A Spark Join Operator for Point-in-Time Correct Joins
In this blog post we showcase the results of a study that examined point-in-time join optimization using Apache Spark in Hopsworks.

Introduction
When constructing datasets to use for machine learning models, data scientists sometimes need to look at historical data to obtain previously occurring scenarios. By looking at the previously occurring scenarios, the model is able to find correlations between the different features of the observed entity or entities. A feature is a measurable attribute of an entity whose behavior our model is trying to predict. When constructing our desired dataset, we need to construct the feature values of an entity at a specific point in time. Although, as the feature values may reside in different datasets, updated at different frequencies, it is not always possible to utilize an exact time-based join to obtain the desired result.
Point-in-time correct joins
The illustration that can be observed in Figure 1. displays how point-in-time correctness can be achieved. The hexagons in the illustration represent feature update and target prediction events. The prediction targets (marked in dark red) specify a point in time where we want to extract the most recent feature values for some entity. It is important to not leak information from the future (light red / pink events) into the training dataset, since it will produce scenarios that never actually occurred. The only events we want to consider are the green events, as these are the most recent feature values at the time of the red event.
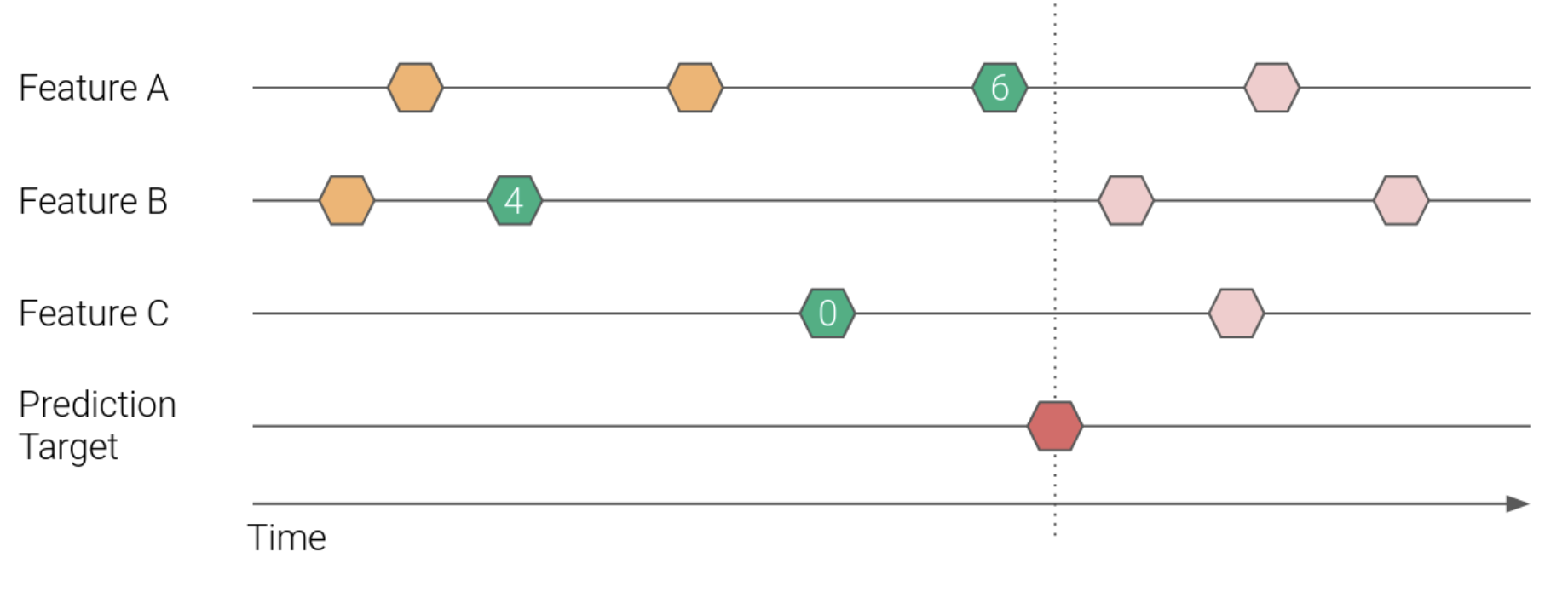
Figure 1. Example of a point-in-time correct cutoff
Commonly when working with data pre-processing of machine learning, our data is structured using a tabular fashion. When working with tabular structured data, the most common way of merging two or more tables is with the use of join operations. To obtain these point-in-time correct training datasets is achieved by executing a join operation called the point-in-time join, or PIT join for short.
If we consider the illustration seen in Figure 2., where we want to execute a PIT join to merge the left (orange) dataset, which consists of average delivery times, with the right (green) dataset, consisting of review scores. What we want to do is to merge the events from the left dataset with the event of the right dataset whose event time is less than or equal to the considered left event. In this scenario, we also want to consider the seller_id to only match rows that reference the same entity.
