Why Do You Need a Feature Store?
Discover the power of feature stores in modern machine learning systems and how they bridge the gap between model development and production.

Future-Proofing ML Operations: The Case for Feature Stores
When an organization needs to productionize machine learning models, built using data from their data platforms, they often require a feature store as a central repository and collaboration layer for the data teams. But feature stores are more than just a data warehouse for features. They also power online AI applications, providing the key operational machine learning infrastructure that feeds data to online models.
In this article we will explain why the feature stores are now widely considered as the backbone of modern machine learning systems and we will identify the various challenges to consider when you start thinking about implementing one in your organization.
First, a short history on the origins of and need for feature stores. The first feature store was announced in late 2017 as a platform developed internally by Uber. Uber had difficulties in scaling and operationalising models for machine learning; engineering teams were building bespoke, often one-off systems that would enable each model to be put in production. Those early ML Systems produced numerous anti-patterns and a range of technical debts that organizations would incur over time. Simply put, there is a gap between the systems needed to develop a model and the systems needed to operationalise a model that valuable business systems will depend on.
1- Identifying the Need for a Feature Store
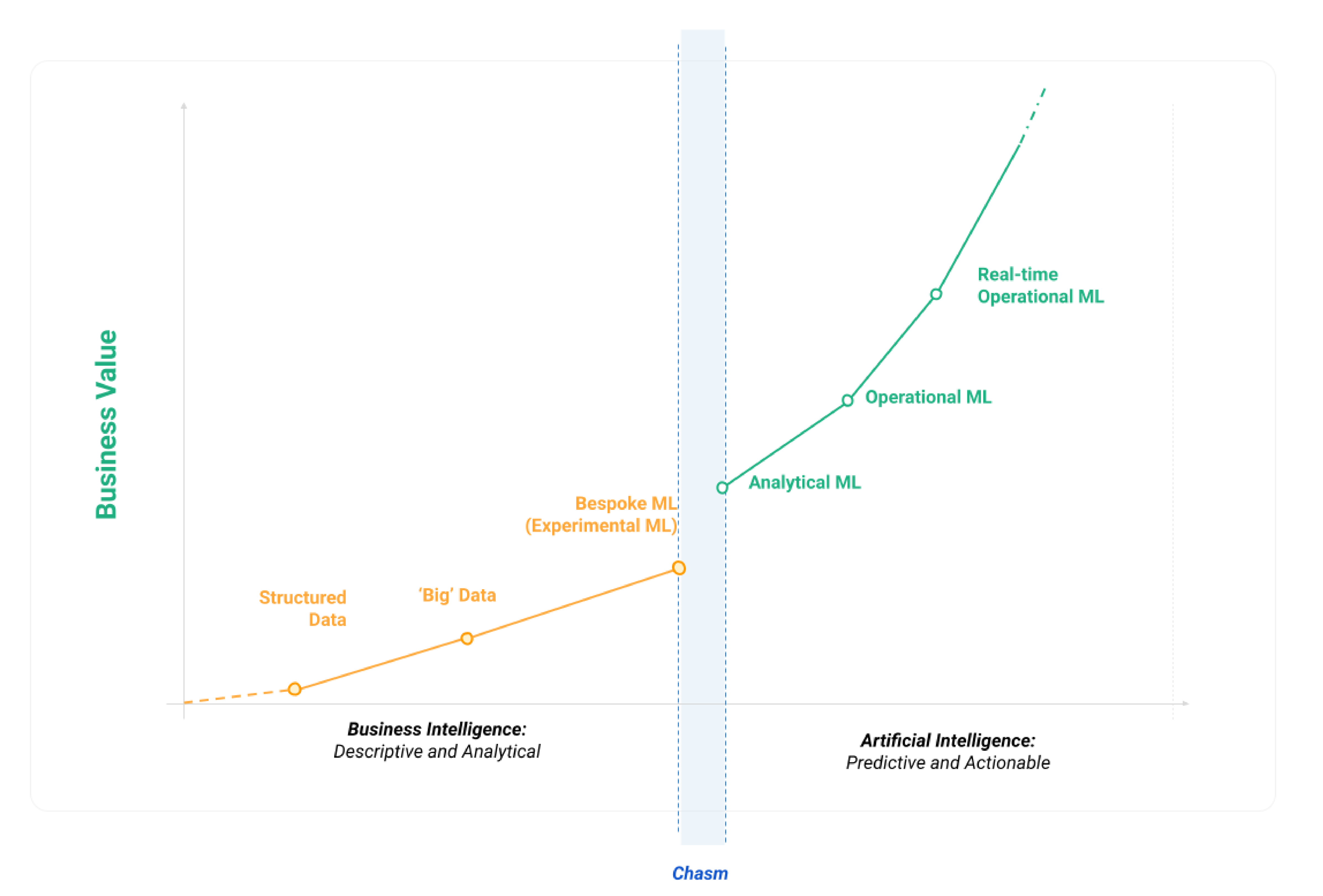
Figure 1. The chasm between BI and AI
As companies mature enough to understand their business historically with Business intelligence tools and data, they often look to AI to build intelligent applications or services. Business intelligence looks at the current and past data to help build meaningful insights and advice on the current situation of the business and potential actions that can be undertaken. Machine learning is the logical next step; it helps build products and meaningful predictions; it is a look into the future.
