Hopsworks Online Feature Store: Fast Access to Feature Data for AI Applications
Read about how the Hopsworks Feature Store abstracts away the complexity of a dual database system, unifying feature access for online and batch applications.

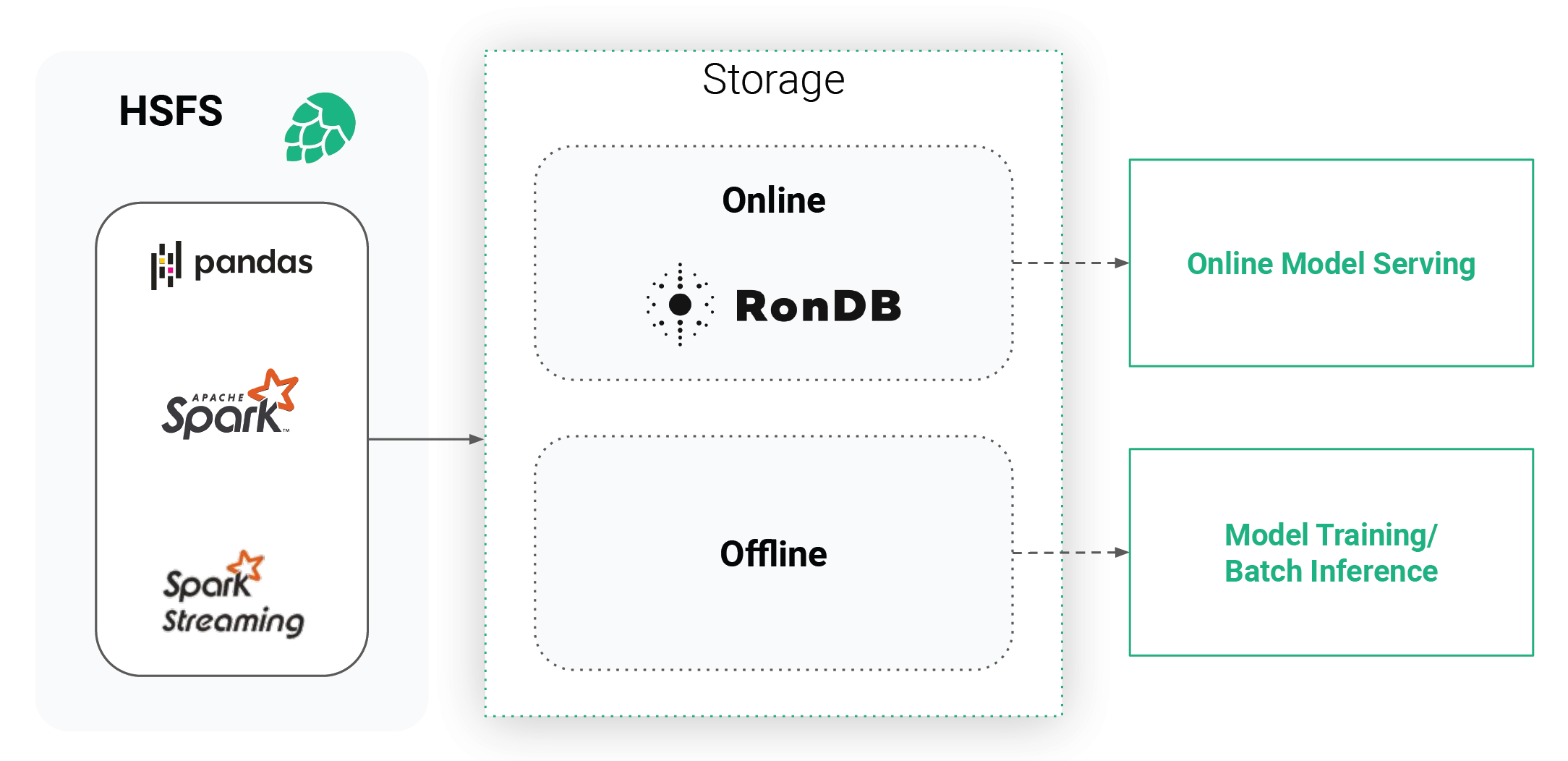
Figure 1. Hopsworks Feature Store
Enterprise Machine Learning models are most valuable when they are powering a part of a product by guiding user interaction. Oftentimes these ML models are applied to an entire database of entities, for example users identified by a unique primary key. An example for such an offline application, would be predictive Customer Lifetime Value, where a prediction can be precomputed in batches in regular intervals (nightly, weekly), and is then used to select target audiences for marketing campaigns. More advanced AI-powered applications, however, guide user interaction in real-time, such as recommender systems. For these online applications, some part of the model input (feature vector) will be available in the application itself, such as the last button clicked on, while other parts of the feature vector rely on historical or contextual data and have to be retrieved from a back end storage, such as the number of times the user clicked on the button in the last hour or whether the button is a popular button.