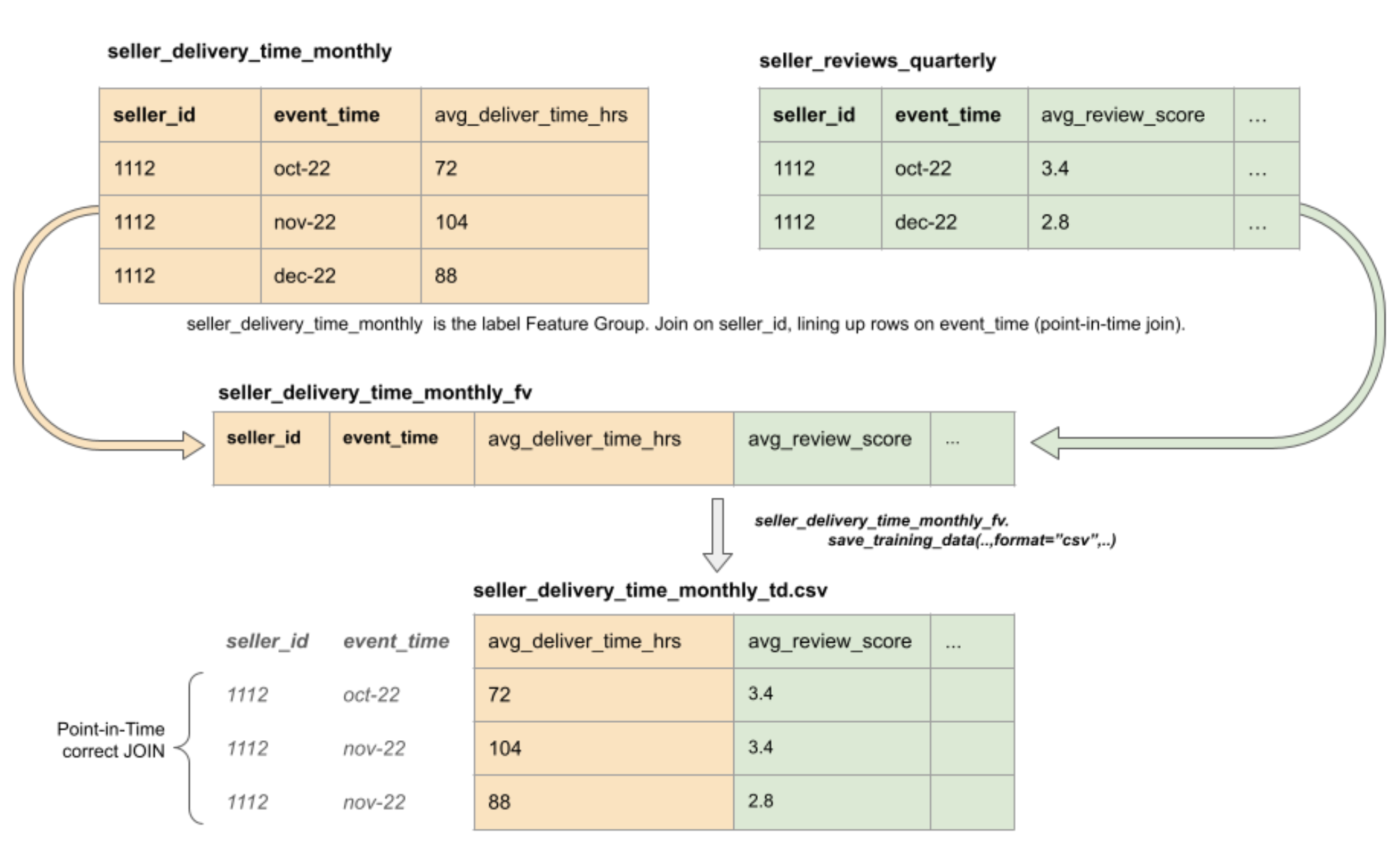
Figure 2. Point-in-time correct join to create training data as CSV files from a FeatureView.
Point-in-time joins in Apache Spark
A popular framework for the data pre-processing step of machine learning has long been the analytics engine Apache Spark. Because of its flexibility, scalability, as well as performance, it is seen as a good alternative when working with large amounts of data. Internally, Spark uses resilient distributed datasets (RDDs) to process data that is distributed over a network of nodes. However, when working with structured data, a more common abstraction used is the Dataset / DataFrame API, which is part of the Spark SQL module. Spark SQL enables the processing of data with the use of SQL-like commands that many are familiar with.
There have been multiple implementations of the PIT join in Apache Spark, notably seen in the Databricks Tempo, which uses a union-based approach, as well as TwoSigma’s Flint, which implements custom RDD functionality. The Flint library is however not available in Spark SQL and could be hard to integrate in modern Spark projects.
Optimizing point-in-time correct joins in Spark
By investigating the previously mentioned implementations, as well as investigating other possible solutions in other frameworks, the utility library spark-pit was created. This utility library implemented three different methods to achieve PIT joins in Spark SQL:
-
Union PIT join (Filtered sorted union approach)
-
Inspired by the Tempo project
-
Exploding PIT join (Filtered partitioned join approach)
-
Creates an intermediate “exploded” table, consisting of all pairs of rows fulfilling the predicate left.ts >= right.ts
-
Finds the correct pair by partitioning and sorting the intermediate table
-
Early Stop Sort-Merge
-
Modified Sort-Merge
-
Sort in descending order on event time
-
Merge rows immediately when first match is found
As the Flint approach could not be a hundred percent replicated in the environment of Spark SQL, the Early Stop Sort-Merge join was created, it is a modified version of the low-level Sort-Merge implementation, native to Spark.
Benchmarks - Synthetic data
To understand the performance of these algorithms, synthetic data was created and used for benchmarking. We wanted to have data that could be pretty close to reality, so we decided to simulate event based data that could be used for the creation of machine learning training datasets. A set of unique IDs were generated and the left dataset would consist of one row per ID, representing a target event, and the right dataset would have multiple rows per ID, representing feature events.
Using this generation strategy, different variations were generated. We used datasets between ten thousand and ten million unique IDs, increasing logarithmically. Furthermore, different sorting structures, cluster sizes, and the effect of bucketed data was also investigated. The script for running the experiments can be observed in the following gists.
The results presented in Figures 3. and 4. shows the elapsed time and the memory consumption when processing the ascending ordered dataset. Here, the Early Stop-Sort Merge implementation performed better in terms of speed, and scaled the best in terms of memory consumption; although an increased overhead when working with the smaller datasets was observed. For the largest dataset, the Early Stop Sort-Merge achieved a speedup of about 1.45X compared to the Exploding, and 2.5X speedup compared to the Union implementation. Similar results were observed for the descending ordered dataset. While for the random order, all algorithms performed worse, with the Exploding algorithm achieving the best results, which can be observed in Figure 5.
