Model Serving
What is Model Serving?
Model serving refers to the process of deploying and making ML models available for use in production environments as network invokable services. In simpler terms, it's about taking a trained ML model and making it accessible for real-world applications via a REST or gRPC API. In particular, model serving involves setting up an infrastructure or system that can host ML models and handle network requests to the ML model and provide predictions in real-time.
Model serving is crucial for integrating ML models into applications and services that people use. For example, a recommendation system on an e-commerce website might use model serving to recommend products to users based on their browsing history. It's like setting up a server or a service that constantly listens for input data (e.g., users’ browsing history), sends it to the ML recommendation model, gets the prediction from the model, and sends the result (e.g., recommended products tailored to specific users) back to the requester.
What Features does Model Serving support?
One key feature of model serving is that it allows multiple applications to access the same ML model. Consider a regular system where all components are tightly integrated into a single program, an ML model can be directly embedded within the system. This kind of system is called a monolithic system. The typical drawback of a monolithic system containing an ML model is that the model is not made available for use outside the system. If multiple applications within an organization or environment need to use the same ML model, each application must have its own copy of the model. This can lead to operational challenges, especially in managing and updating these copies. Model serving provides a more efficient way by exposing the ML model applications through API to make it accessible by several applications at the same time without each application having to maintain their own copy.
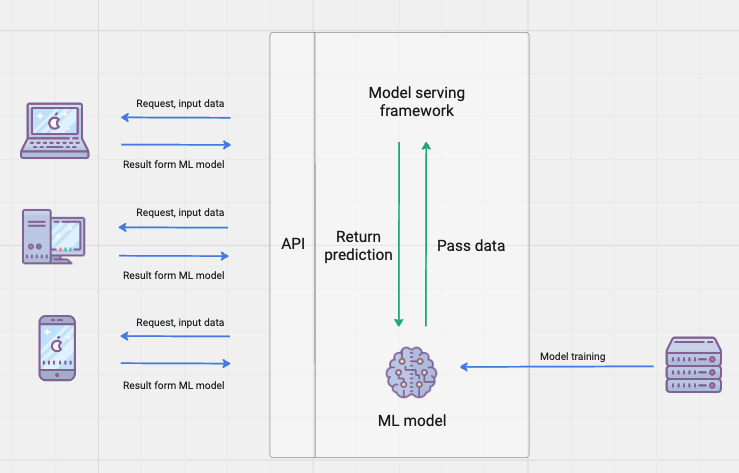
For example, imagine a large e-commerce platform that uses an ML model to make product recommendations. In a monolithic system, this recommendation ML model is tightly integrated into the e-commerce application. Now, let's say the same ML model is also needed for a mobile app, a chatbot, and a separate analytics tool used by the marketing team.
If we employ the monolithic approach:
- Each application (e-commerce platform, mobile app, chatbot, analytics tool) has its own embedded copy of the recommendation model.
- The lifecycle of the model and the application are tightly coupled.
- Updating the model or making improvements requires redeploying the application, leading to maintenance challenges.
While using the API-based approach provided by model serving:
- The recommendation model is hosted separately and exposed through API.
- All applications, including the e-commerce platform, mobile app, chatbot, and analytics tool, can access the recommendation model through the API.
- Updates or improvements to the model can be implemented centrally without changing each application, making it easier to manage.
In this example, model serving through an API simplifies the process of sharing and using the ML model across multiple applications, providing a more scalable and manageable solution for MLOps.
Furthermore, in a production environment, model serving needs to be efficient and scalable. This means handling a large number of requests, ensuring low latency, and managing resources effectively.
In real-world scenarios, models may need to be updated with new data to stay relevant. Model serving systems should also support this process seamlessly, allowing for easy updates without disrupting the entire system.
What are existing Frameworks and Tools for Model Serving?
Various frameworks and tools exist to help with model serving, such as KServe, TensorFlow Serving, TorchServe.
Fast API Server (roll-your-own)
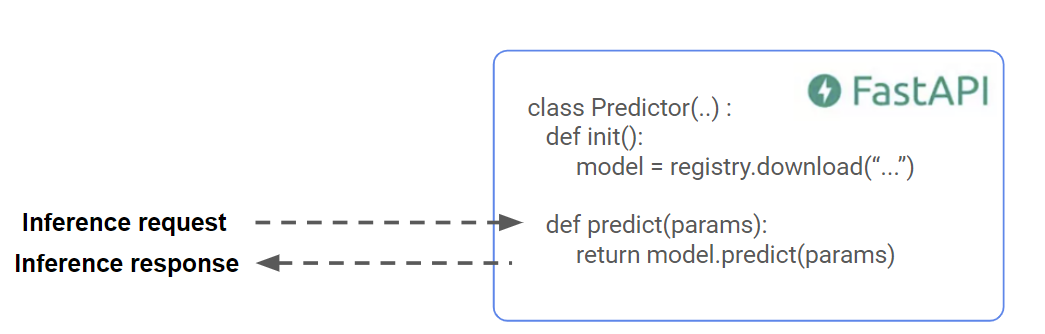
This is a quick and dirty way to implement model serving. You wrap your model in a Fast API server. This has the benefit of supporting both HTTP and gRPC network protocols - gRPC if you need very low latency. However, you will ultimately have to implement security, logging, monitoring, A/B testing, and more to get a production quality model serving server.