In this blog, we are going to dive into the details of the requirements of online applications and how the Hopsworks Feature Store abstracts away the complexity of a dual storage system.
Machine Learning Models in Production
While batch applications with (analytical) models are largely similar to the training of the model itself, requiring efficient access to large volumes of data that will be scored, online applications require low latency access to latest feature values for a given primary key (potentially, multi-part) which is then sent as a feature vector to the model serving instance for inference.
To the best of our knowledge there is no single database accommodating both of these requirements at high performance. Therefore, data teams tended to keep the data for training and batch inference in data lakes, while ML engineers built microservices to replicate the feature engineering logic in micro services for online applications.
This, however, introduces unnecessary obstacles for both Data Scientists and ML engineers to iterate quickly and significantly increases the time to production for ML models:
- Data science perspective: Tight coupling of data and infrastructure through microservices, resulting in Data Scientists not being able to move from development to production and not being able to reuse features.
- ML engineering perspective: Large engineering effort to guarantee consistent access to data in production as it was seen by the ML model during the training process.
Hopsworks Feature Store: A Transparent Dual Storage System
The Hopsworks Feature Store is a dual storage system, consisting of the high-bandwidth (low-cost) offline storage and the low-latency online store. The offline storage is a mix of Apache Hudi tables on our HopsFS file system (backed by S3 or Azure Blob Storage) and external tables (such as Snowflake, Redshift, etc), together , providing access to large volumes of feature data for training or batch scoring. In contrast, the online store is a low latency key value database that stores only the latest value of each feature and its primary key. The online feature store thereby acts as a low latency cache for these feature values.
In order for this system to be valuable for data scientists and to improve the time to production, as well as providing a nice experience for the end user, it needs to meet some requirements:
- Consistent Features for Training and Serving: In ML it’s of paramount importance to replicate the exact feature engineering logic for features in production as was used to generate the features for model training.
- Feature Freshness: A low latency, high throughput online feature store is only beneficial if the data stored in it is kept up-to-date. Feature freshness is defined as the end-to-end latency between an event arriving that triggers a feature recomputation and the recomputed feature being published in the online feature store.
- Latency: The online feature store must provide near real-time low latency and high throughput, in order for applications to be able to use as many features as possible with its available SLA.
- Accessibility: The data needs to be accessible through intuitive APIs, and just as easily as the extraction of data from the offline feature store for training.
The Hopsworks Online Feature Store is built around four pillars in order to satisfy the requirements while scaling to manage large amounts of data:
- HSFS API: The Hopsworks Feature Store library is the main entry point to the feature store for developers, and is available for both Python and Scala/Java. HSFS abstracts away the two storage systems, providing a transparent Dataframe API (Spark, Spark Structured Streaming, Pandas) for writing and reading from online and offline storage.
- Metadata: Hopsworks can store large amounts of custom metadata in order for Data Scientists to discover, govern, and reuse features, but also to be able to rely on schemas and data quality when moving models to production.
- Engine: The online feature store comes with a scalable and stateless service that makes sure your data is written to the online feature store as fast as possible without write amplification from either a data stream (Spark Structured Streaming) or from static Spark or Pandas Dataframes. By write amplification , we mean that you do not have to first materialize your features to storage before ingesting them - you can write directly to the feature store.
- RonDB: The database behind the online store is the world’s fastest key-value store with SQL capabilities. Not only building the base for the online feature data, but also handling all metadata generated within Hopsworks.
We will cover each of these in detail in the following sections and provide some benchmarks for quantitative comparison.
RonDB: The Online Feature Store, Foundation of the File System and Metadata
Hopsworks is built from the ground up around distributed scaleout metadata. This helps to ensure consistency and scalability of the services within Hopsworks as well as the annotation and discoverability of data and ML artifacts.
Since the first release, Hopsworks has been using NDB Cluster (a precursor to RonDB) as the online feature store. In 2020, we created RonDB as a managed version of NDB Cluster, optimized for use as an online feature store.