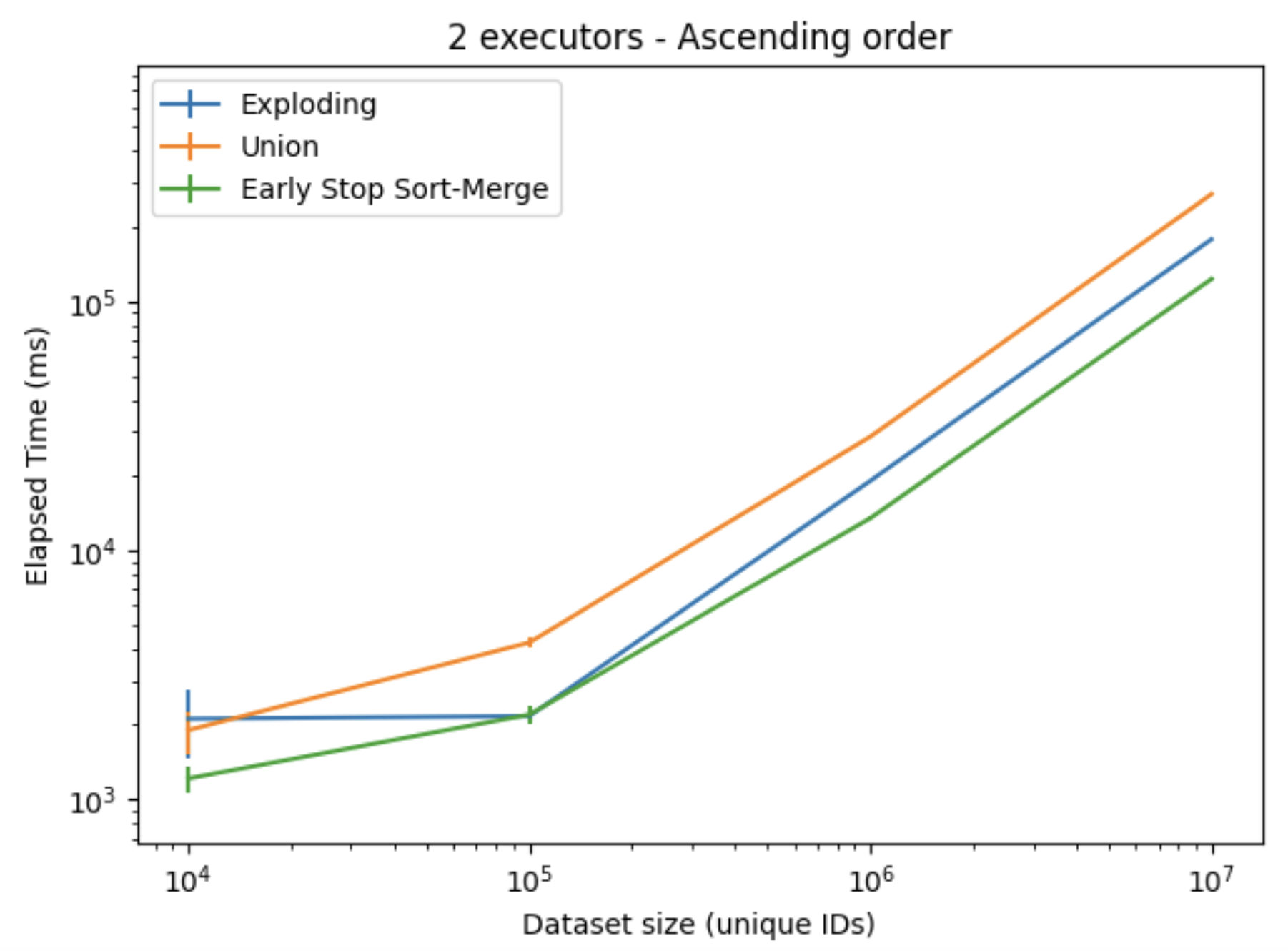
Figure 3. Elapsed time when using ascending order dataset, using two executors on one node.
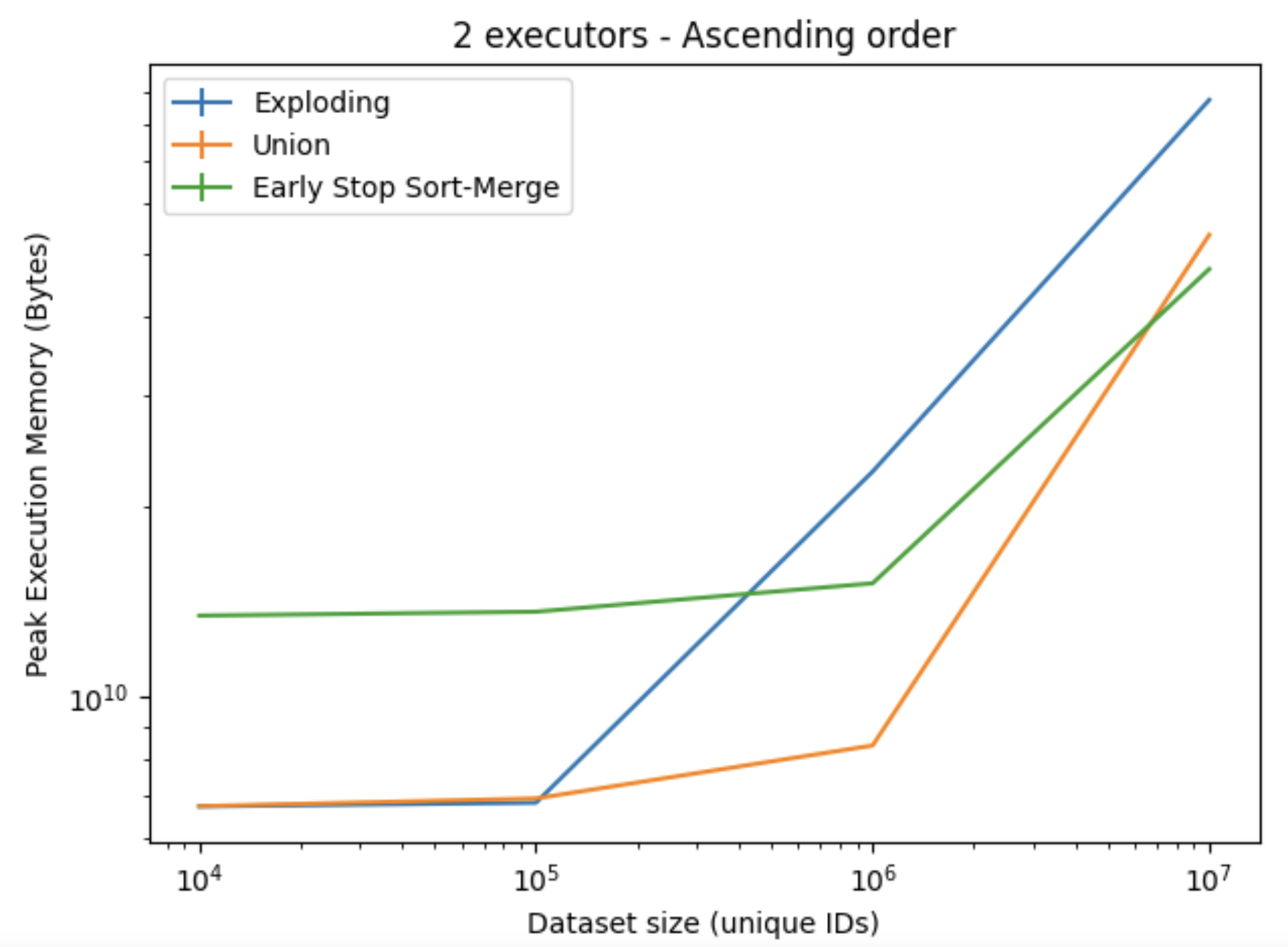
Figure 4. Peak memory execution when using ascending order dataset, using two executors on one node.
