Model Deployment
What is a model deployment?
A model deployment enables clients to perform inference requests on the machine learning (ML) model over a network. As such, model deployments are used in real-time, interactive ML systems (but, not typically in batch ML systems, stream processing ML systems or embedded/edge ML systems). Models can be created (trained) using ML frameworks such as Scikit-Learn, PyTorch, Tensorflow, XGBoost, and so on.
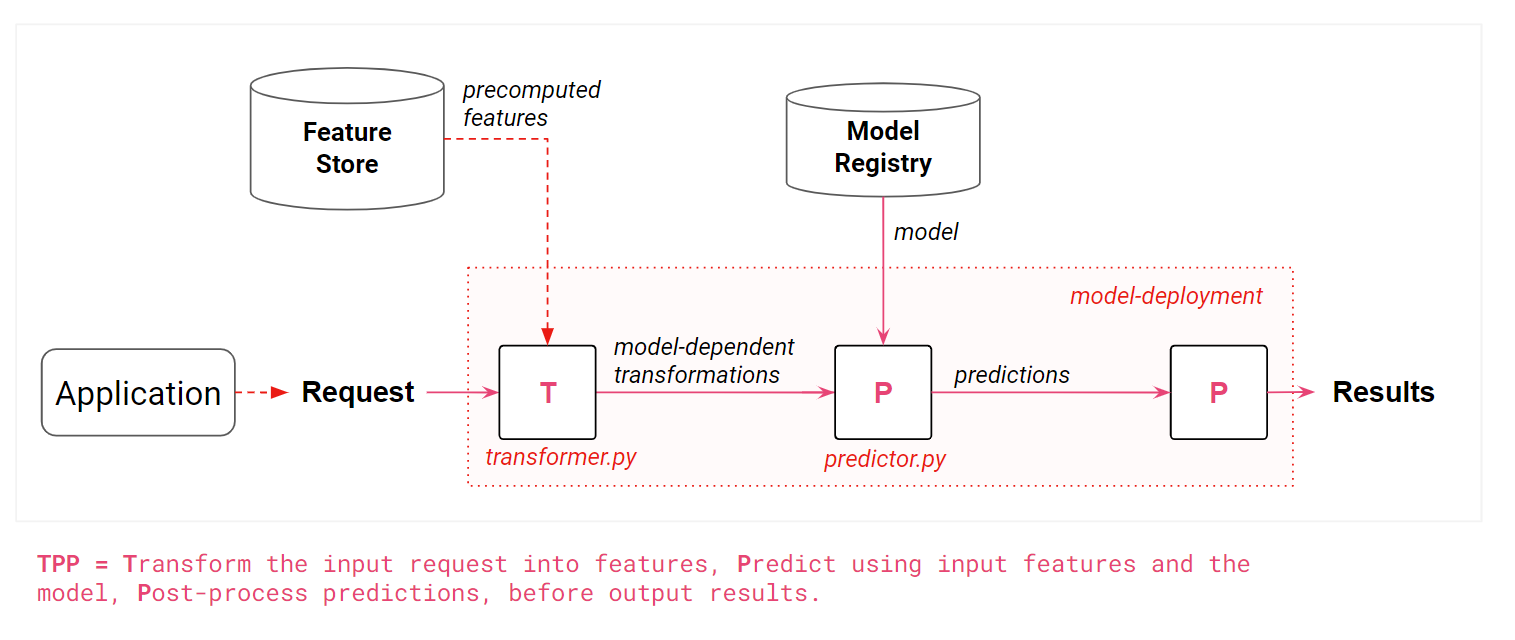
Trained models are typically stored and versioned in a model registry. Typically, a model deployment is loaded from a model registry to model-serving infrastructure, such as KServe, Seldon, Sagemaker, or MLFlow, from where it serves requests to clients. Model serving infrastructure adds important system properties such as:
- providing a discoverable network endpoint for clients to use when making model requests,
- encryption-in-transit of network traffic to and from the model deployment,
- authentication of clients and access control to the model deployment, elastic
- scaling (up and down) in response to an increased/decreased rate of requests on the model deployment,
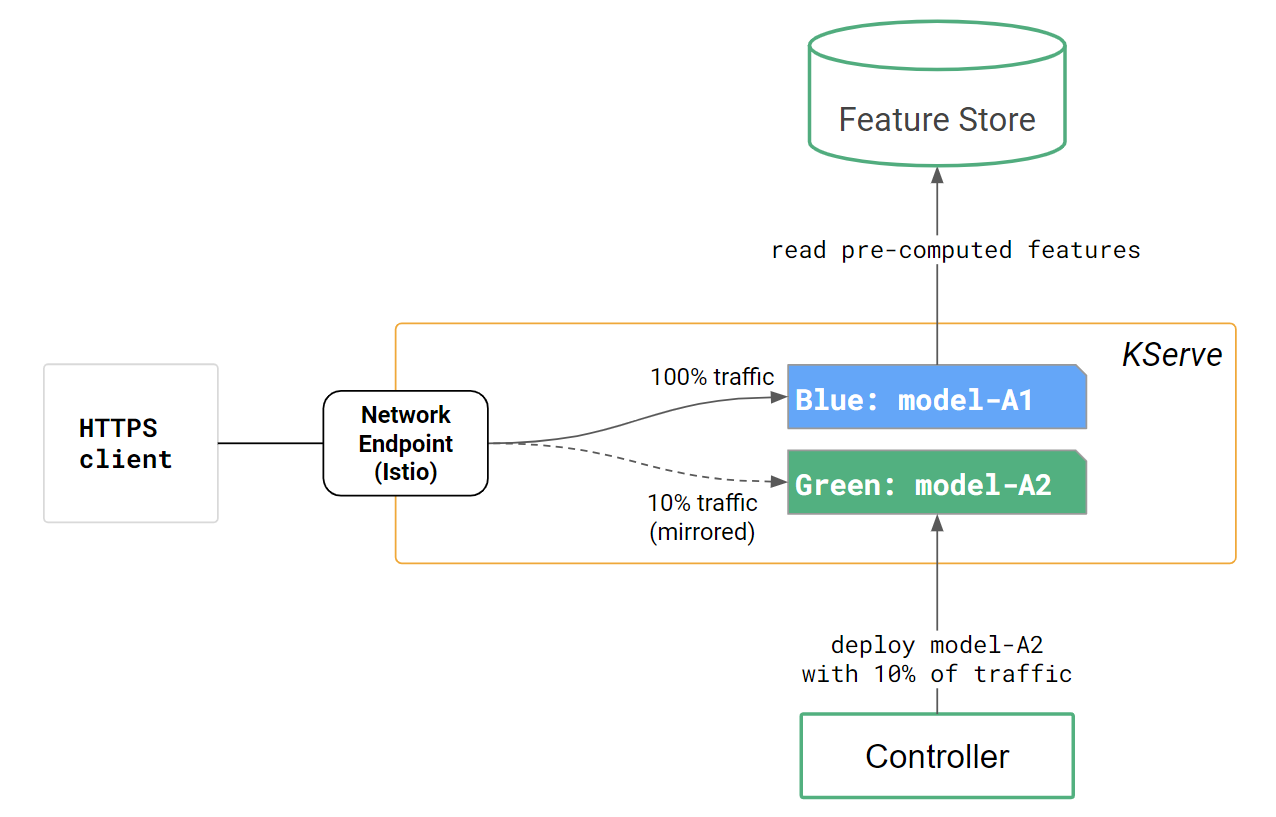
- A/B testing or the ability to chain model deployments (the output of one model is the input to another model),
- multi-model serving (so multiple model deployments can be packed into a single container),
- and integration with a feature store (to provide historical/contextual precomputed features).
How do you create a model deployment?
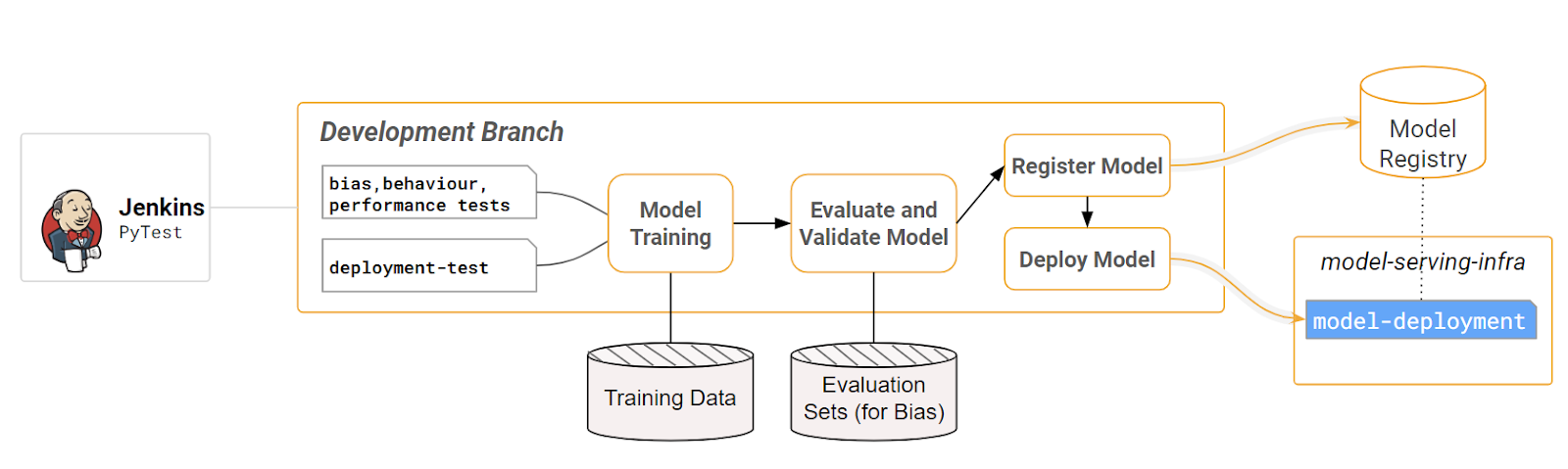
A trained model, in a model registry, can be downloaded to create a model deployment with either API calls in a programming language or manually with a user interface. The advantage of writing a program to deploy a model is that the model deployment can then be automated as part of a CI/CD pipeline, see above figure. Model deployments require converting the saved model into a format that can be deployed to the model serving infrastructure from where it can handle requests from clients over the network in real-time, and where the model can be replicated to support scaling up a model deployment. This typically involves containerizing the model before deploying it to model-serving infrastructure.
Do I always need to deploy my model?
No, not all machine learning projects require model deployment. For instance, if your project involves offline analysis, batch processing, or one-time predictions, deploying the model may not be necessary as a batch inference pipeline may be good enough, see the different types of ML systems.
It is also possible to embed the model in your interactive application, for example, if the model is trained in a Python-based ML framework and the interactive application is written in Python. However, interactive applications can benefit from deploying a model to model serving infrastructure, if they want to decouple the lifecycle of the model from the application - so you can update the model, without having to also update the application. Model deployments can also be scaled up/down, reused over many applications.
Model Deployments in Hopsworks
Hopsworks supports model serving with KServe, a model registry designed for KServe, and a feature store that is integrated with KServe deployments.