However, in Hopsworks, we use RonDB for more than just the Online Feature Store. RonDB also stores metadata for the whole Feature Store, including schemas, statistics, and commits. RonDB also stores the metadata of the file system, HopsFS, in which offline Hudi tables are stored. Using RonDB as a single metadata database, we use transactions and foreign keys to keep the Feature Store and Hudi metadata consistent with the target files and directories (inodes). Hopsworks is accessible either through a REST API or an intuitive UI (that includes a Feature Catalog), or programmatically through the Hopsworks Feature Store API (HSFS).
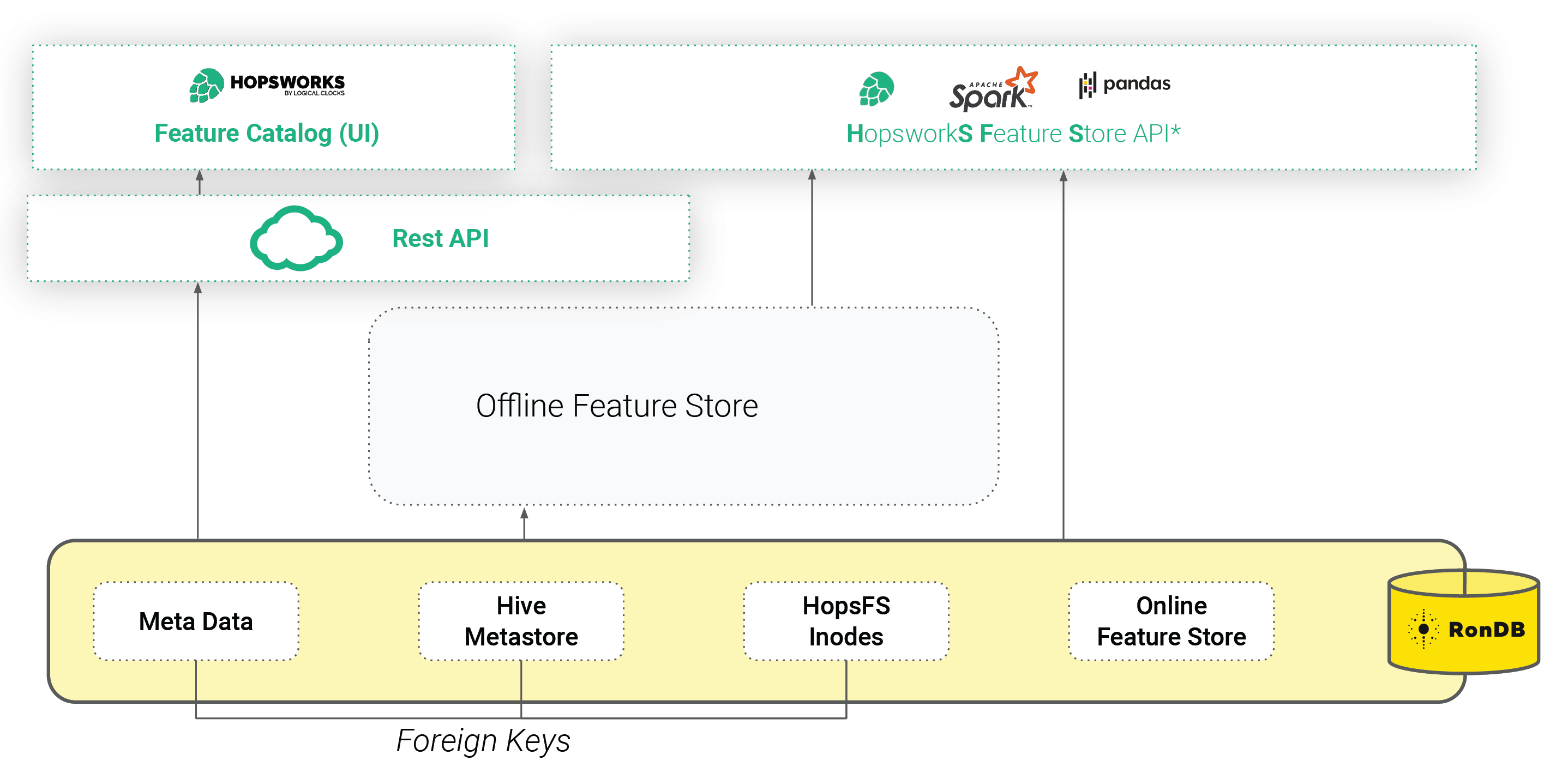
Figure 2. Hopsworks Feature Store API (HSFS)
OnlineFS: The Engine for Scalable Online Feature Materialization
With the underlying RonDB and the needed metadata in place, we were able to build a scale-out, high throughput materialization service to perform the updates, deletes, and writes on the online feature store - we simply named it OnlineFS.