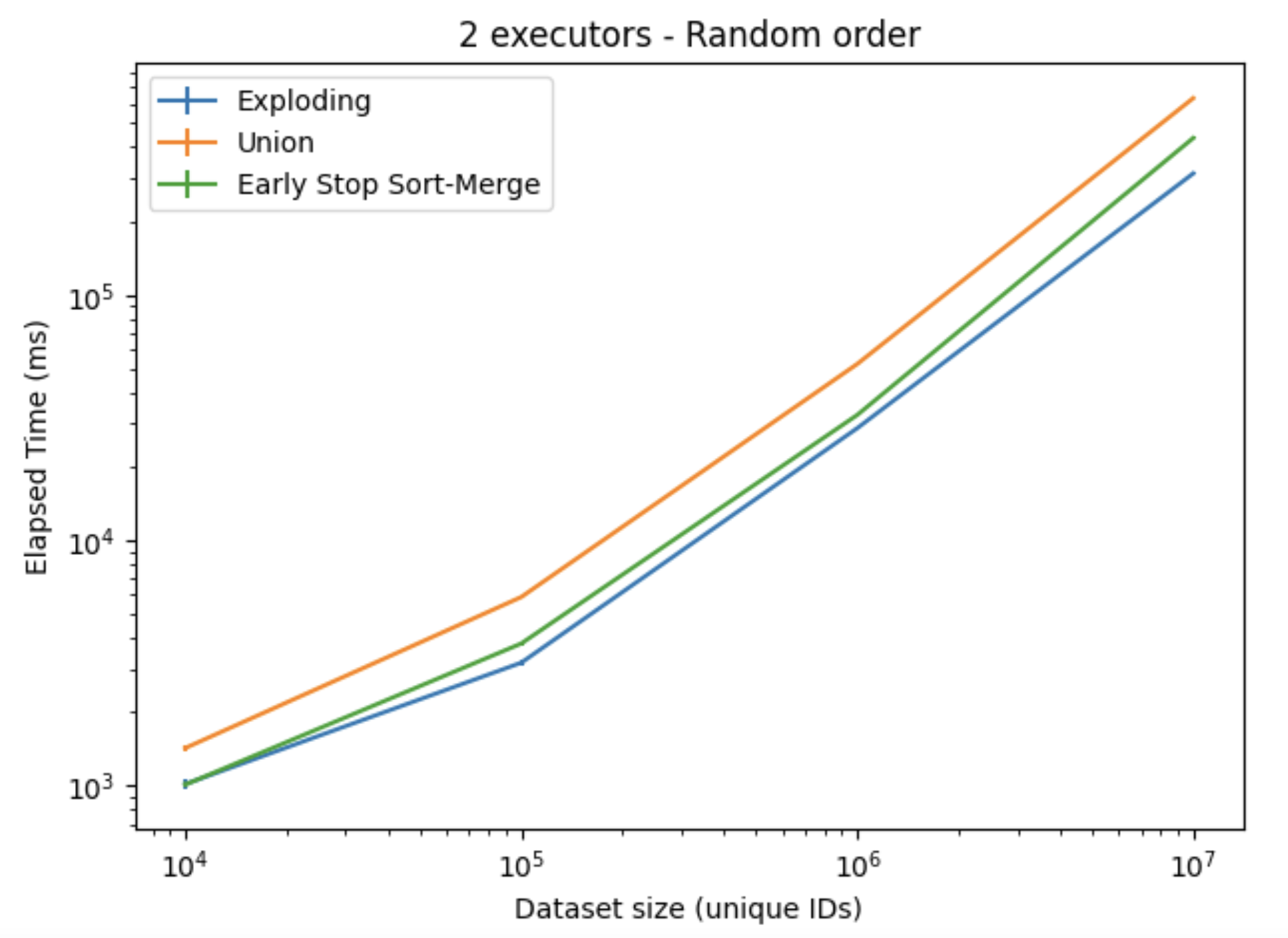
Figure 5. Elapsed time when using ascending order dataset, using two executors on one node.
The results from executing the bucketing showed promising results for the Exploding and Early Stop Sort-Merge algorithms, as a significant decrease in time when working with large datasets could be achieved using the datasets with one million and ten million unique IDs, which can be observed in Figures 6. and 7., respectively. However, a low number of buckets could decrease the performance of the algorithms if it meant the increase of disk spillage. The Union algorithm did not get affected positively by the bucketed data, as a union operation does not distribute the workload. However, the time it took to read the bucketed data into memory took longer when the buckets started to grow, explaining the increase in elapsed time.
