vLLM
What is vLLM?
Nowadays large language models (LLMs) have revolutionized various domains. However, deploying these models in real-world applications can be challenging due to their high computational demands. This is where vLLM steps in. vLLM stands for Virtual Large Language Model and is an active open-source library that supports LLMs in inferencing and model serving efficiently.
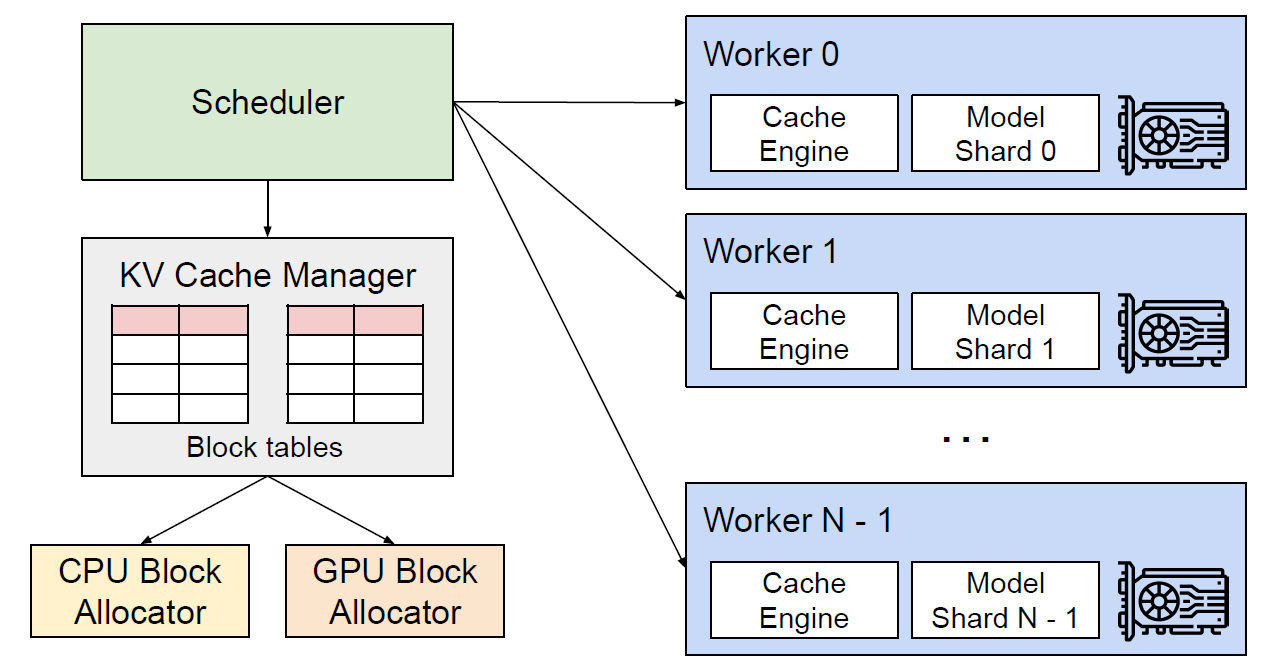
vLLM was first introduced in a paper - Efficient Memory Management for Large Language Model Serving with PagedAttention, authored by Kwon et al. The paper identifies that the challenges faced when serving LLMs are memory allocation and measures their impact on performance. Specifically, it emphasizes the inefficiency of managing Key-Value (KV) cache memory in current LLM serving systems. These limitations can often result in slow inference speed and high memory footprint.