OnlineFS is a stateless service using ClusterJ for direct access to the RonDB data nodes. ClusterJ is implemented as a high performance JNI layer on top of the native C++ NDB API, providing low latency and high throughput. We were able to make OnlineFS stateless due to the availability of the metadata in RonDB, such as avro schemas and feature types. Making the service stateless allows us to scale writes to the online feature store up and down by simply adding or removing instances of the service, thereby increasing or decreasing throughput linearly with the number of instances.
Let’s go through the steps needed to write data to the online feature store, which are numbered in the diagram below.
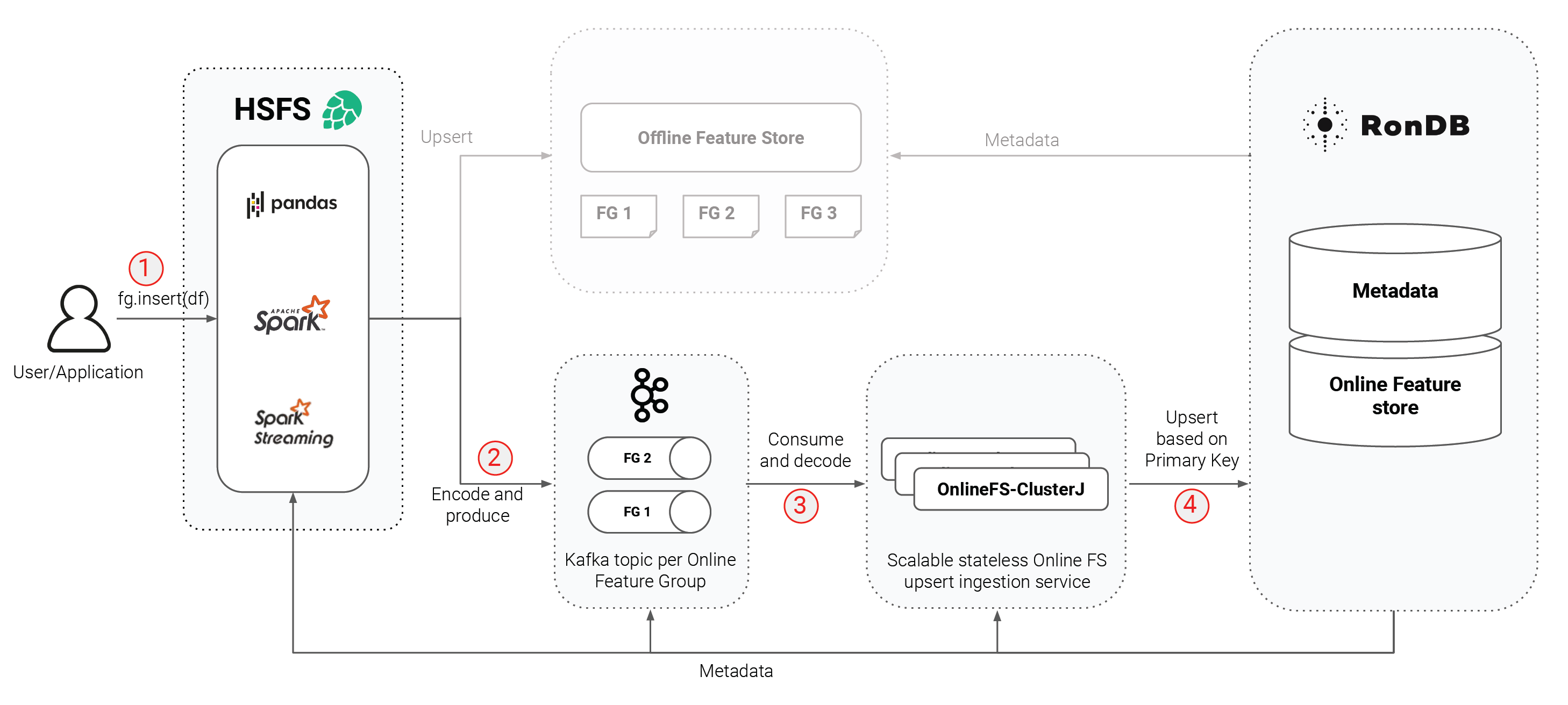
Figure 3. Steps needed to write data to the online feature store,
- Features are written to the feature store as Pandas or Spark Dataframes.