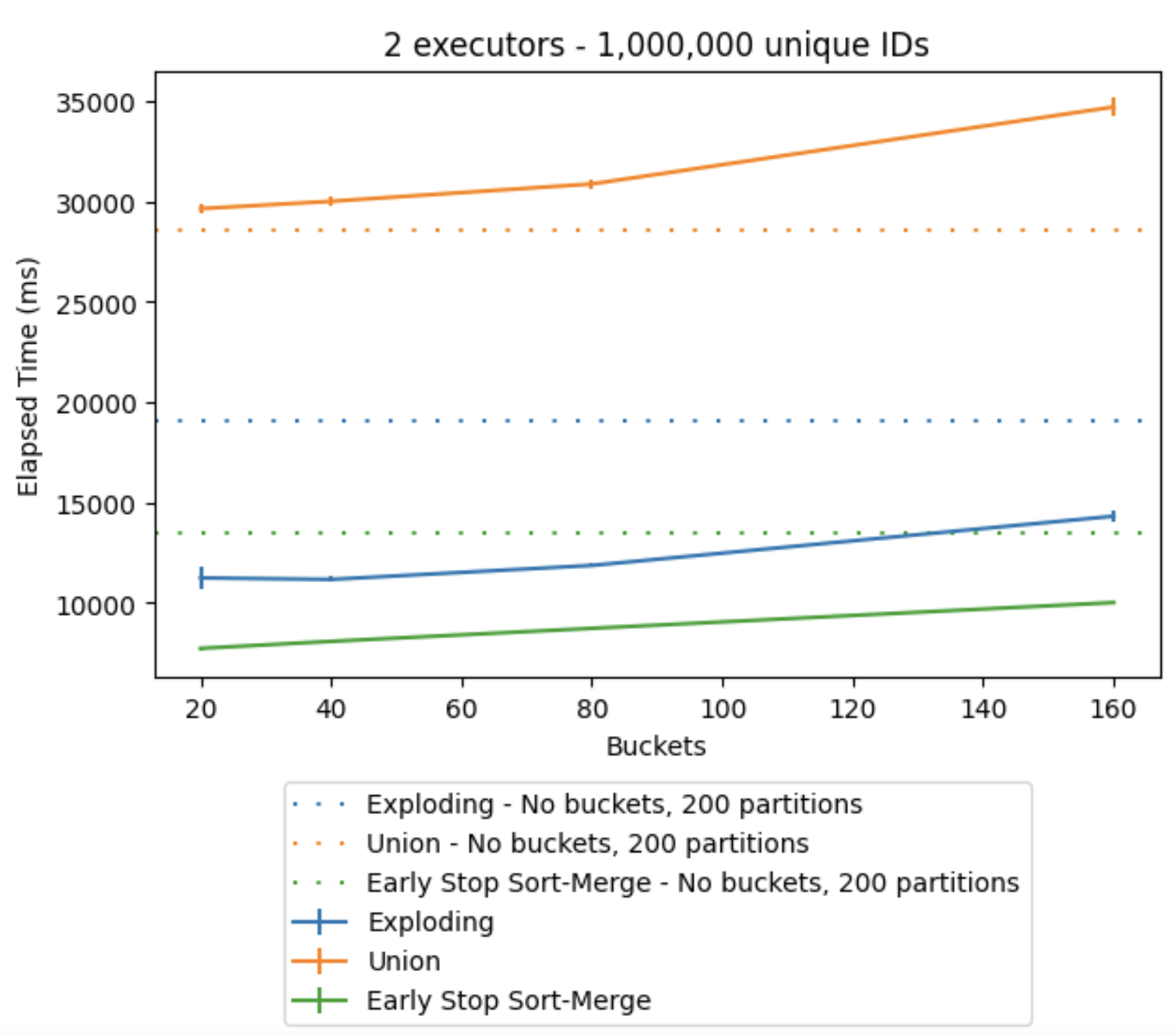
Figure 6. Elapsed time when the number of buckets grows, one million unique IDs, using two executors on one node.
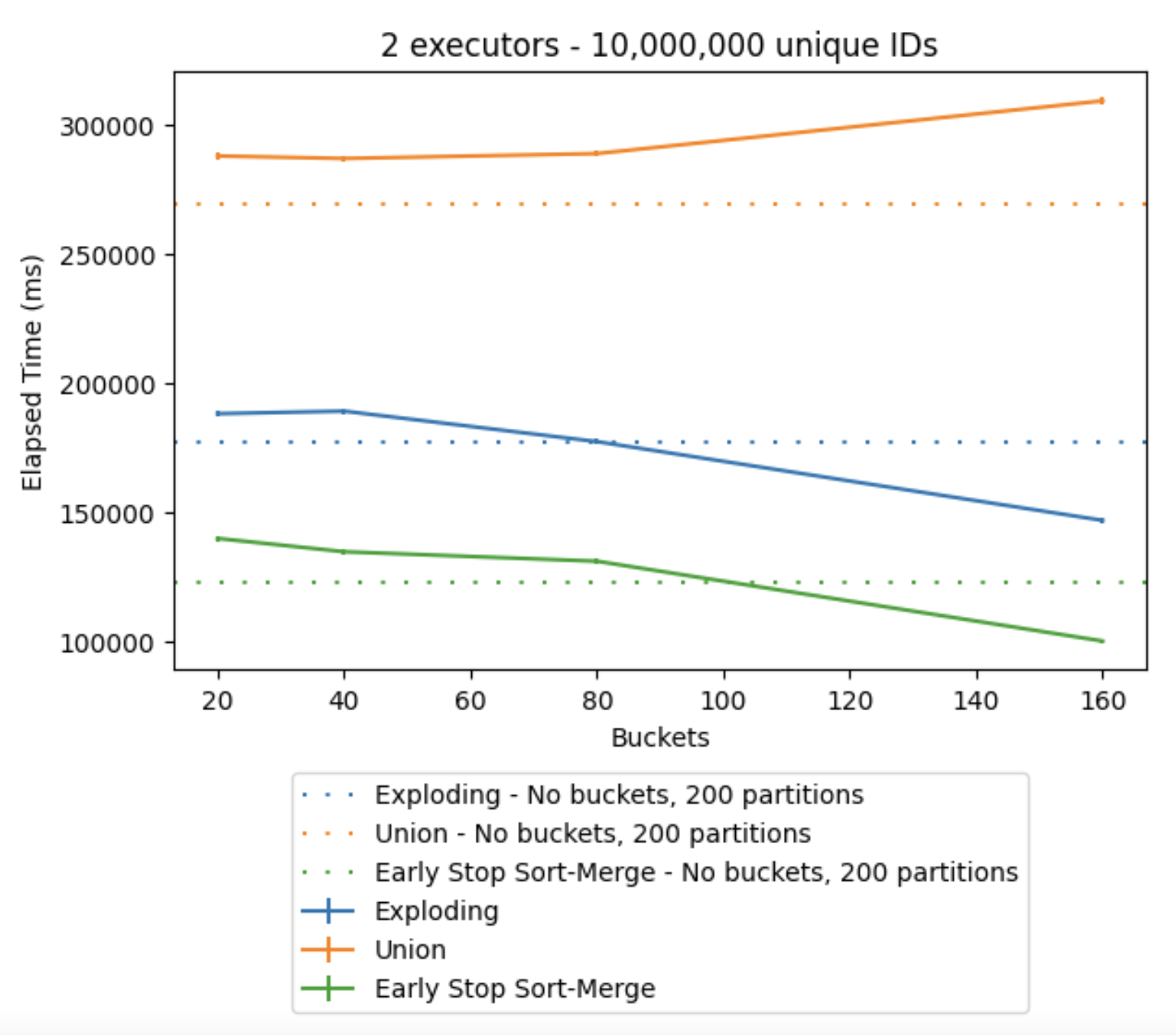
Figure 7. Elapsed time when the number of buckets grows, ten million unique IDs, using two executors on one node.