KServe
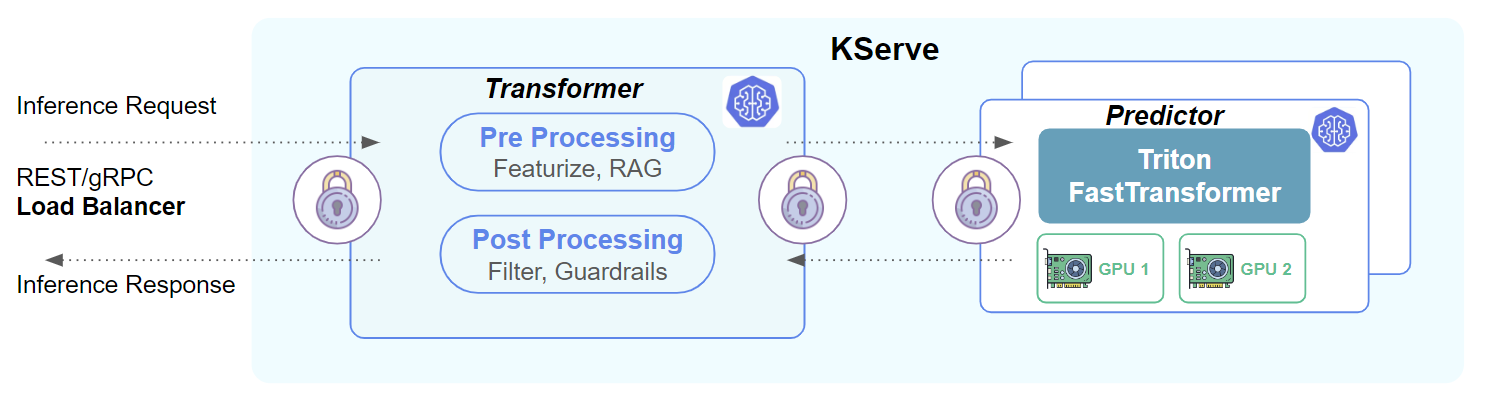
KServe is an open-source Kubernetes-native model serving framework designed to simplify the deployment and scaling of ML models in production on Kubernetes clusters. KServe has rich support for production quality model serving with support for encrypted network communications, load balancing, A/B testing, logging, monitoring, and GPUs. KServe wraps a model serving engine inside these Enterprise features, supporting Seldon, Triton, TensorFlow Model Serving Server, TorchServe, and vLLM.
TensorFlow ModelServing Server
TensorFlow ModelServing Server is a powerful tool in the realm of model serving, providing a dedicated infrastructure for deploying and managing ML models, particularly those built with the TensorFlow framework. Model serving is a critical aspect of deploying ML models for real-world applications, and TensorFlow Serving excels in this domain by offering a scalable and efficient solution. It allows software engineers to expose TensorFlow models through well-defined APIs, making them accessible to multiple applications. With TensorFlow Serving, model serving becomes more streamlined, as it supports features like model versioning for A/B testing and smooth updates. Its compatibility with different TensorFlow versions, RESTful API support, and integration capabilities with systems like Kubernetes contribute to a robust and user-friendly environment for serving ML models in production. For software engineers seeking a reliable and scalable solution for deploying TensorFlow models and embracing best practices in model serving, TensorFlow Serving proves to be an invaluable tool.
TorchServe
TorchServe is an open-source model serving library developed by AWS in collaboration with PyTorch, designed to simplify the deployment and management of ML models built using the PyTorch framework. As an integral part of the model serving ecosystem, TorchServe caters to the needs of software engineers by providing a dedicated infrastructure for deploying PyTorch models in production environments. Just as TensorFlow Serving excels in serving TensorFlow models, TorchServe excels in serving PyTorch models, offering features such as model versioning, multi-model serving, and robust management capabilities. It empowers software engineers to expose PyTorch models through a customizable API, facilitating seamless integration with various applications. With its focus on scalability, ease of use, and compatibility with PyTorch, TorchServe stands as a valuable tool for software engineers aiming to efficiently deploy and manage PyTorch ML models in real-world applications.
What is the Difference between Model Serving and Model Deployment?
Model serving and model deployment are closely related but have distinct meanings. Model deployment is the process of deploying a machine learning model to a model serving server to serve prediction requests. Deployment encompasses all the steps from taking a trained model and making it accessible to real-world applications via a network API. To make matters even more complicated, a model deployment (as a proper noun, not an abstract noun!) means a model that is currently being served by model serving infrastructure.
Models used by batch inference pipelines do not typically need to be deployed - they are downloaded from a model registry when inference is going to be informed. The only exception for batch inference pipelines is if the model cannot be downloaded (if it is too large or because it is only available as a hosted service (like GPT-4)). In such cases, the batch application makes batches of network requests to the model deployment.
On the other hand, model serving is the infrastructure that supports accepting prediction requests from clients and routing the requests to model deployments and returning the predictions to the clients.
In essence, model deployment is the overarching process that includes all the steps from training a model to making it usable in the real world. Model serving, however, specifically deals with the network and model hosting infrastructure , the runtime aspect of handling requests and providing predictions. So, to put it simply, model deployment is a process to take a trained model and deploy it to model serving infrastructure from where it can accept prediction requests and provide predictions as responses. The model hosted in model serving infrastructure is known as a model deployment. .
Summary
In summary, model serving is the bridge between the trained ML model and its use in interactive (real-time) applications. It enables models to be deployed as network services that can handle incoming prediction requests, make predictions, and return prediction responses. Model serving enables models to be seamlessly integrated into interactive and real-time software systems for various applications. Unlike the approach of embedding models in applications, modern model serving emphasizes exposing models through APIs. This paradigm shift is exemplified by frameworks like KServe, TensorFlow Serving and TorchServe, which provide dedicated infrastructure with capabilities such as scalability, versioning, and compatibility with platforms like Kubernetes. By adopting model serving, organizations can enhance the manageability, scalability, and flexibility of their ML deployments, ensuring easier integration and updates in dynamic production settings.