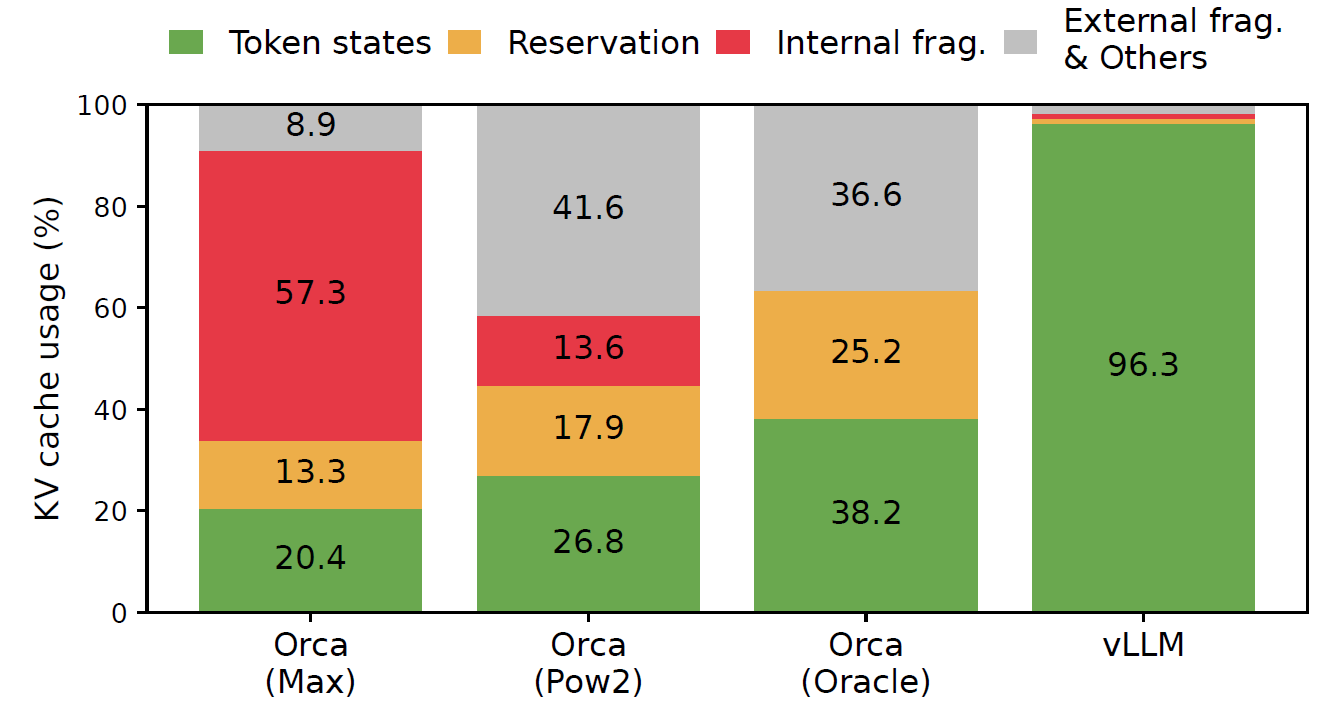
Memory usage and waste in different LLM serving systems.
To address this, the paper presents PagedAttention, an attention algorithm inspired by virtual memory and paging techniques commonly used in operating systems. PagedAttention enables efficient memory management by allowing for non-contiguous storage of attention keys and values. Following this idea, the paper develops vLLM, a high-throughput distributed LLM serving engine that is built on PagedAttention. vLLM achieves near-zero waste in KV cache memory, significantly improving serving performance. Moreover, leveraging techniques like virtual memory and copy-on-write, vLLM efficiently manages the KV cache and handles various decoding algorithms. This results in 2-4 times throughput improvements compared to state-of-the-art systems such as FasterTransformer and Orca. This improvement is especially noticeable with longer sequences, larger models, and complex decoding algorithms.
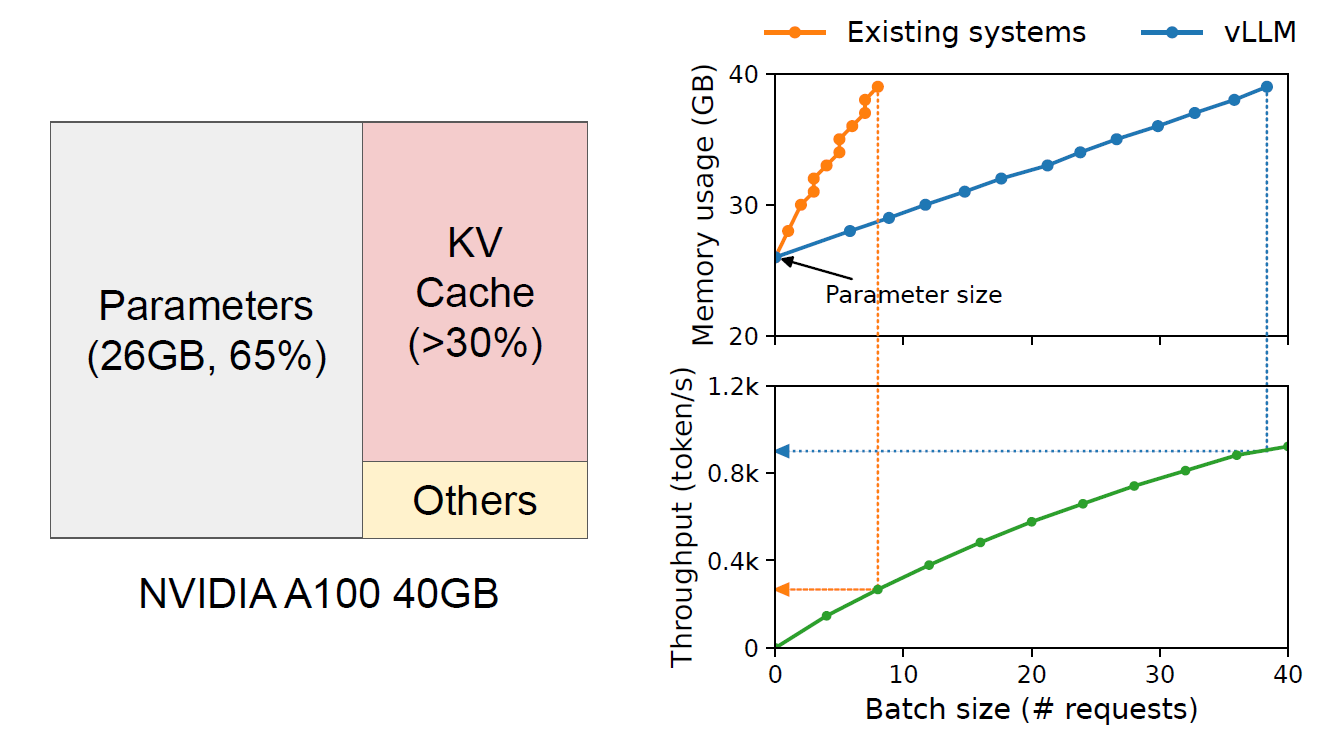
Illustration of vLLM’s performance in optimizing memory usage and boosting serving throughput.
What is the core idea in vLLM?
PagedAttention
The attention mechanism allows LLMs to focus on relevant parts of the input sequence while generating output/response. Inside the attention mechanism, the attention scores for all input tokens need to be calculated. Existing systems store KV pairs in contiguous memory spaces, limiting memory sharing and leading to inefficient memory management.

KV cache memory management in existing systems.
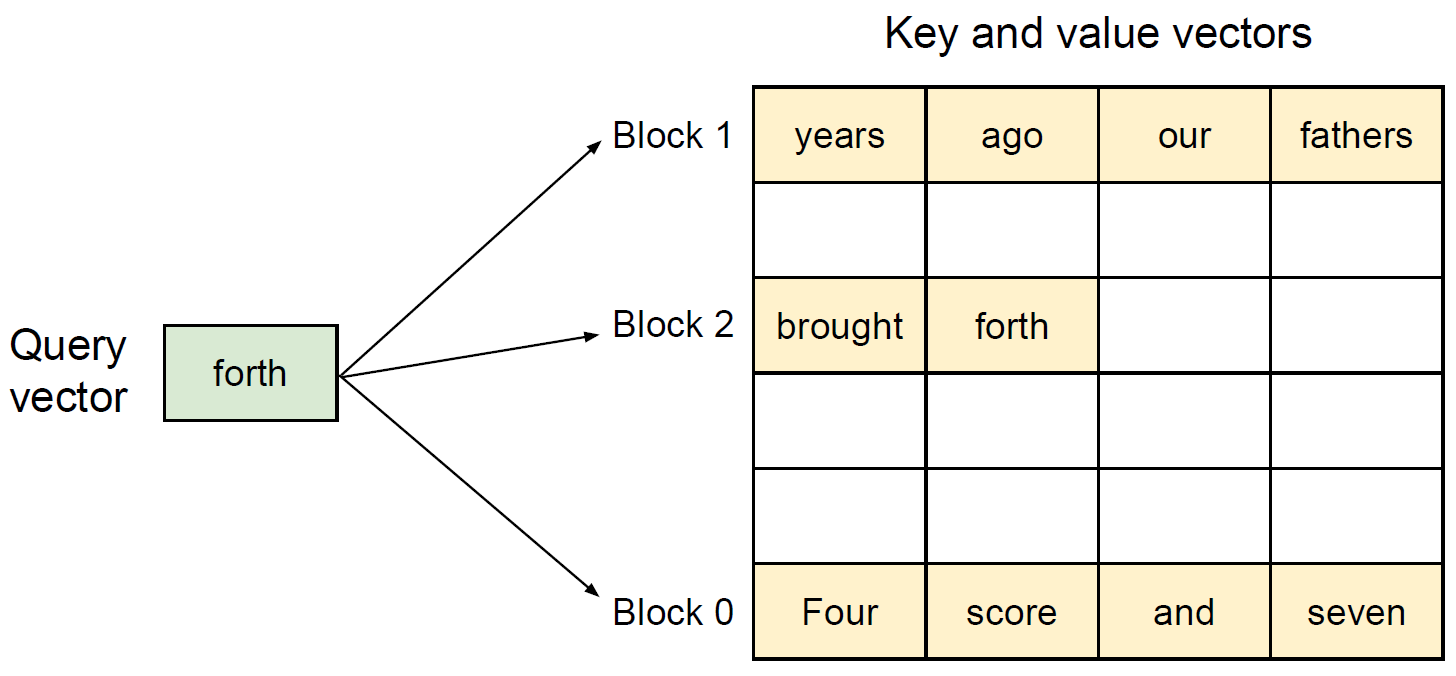
PagedAttention is an attention algorithm inspired by the concept of paging in operating systems. It allows storing continuous KV pairs in non-contiguous memory space by partitioning the KV cache of each sequence into KV block tables. This way, it enables the flexible management of KV vectors across layers and attention heads within a layer in separate block tables, thus optimizing memory usage, reducing fragmentation, and minimizing redundant duplication.