Companies are increasingly focussing on getting AI in operation as quickly as possible and using feature stores and ML platforms to accelerate that journey is the appropriate approach, chosen by industry leading companies such as robinhood, stripe, doordash and more.
Here are a few considerations that can help you identify if and when your organization has reached the threshold towards operational ML and might start the implementation of a feature store and ML platforms;
- Valuable models are created but once the experimentation stage is over they do not bridge the chasm to operations - the models do not consistently generate revenue or savings.
- Existing models running in production are expensive - they are hard to debug, review and upgrade, they are bespoke systems that are difficult and costly to maintain.
- Monitoring production pipelines is challenging, or impossible. The data that powers AI changes over time, and identifying when there are significant changes that require retraining your AI is not easy.
- Feature data is not centrally managed; it is duplicated, features are re-engineered, and generally data is not reused across the organization.
- Inability to provide very fresh feature data or handle real-time data for ML models, which is critical for industries like finance, retail, or logistics where real-time insights can add significant business value.
- Difficulties in managing the lifecycle of feature data, including the tracking of versions and historical changes.
- No cohesive governance in the storage and use of AI assets (feature data and models), everything is done in a bespoke manner, leading to compliance risks.
- Hard to derive a direct business value from the models, they exist in isolated environments that do not directly influence business operations.
- Slow ramp-up time when onboarding new talent into the ML teams. Sharing available AI assets is complex because operational knowledge is held by a few individuals or groups.
In addition to solving those issues, in general, the implementation of a feature store will enforce best-practices in managing AI assets, and helps eliminate silos in organizations where different business units or teams are responsible for a portion of the process. As a collaborative platform, the feature store empowers each team as part of a cohesive process for productionizing AI and it reduces friction in establishing collaboration across teams.
There is also a strong argument that the feature store is not just a tool for big corporations, but for any organization that wants to build an AI-enabled system or application. Feature stores remove the need to build the operational AI support, reducing headcount and operational costs for small teams, enabling them to focus on the more valuable work of building the ML pipelines and AI-enabled applications or systems.
2- Feature Stores in a Nutshell
A feature store is a central, governed platform that enables data to be discovered for training AI and it also enables operational systems to use data to make predictions (inference) with AI. The feature store provides a Data Catalog describing the available data (the features) along with metadata, used for discovery but also to define the constraints under which data may be used in AI models to ensure compliance. The feature store also needs to provide security and SLAs (service level agreements) to ensure data is highly available for use by models in operational systems, ensuring critical business systems do not suffer downtime.
Where does the feature data, stored in feature stores and used by AI for training and predictions, come from? Typically, feature data is created using data from existing Enterprise Data Sources (databases, data warehouses, data lakes, lakehouses, message queues). Ultimately, this data is generated by business products and services (financial results, customer behaviors, click events…), and the predictions made by AI are used by those same products and services.
The feature data, itself, is often slightly different from the data in your existing Enterprise data platforms. Feature data is often concentrated signals from existing data (e.g., feature data might be the moving point averages for a stock every 1 minute, rather than all individual stock prices that change many times per second), it can also include things like customer demographics, product prices, or website traffic data. Feature data may be computed at regular intervals (hourly, daily, etc) or it might be real-time data (the current Nasdaq Composite Index price ). The variety and the varying cadences for different feature data create complexities in computing, storing, and making that feature data available to operational models.