As the number of nodes increased, all of the algorithms performed better in a similar manner, which can be observed in Figure 8. This shows that all of these algorithms can scale pretty well as the Spark cluster increases in size.
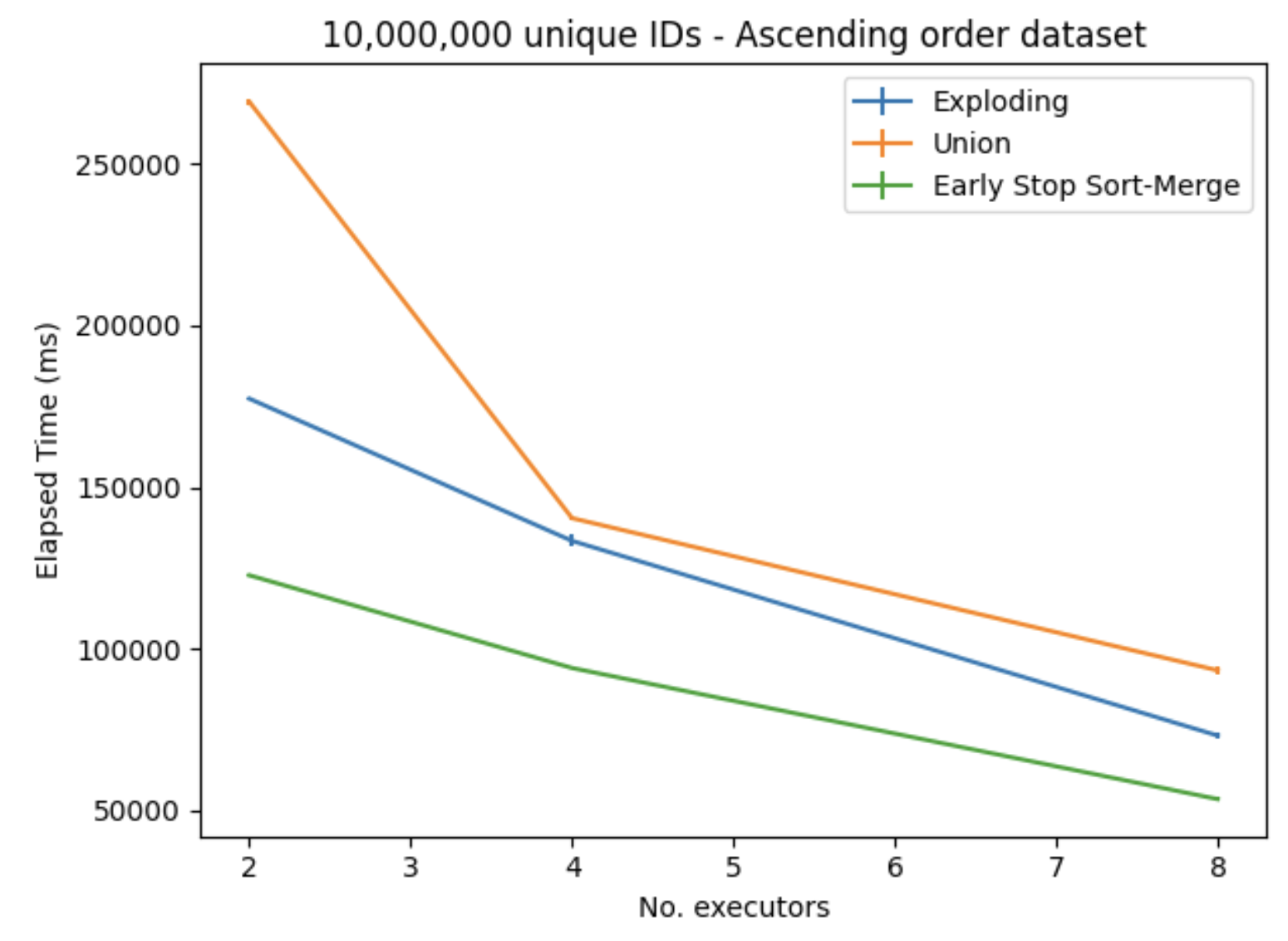
Figure 8. Elapsed time when the number of executors increases, ten million unique IDs.
Benchmarks - Yelp dataset
Since we wanted some additional metrics on the effects using other datasets, we also decided to use a publicly available dataset distributed by Yelp. Using the Yelp dataset, we created a point-in-time join using the user tips as target events and check-ins as feature update events. The pre-processing of these datasets includes transforming the date column to timestamps and exploding the check-in table, which can be observed in the following gist. Furthermore, the script for running the experiments can be found in this gists.
The elapsed time to execute this operation using the different implementations can be observed in Figure 9. Here, the Early Stop Sort-Merge showed similar performance as before, while the Exploding algorithm showed a very large decrease in performance. In comparison to the other algorithms, Early Stop Sort-Merge achieved a speedup of about 17.54X compared to the Exploding algorithm, and 1.23X compared to the union algorithm.