What are the other techniques used in vLLM for efficient serving?
vLLM doesn't stop at PagedAttention. It incorporates a suite of techniques to further optimize LLM serving.
-
Continuous Batching: Incoming requests are continuously batched together to maximize hardware utilization and reduce computing waste, minimizing idle time.
-
Quantization: vLLM utilizes quantization techniques like FP16 to optimize memory usage by representing the KV cache in reduced precision, leading to smaller memory footprints and faster computations.
-
Optimized CUDA Kernels: vLLM hand-tunes the code executed on the GPU for maximum performance. For example, for fused reshape and block write, optimized kernels are developed to split the new KV cache into blocks, reshape them for efficient memory access, and save them based on a block table, all fused into a single kernel to reduce overheads.
How to use vLLM?
vLLM is easy-to-use. Here is a glimpse into how it can be used in Python:
One can install vLLM via pip:
Offline inference
Then import the vLLM module into your code and do an offline inference with vLLM’s engine. The LLM class is to initialize the vLLM engine with a specific built-in LLM model. The LLM models are by default downloaded from HuggingFace. The SamplingParams class is to set the parameters for inferencing.
Then we define an input sequence and set the sampling parameters. Initialize vLLM’s engine for offline inference with the LLM class and an LLM model:
Finally, the output/response can be generated by:
The code example can be found here.
Online serving
To use vLLM for online serving, OpenAI’s completions and APIs can be used in vLLM. The server can be started with Python:
To call the server, the official OpenAI Python client library can be used. Alternatively, any other HTTP client works as well.
More examples can be found on the official vLLM documentation.
What are the use cases of vLLM?