Each Dataframe updates a table called a feature group (there is a similar table in the offline store). The features in a feature group share the same primary key, which can be a composite primary key. Primary keys are tracked along with the rest of the metadata. As such, the Hopsworks Feature Store has a Dataframe API, that means that the result of your feature engineering should be a regular Spark, Spark Structured Streaming or Pandas Dataframe that will be written to the Feature Store. The APIs for writing to the Feature Store are almost identical for all three types of Dataframe. With a reference to the feature group object, you insert the Dataframe. The feature group has been configured on creation to either store the Dataframe to both the online and offline stores or to only one of them.
- Encode and produce
The rows of the Dataframe are encoded using avro and written to Kafka, running on Hopsworks. Each feature group has its own Kafka topic with a configurable number of partitions, and partitioning by primary key, which is necessary to guarantee the ordering of writes.
- Consume and decode
We use Kafka to buffer writes from Spark feature engineering jobs, as a large Spark cluster that writes directly to RonDB could overload RonDB, due to a lack of backpressure in the existing Spark JDBC driver. OnlineFS reads the buffered messages from Kafka and decodes them. Importantly, OnlineFS decodes only primitive feature types, whereas complex features such as embeddings are stored in binary format in the online feature store.
- Primary-key based upsert
Now, OnlineFS can perform the actual upsert of the rows to RonDB using the ClusterJ API. Upserts are performed in batches (with a configurable batch size) to improve throughput.
Since all services in the steps of the pipeline have access to the same metadata, we are able to hide all complexity related to encoding and schemas from the user. Furthermore, all services involved are horizontally scalable (Spark, Kafka, OnlineFS) and due to our streaming-like setup, the process does not create unnecessary copies of the data, that is, there is no write amplification. This highly scalable setup is possible due to the availability of services like a schema registry, a X.509 certificate manager, and Kafka within Hopsworks. At all times, X.509 certificates are used for two-way authentication and TLS is used to encrypt network traffic.
Accessibility means Transparent APIs
In distributed systems, we often speak about transparency. A distributed system is transparent if it hides network access, and implementation specific knowledge from the developer. In the Hopsworks Feature Store, writing is done transparently through the same APIs, as mentioned before (1) no matter if it is a regular Spark, Spark Streaming or Pandas and (2) the system is responsible for updating both online and offline storage consistently.
Insert
The core abstractions in the HSFS library are the metadata objects representing feature groups, training datasets and features in the feature store. Our goal with HSFS was to enable developers to use their favourite languages and frameworks to engineer features. As we aligned on the Dataframe API, anything that is contained in a Dataframe can be written to the feature store. If you have existing ETL or ELT pipelines, which produce a Dataframe containing the features, you can write that Dataframe to the Feature Store by simply acquiring a reference to its feature group object and invoking `.insert()` with your Dataframe as a parameter. This can be called from a regularly scheduled job (using any orchestrator of your choice, alternatively, Hopsworks comes with Airflow, if you want an out-of-the-box orchestrator). But a feature group object can also be updated continuously by writing batches as Dataframes from a Spark structured streaming application.
Get
Many existing Feature Stores do not have a representation for models. Hopsworks, however, introduced the Training Dataset abstraction to represent the set of features and the feature values used to train a model. That is, there is a one-to-one mapping between immutable training datasets and models, but a one-to-many relationship from the mutable feature groups to the immutable training datasets. You create a training dataset by joining, selecting and filtering features from feature groups. The training dataset includes metadata for the features, such as which feature group they came from, the commit-id(s) for that feature group, and the ordering of features in the training dataset. All of this information enables HSFS to recreate training datasets at a later point in time and to transparently construct feature vectors at serving time.
The clients of the online feature store are either applications that use ML models or model-serving infrastructure that enriches feature vectors with missing features. Hopsworks provides a JDBC based API to the online store. JDBC has the advantage of offering a high performance protocol, network encryption, authentication of the client, and access control. HSFS provides language level support for Python and Scala/Java. However, you can always fall back on using JDBC directly if your serving application runs in a different programming language or framework.
Benchmarks
There are sysbench benchmarks for RonDB by Mikael Ronstrom (inventor of NDB Cluster and Head of Data at Hopsworks, leading the RonDB team) and a comparative performance evaluation against Redis available. In this section we show the performance of the OnlineFS service, being able to handle and sustain high throughput in writing to the online feature store, as well as an evaluation of feature vector lookup latency and throughput on a typical managed RonDB setup within Hopsworks.