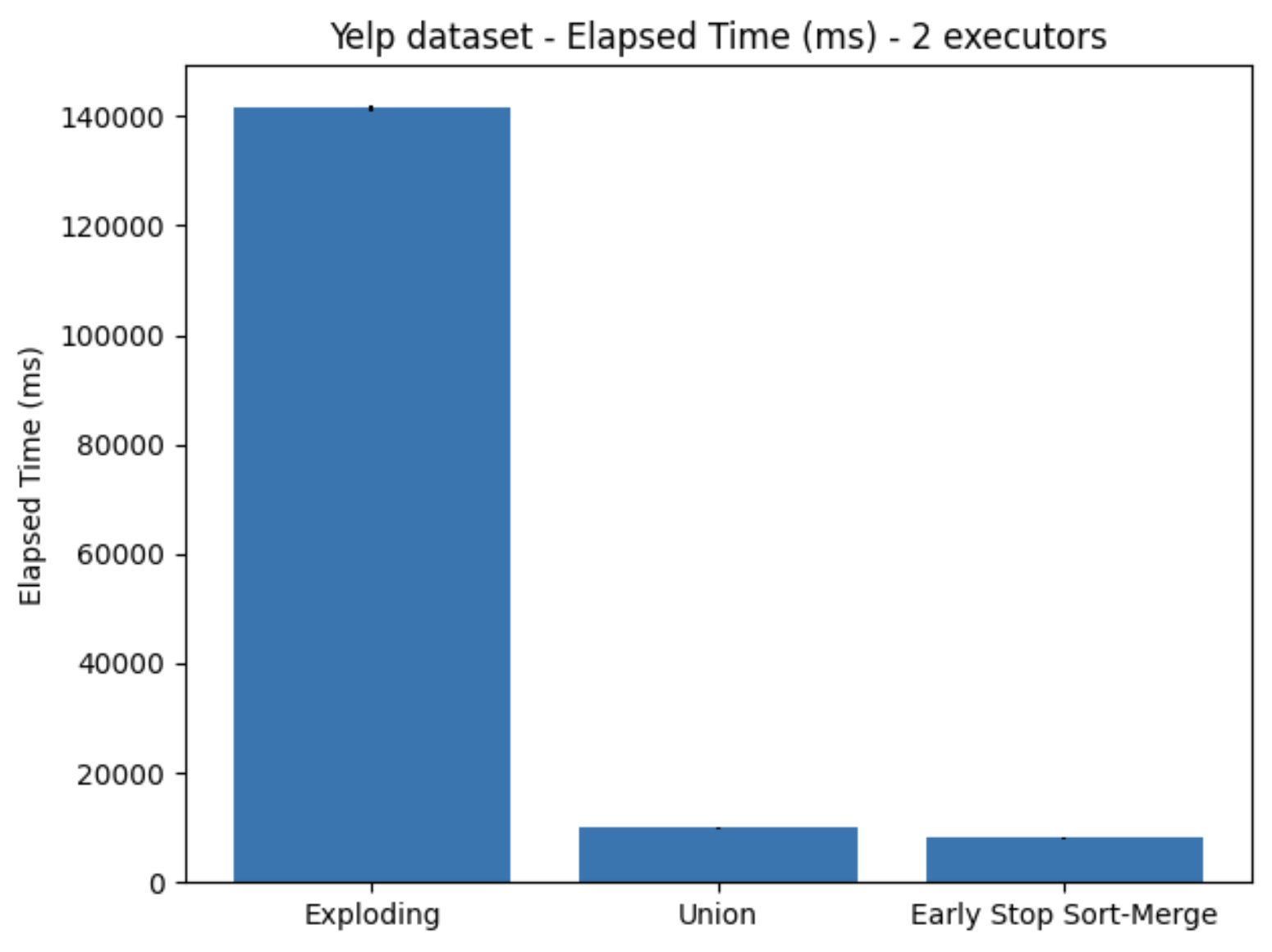
Figure 9. Elapsed time using Yelp dataset, utilizing two executors on one node
Further investigation showed that because of the initial joining operation in the Exploding algorithm, it created an extremely large intermediate table, which the executors were not able to keep in memory. Resulting in large amounts of memory and disk spillage, which can be observed in Figures 10. and 11., respectively.
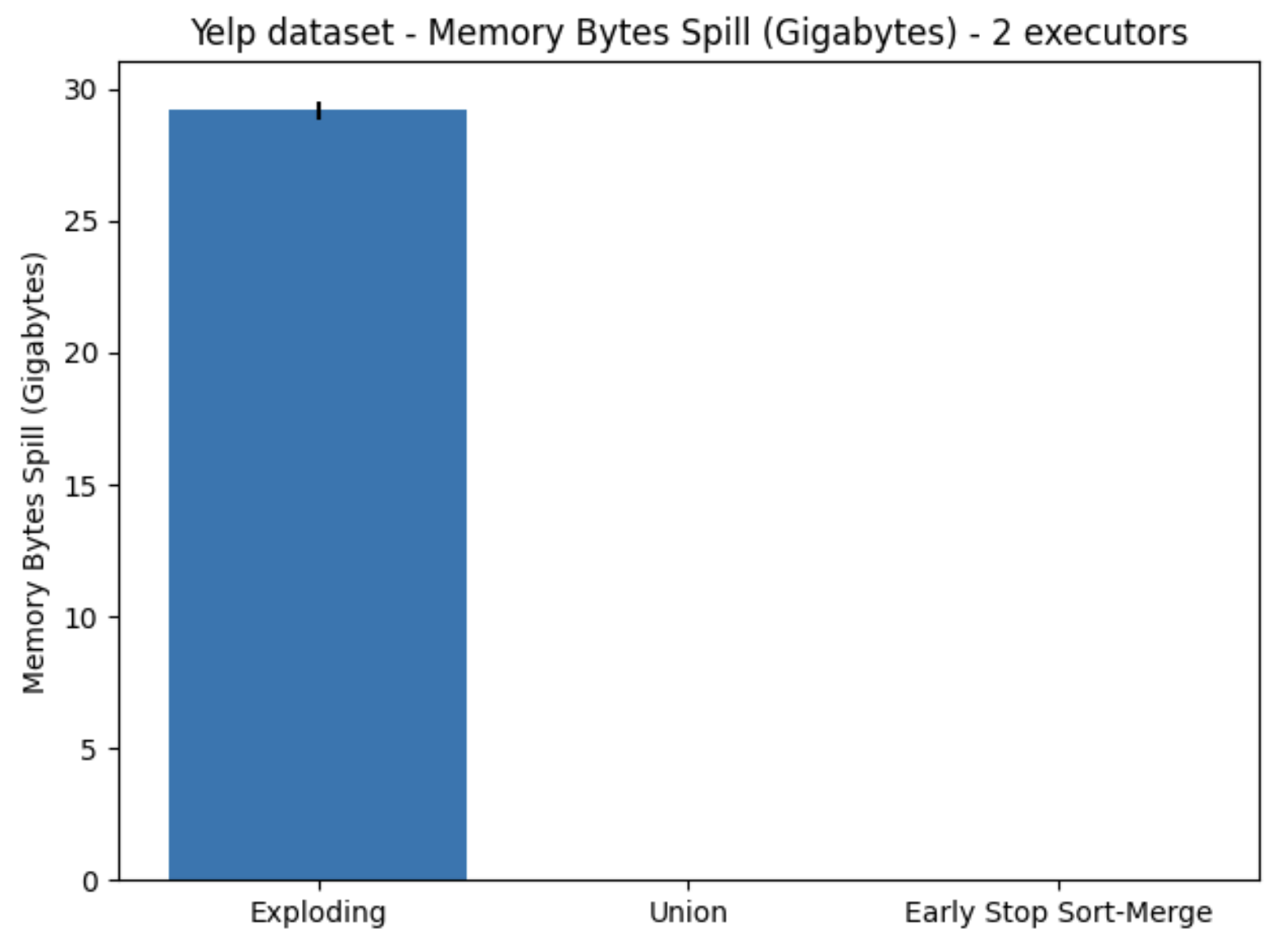
Figure 10. Memory bytes spilled using Yelp dataset, utilizing two executors on one node
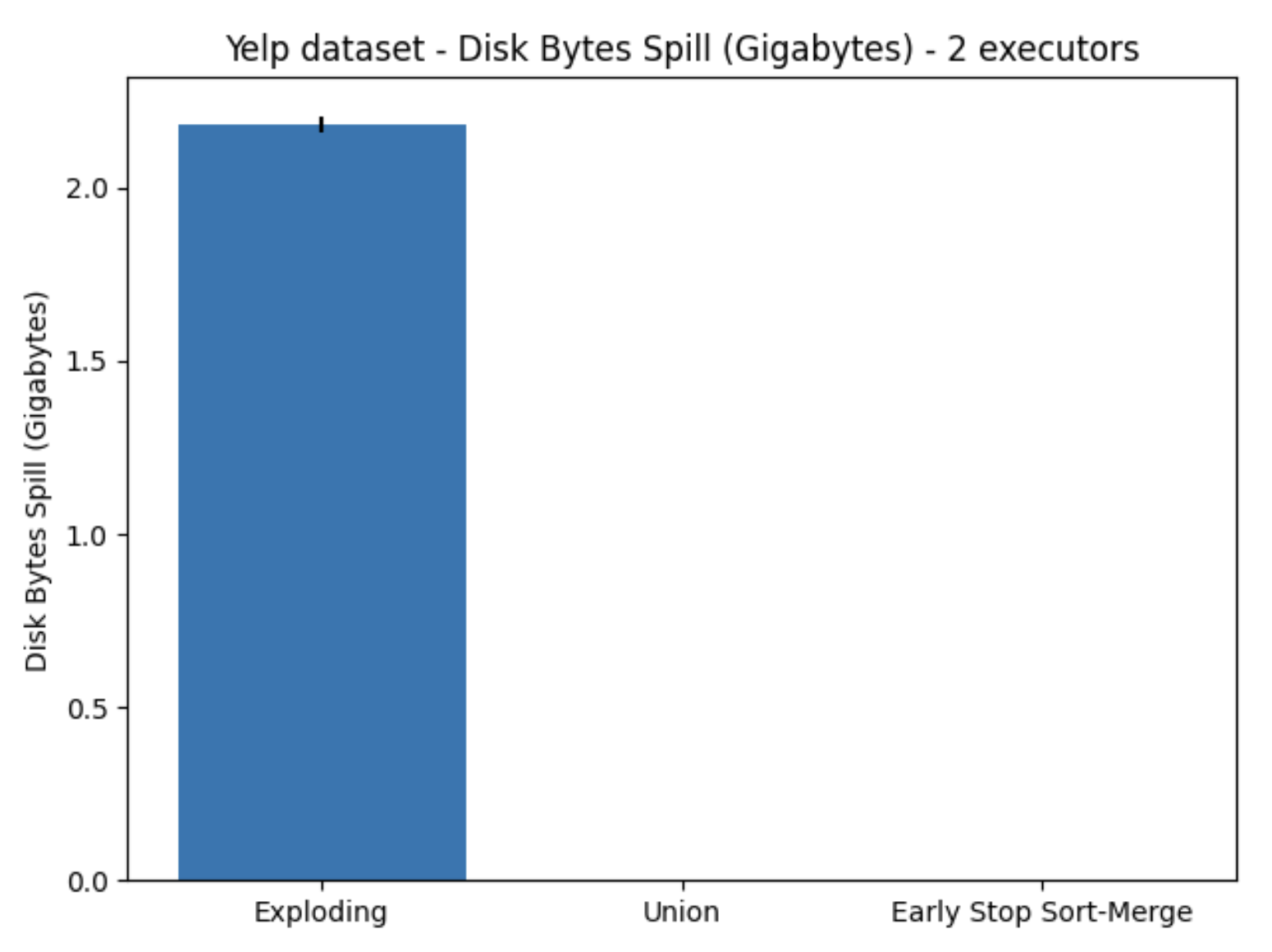
Figure 11. Disk bytes spilled using Yelp dataset, utilizing two executors on one node
Hopsworks and point-in-time joins
The results show that of the investigated algorithms that can be used for executing point-in-time joins, the Early Stop Sort-Merge implementation shows the most potential. The performance of the Exploding algorithm showed that, depending on the structure of the data, can provide either really good or really bad results. As with the union algorithm, it showed pretty consistent results, but fell pretty short in comparison to Early Stop Sort-Merge, which performed much better under large data-load.
For Hopsworks to be able to provide the best performing PIT joins available, a decision to switch over to using the Early Stop Sort-Merge implementation has been made. This will provide more consistent performance and memory consumption when constructing machine learning training datasets.