vLLM's efficient operation of LLMs opens numerous practical applications. Here are some compelling scenarios that highlight vLLM's potential:
-
Revolutionizing Chatbots and Virtual Assistants: With its efficient serving support, vLLM can contribute chatbots and virtual assistants to hold nuanced conversations, understand complex requests, and respond with human-like empathy. By enabling faster response times and lower latency, vLLM ensures smoother interactions. Additionally, vLLM empowers chatbots to access and process vast amounts of information, allowing them to provide users with comprehensive and informative answers. vLLM's ability to handle diverse creative text formats can be harnessed to craft personalized responses that address the user's specific needs and preferences. This combination of speed, knowledge, and adaptability can transform chatbots from simple FAQ machines into invaluable tools for customer service, technical support, and even emotional counseling.
-
Democratizing Code Generation and Programming Assistance: The field of software development is constantly evolving, and keeping pace with the latest technologies can be challenging. vLLM can act as a valuable companion for programmers of all experience levels. By leveraging its code-understanding capabilities, vLLM can suggest code completions, identify potential errors, and even recommend alternative solutions to coding problems. This can significantly reduce development time and improve code quality. vLLM's ability to generate documentation can also alleviate a major pain point for developers. Automatically generating clear and concise documentation based on the written code would save developers valuable time and effort, and the quality and consistency of the documentation can also be controlled. vLLM can be used to create educational tools that introduce coding concepts in a fun and interactive way, making programming more accessible to students and aspiring developers.
