Metadata, or data about data, is critical for understanding the structure, origin, and meaning of the data stored in the warehouse. Effective metadata management ensures data traceability and usability.
- Data Cubes (data marts): Data warehouses often use online analytical processing (OLAP) cubes to pre-aggregate and summarize data. These multidimensional data structures enable fast and flexible querying.
Presentation Layer
The presentation layer provides access to the data stored in the warehouse. This layer includes tools and interfaces for querying, reporting, and data visualization:
- Query Tools: SQL-based query tools allow users to retrieve and analyze data using structured queries. Tools like Microsoft SQL Server Management Studio (SSMS) or Oracle SQL Developer are commonly used.
- Reporting Tools: Reporting tools such as Microsoft Power BI, Tableau, and SAP BusinessObjects enable users to create detailed reports and dashboards.
- Data Visualization: Data visualization tools help users interpret complex data sets through graphical representations like charts, graphs, and maps.
Dimensional Modeling in the Data Integration Layer
A crucial aspect of data warehouse design is the adoption of dimensional modeling specifically to facilitate efficient querying and analysis. It revolves around two key elements:
- Dimensions: These represent the descriptive attributes or categories that provide context for the data being analyzed. Examples of dimensions in a sales data warehouse could be customer demographics (age, location), product categories, time periods (year, month), or sales channels.
- Facts: These are the quantitative measures or metrics that represent the actual data points you're interested in analyzing. In the sales data warehouse example, facts could include sales amount, quantity sold, profit margin, or number of units sold.
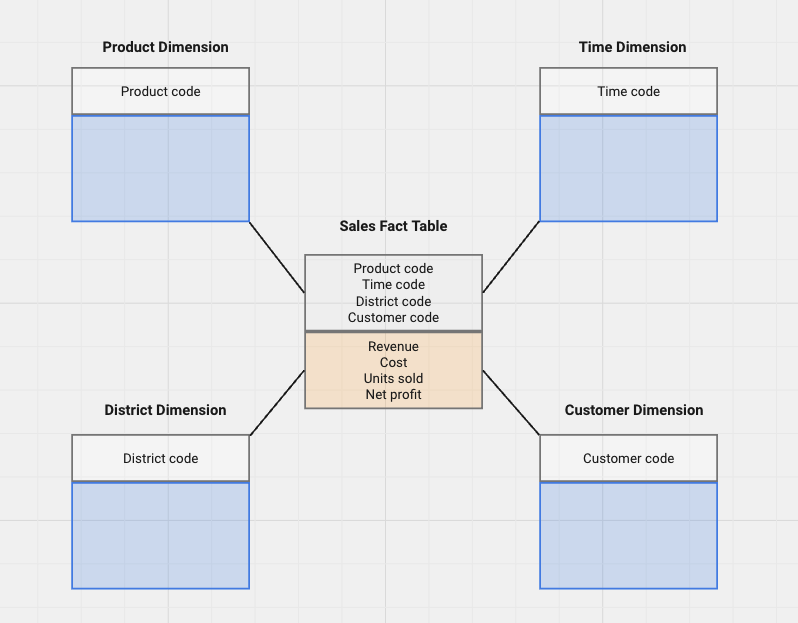
Dimensional modeling helps data warehouses in making analysis easier. Users can easily and efficiently query and explore the data from various angles. Most importantly, dimensional models present data clearly, separating descriptive details from quantitative measures. This user-friendly approach leads to better data understanding and wider adoption of the data warehouse for data-driven decisions. The most common dimensional models include:
- Star Schema: A widely used model with a central fact table surrounded by dimension tables. Each dimension table is linked to the fact table through a foreign key relationship. This model offers efficient query performance for analytical workloads.
- Snowflake Schema: An extension of the star schema, where dimension tables are further normalized to reduce data redundancy. This approach improves data integrity but may lead to slightly more complex queries due to the increased number of joins required.
Open-source Formats in Data Warehouse
While traditional data warehouses might rely on proprietary formats, there's a growing trend towards open-source formats that offer flexibility and cost efficiency.
Open-source File Formats
In data warehousing, file formats like Apache Parquet, Apache ORC (Optimized Row Columnar), and Apache Avro are essential for efficient data storage and processing. Parquet and ORC are columnar storage formats optimized for big data applications, enabling high compression ratios and fast query performance by storing data in a column-wise fashion. These formats are particularly effective for read-heavy analytical workloads, as they reduce storage costs and enhance I/O efficiency. Avro, on the other hand, is a row-based storage format designed for efficient data serialization, making it ideal for data exchange and streaming applications. Avro's schema-based approach ensures compatibility and flexibility, facilitating seamless data interchange across different platforms and languages.
Open-source Table Formats
Open-source table formats such as Apache Iceberg, Delta Lake, and Apache Hudi play a critical role in data lake integration (make a data lake work as a data warehouse) by providing advanced data management capabilities. These formats support schema evolution, allowing users to make changes to the data schema without disrupting existing datasets. They also offer ACID (Atomicity, Consistency, Isolation, Durability) transactions, ensuring data reliability and consistency, even in environments with concurrent read and write operations. Iceberg simplifies partition management and supports time travel for historical data queries, while Delta Lake enforces schema constraints and provides robust versioning capabilities. Hudi excels in incremental data processing, supporting inserts and deletes, and includes built-in indexing to speed up data retrieval.
Open-source table formats enable data lakes to function like data warehouses to some extent, offering features like schema enforcement, data versioning, and ACID transactions (Atomicity, Consistency, Isolation, Durability). This allows for seamless data movement and transformation between data lakes and data warehouses.
Open Query Engines
Query engines and frameworks like Apache Hive, Apache Spark, Apache Druid, and Presto are indispensable for querying and analyzing large datasets in data warehouses. Hive offers a SQL-like interface (HiveQL) on top of Hadoop, making it accessible for users familiar with SQL and suitable for batch processing tasks. Spark, with its in-memory computing capabilities, provides a unified analytics engine for various data processing workloads, including real-time streaming and machine learning. Druid is designed for real-time analytics, offering low-latency querying and real-time data ingestion, making it ideal for operational analytics. Presto stands out for its ability to query data across multiple heterogeneous sources, providing high performance, low latency, and scalability for interactive querying and reporting. These query engines enhance the flexibility, performance, and accessibility of data analytics in modern data warehousing environments.
What are the Limitations of a Data Warehouse?
Data warehouses face significant limitations in today's data landscape. They are primarily designed to handle structured data, making it difficult to integrate and process unstructured and semi-structured data types such as text, images, and JSON files. This focus on structured data requires extensive preprocessing and transformation, adding complexity and delays in data availability.
Moreover, data warehouses are optimized for batch processing, resulting in latency and delayed insights, which is inadequate for real-time data processing needs. The complexity of ETL processes and schema rigidity further limit their flexibility and agility. Ensuring high data quality and robust governance is challenging, particularly with inconsistent data from various sources. Resource contention and concurrency issues can lead to performance bottlenecks, impacting overall system efficiency.
These limitations highlight the need for more advanced data management solutions, such as data lakehouse, that can handle diverse data types, offer real-time processing, and provide scalable, cost-effective architectures.
Summary
A data warehouse is a powerful tool for organizations seeking to leverage their data for strategic decision-making. By providing a centralized, integrated, and high-performance environment for data analysis and reporting, data warehouses enable businesses to gain valuable insights and maintain a competitive edge. As data continues to grow in volume and complexity, and the increasing needs for supporting diverse data types and real-time processing, the importance of data management will only increase, while data warehouses show limitations.