In this benchmark, Hopsworks is set up with 3xAWS m5.2xlarge (8 vCPU, 32 GB) instances (1 head, 2 worker). The workers are used by Spark for writing Dataframes to the online store. Additionally, the same workers are re-used as clients that perform the read operations on the Online Feature Store for read benchmark.
RonDB is set up with 1x AWS t3.medium (2 vCPU, 4 GB) instance as management node, 2x r5.2xlarge (8 vCPU, 64 GB) instances as data nodes, and 3x AWS c5.2xlarge (8 vCPU, 16 GB) instances for MySQL servers. This setup allows us to store 64GB of data in-memory in the online feature store with 2X replication. The MySQL servers provide the SQL interface to the online feature store, in this benchmark we did not saturate the RonDB data nodes fully, so one could potentially add more MySQL servers and clients to increase throughput beyond the levels shown here.
Write Throughput
We benchmarked the throughput for writing to RonDB in the OnlineFS service. Additionally, we measured the time it takes to process a record from the moment it gets taken from the Kafka topic until it is committed to RonDB. For this benchmark we deployed two OnlineFS services, one on the head node and one on one of the MySQL server nodes.
We ran the experiments by writing 20M rows to the online feature store from a Spark application. After a short warm-up period the throughput of the two service instances stabilizes at ~126K rows/second for 11 features, ~90K rows/second for 51 features and for the largest feature vectors at ~60K rows/second. Due to its design, this can easily be scaled by adding more instances of the service.
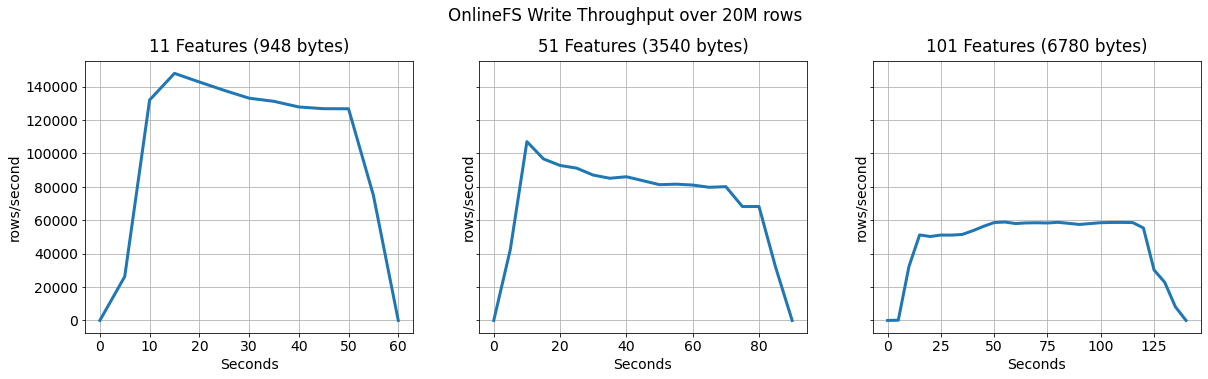
This diagram shows the throughput of writing 20m rows from Kafka to RonDB using two instances of the OnlineFS materialization service.
Secondly, we report the time it takes to process the feature vectors within the OnlineFS service. This time does not include the time a record is waiting for processing in Kafka, the reason for that is that the waiting time depends highly on the number of Spark executors writing to Kafka. Instead, you should rely on the throughput numbers to compare them to your requirements.
The processing times are reported on a per row basis, but parts of the pipeline within OnlineFS are parallelized, for example rows are committed to RonDB in batches of 1000. With this setup we achieve p99 of ~250ms for 11 features with a row size of 948 bytes.
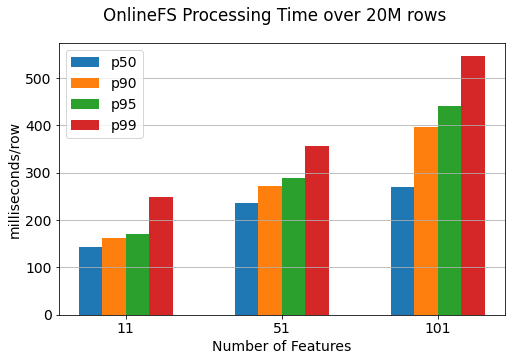
This diagram shows the end-to-end processing latency of events starting from when the event is read from Kafka until it has been written to RonDB. The batch size for this experiment was 1000 - you can reduce latency by reducing the batch size, but reducing the batch size may also reduce throughput.