Why Choose vLLM for Optimized LLM Deployment?
vLLM is quickly becoming a preferred solution for those looking to optimize their Large Language Model (LLM) deployments. Traditional LLM frameworks often require extensive resources and infrastructure, which can be costly and challenging to scale. However, vLLM is designed specifically for efficient memory management, leveraging a sophisticated paging mechanism that reduces the memory footprint and enhances overall performance. By adopting vLLM, teams can reduce hardware costs while improving inference speed and efficiency, especially when scaling up for high-demand applications. This makes vLLM ideal for organizations aiming to deploy LLMs at scale without sacrificing speed or requiring extensive resources.
How vLLM Integrates with Hopsworks for MLOps
When combined with Hopsworks, vLLM seamlessly integrates into a robust MLOps pipeline, enabling teams to deploy, monitor, and optimize LLM applications with ease. Hopsworks offers end-to-end MLOps capabilities, such as experiment tracking, model versioning, and monitoring, which can be directly applied to manage vLLM deployments. Additionally, Hopsworks’ feature store provides data consistency and high performance, critical for training and deploying LLMs. By integrating vLLM with Hopsworks, MLOps teams gain a scalable, efficient way to manage and monitor large-scale LLM deployments effectively, bringing the benefits of vLLM optimization into the broader MLOps ecosystem. With Hopsworks 4.0 you can build and operate LLMs end to end, creating instruction datasets and fine tuning, to model serving with vLLM on KServe, to monitoring and RAG. We added a vector index to our feature store, so now in a single feature pipeline you can both index your documents for RAG and create instruction datasets.
Hopsworks provides two ways of deploying LLMs with vLLM
vLLM OpenAI server
The vLLM project provides an implementation of an OpenAI-compatible server that initializes a vLLM engine, loads a given LLM, and handles incoming user prompts at endpoints following the OpenAI’s Completions and Chat API. Hopsworks enables users to deploy LLMs using the vLLM OpenAI server by providing a configuration YAML file containing the parameters to be passed to the vLLM OpenAI server. These parameters include information about the tokenizer, the tool parser used for extracting tool calls from answers (used for function calling [link-to-mlops-function-calling]), and the chat template, among other things. The list of all available parameters can be found in the vLLM OpenAI server documentation.
For example, to deploy a fine-tuned Llama3.1 model using the vLLM OpenAI server in Hopsworks, you can pass the server configuration file in the config_file parameter as shown in the code snippet below.
Pros:
- No code needs to be implemented for handling completion requests.
- The vLLM OpenAI server can handle tokenizers, chat templates and tool parsers internally.
- All LLMs supported by vLLM (see complete list here) can be deployed following this approach.
Cons:
- Less flexible. The vLLM OpenAI server can only be customized via configuration file. Although this is sufficient for most cases, it is not possible to customize it beyond the supported configuration parameters.
KServe vLLM server
Alternatively, Hopsworks supports a second, more customizable approach for deploying LLMs with vLLM that allows users to initialize the vLLM engine and provide their own implementation of the /chat/completions and /completions endpoints. This approach leverages a KServe-provided OpenAI-compatible server that offers a default implementation of the endpoints to handle completion requests and user prompts, but that allows users to override these methods.
For example, to deploy a fine-tuned Llama3.1 model using the KServe vLLM server in Hopsworks, you can implement the predictor script and pass it in the script_file parameter as shown in the code snippet below. Optionally, you can also pass a configuration file that will be available inside the server.
Pros:
- More flexible. Users can manually initialize the vLLM engine and provide a modified implementation of the /chat/completions and /completions endpoints.
Cons:
- It can be cumbersome for non-experienced users.
- At the moment, the KServe vLLM server does not support tool parsers and, therefore, all features of vLLM-supported models might not be available (e.g., function calling for Mistral models).
Summary
vLLM addresses a critical bottleneck in LLM deployment: inefficient inferencing and serving. Using the innovative PagedAttention technique, vLLM optimizes memory usage during the core attention operation, leading to significant performance gains. This translates to faster inference speeds and the ability to run LLMs on resource-constrained hardware. Beyond raw performance, vLLM offers advantages like scalability and cost-efficiency. With its open-source nature and commitment to advancement, vLLM positions itself as a key player in the future of LLM technology.