Serving Lookup Throughput and Latency
We benchmarked throughput and latency for different feature vector sizes in relation to an increasing number of clients performing requests in parallel. Note that the clients were split among the two worker nodes (each 8vCPU).
Single vector per request:
In this benchmark, every request contains one primary key value lookup (one feature vector). Throughput and latency scale linearly up to 16 clients while sustaining low latencies. With more than 16 clients we observed the hosts on which the clients are being run getting to their maximum CPU and network utilization. Furthermore, we did not see an over-utilization of the RonDB data nodes or the MySQL servers, which means we could further scale linearly by running the clients from larger worker instances or adding more worker hosts to run clients from.
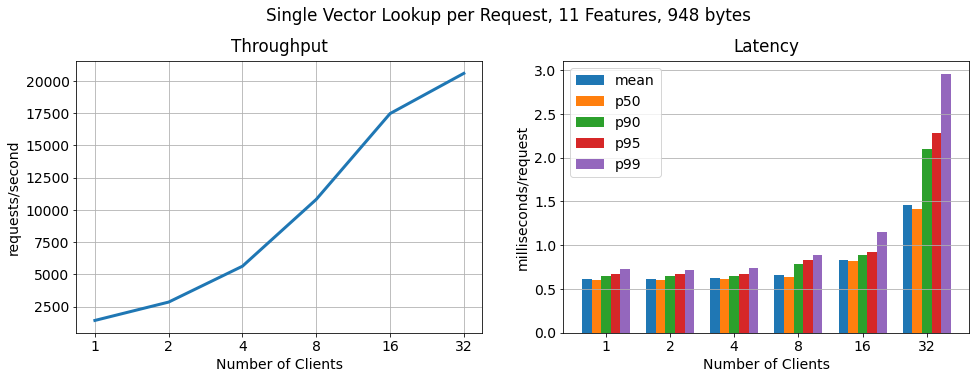
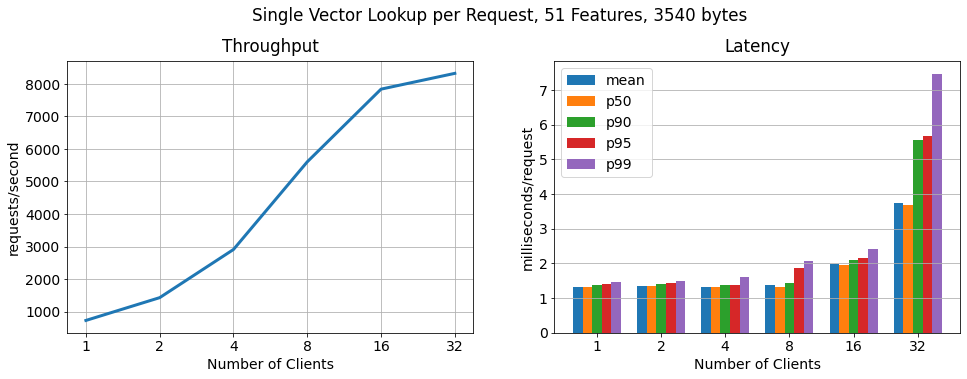
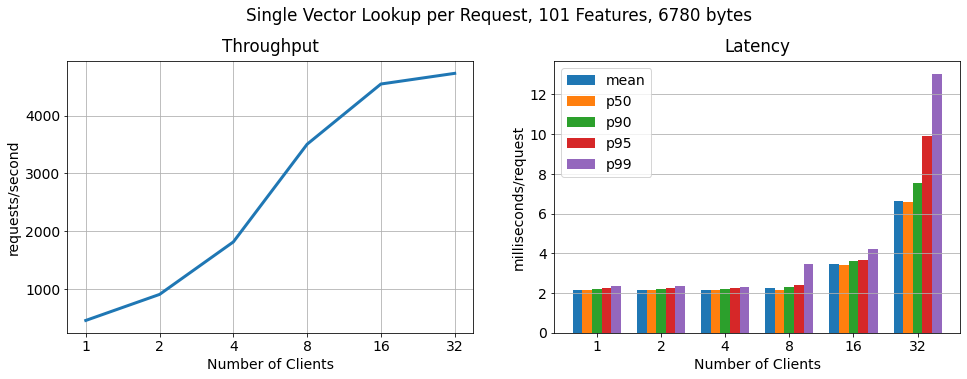
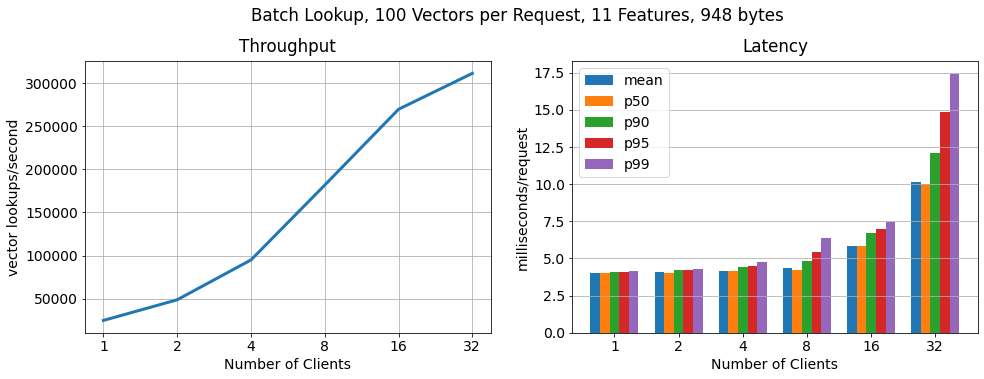
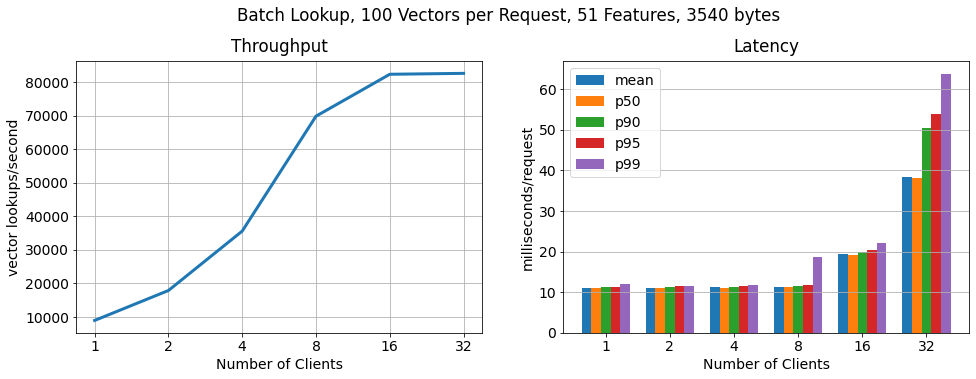
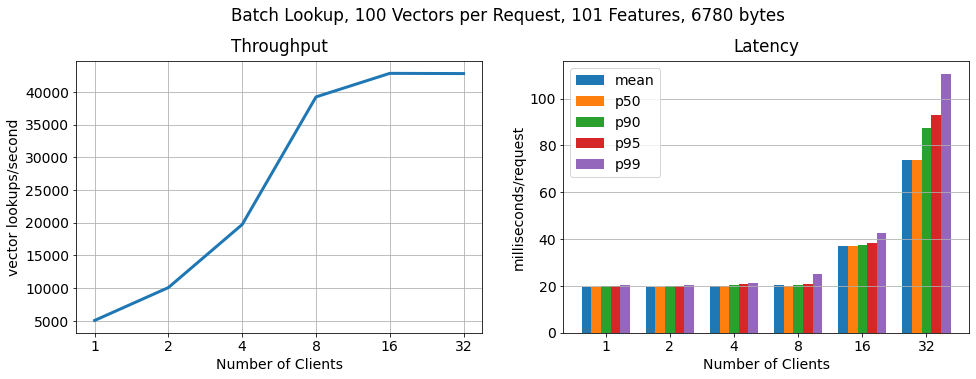
Batch, 100 vectors per request:
In order to show that RonDB scales to many more key lookups per second, we run another benchmark in which each client requests feature vectors in batches of 100. As we can see the number of lookups still scales linearly, lookup throughput increases by 15x, while the latency per request increases only moderately.
Conclusion
Hopsworks comes with managed RonDB that provides a unified metadata store for both Hopsworks and the online feature. In this blog, we showed that a highly available two-node RonDB cluster (r5.2xlarge VMs) scales linearly to >250k ops/sec with feature vector lookups of 11 features of ~1KB in size and 7.5 ms p99 latency. Thus, Hopsworks provides the highest performance online feature store on the market today.