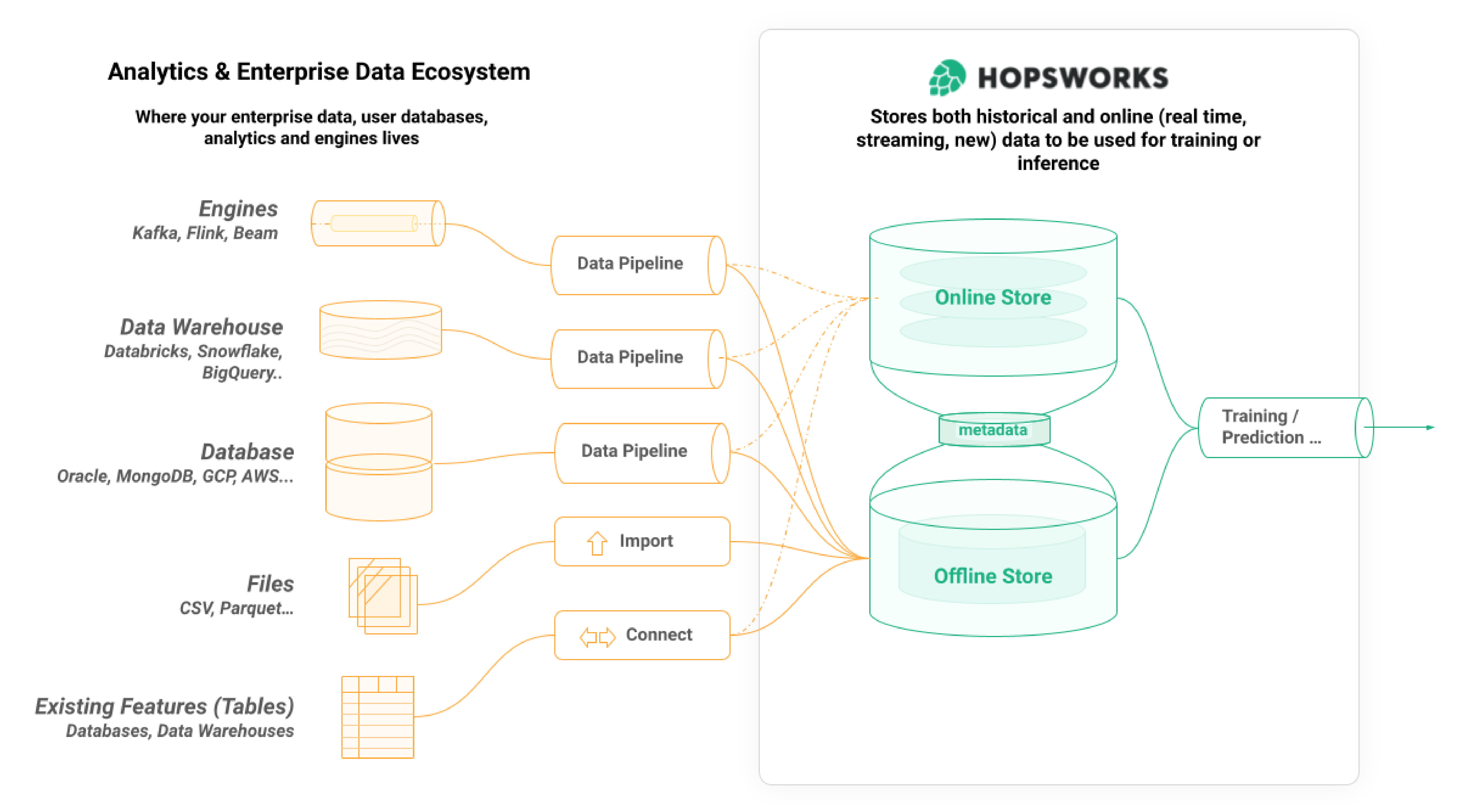
Figure 2. Feature Stores in a nutshell
Delving into the technical specifics, a feature store is a unified platform that consists of three internal data systems:
- an offline store for large volumes of historical feature data used for training and for batch predictions,
- an online store for feature data that is read at low latency by online (interactive) AI applications;
- and a metadata layer that stores information about the feature store itself, and metadata about the feature data, users, computations, and so on.
Feature stores solve two major problems in operational machine learning; how to deliver the right feature data in the right format for training or prediction, and how to compute and manage feature data from disparate and disjointed sources.
Since their inception, feature stores have widely extended their capabilities and are the foundation of most operational machine learning platforms in companies that provide operational AI services. Feature stores now support collaboration across data and operations teams, data re-use, versioning features and models, governance, monitoring, and more.
3- Roadmap to implement a feature store: MVP
After you have identified the need for faster implementation of your models, you need to set up a framework. As a result of helping and collaborating with hundreds of professionals in Fortune 500 companies, we have identified the most efficient model: create an end-to-end minimum viable product.
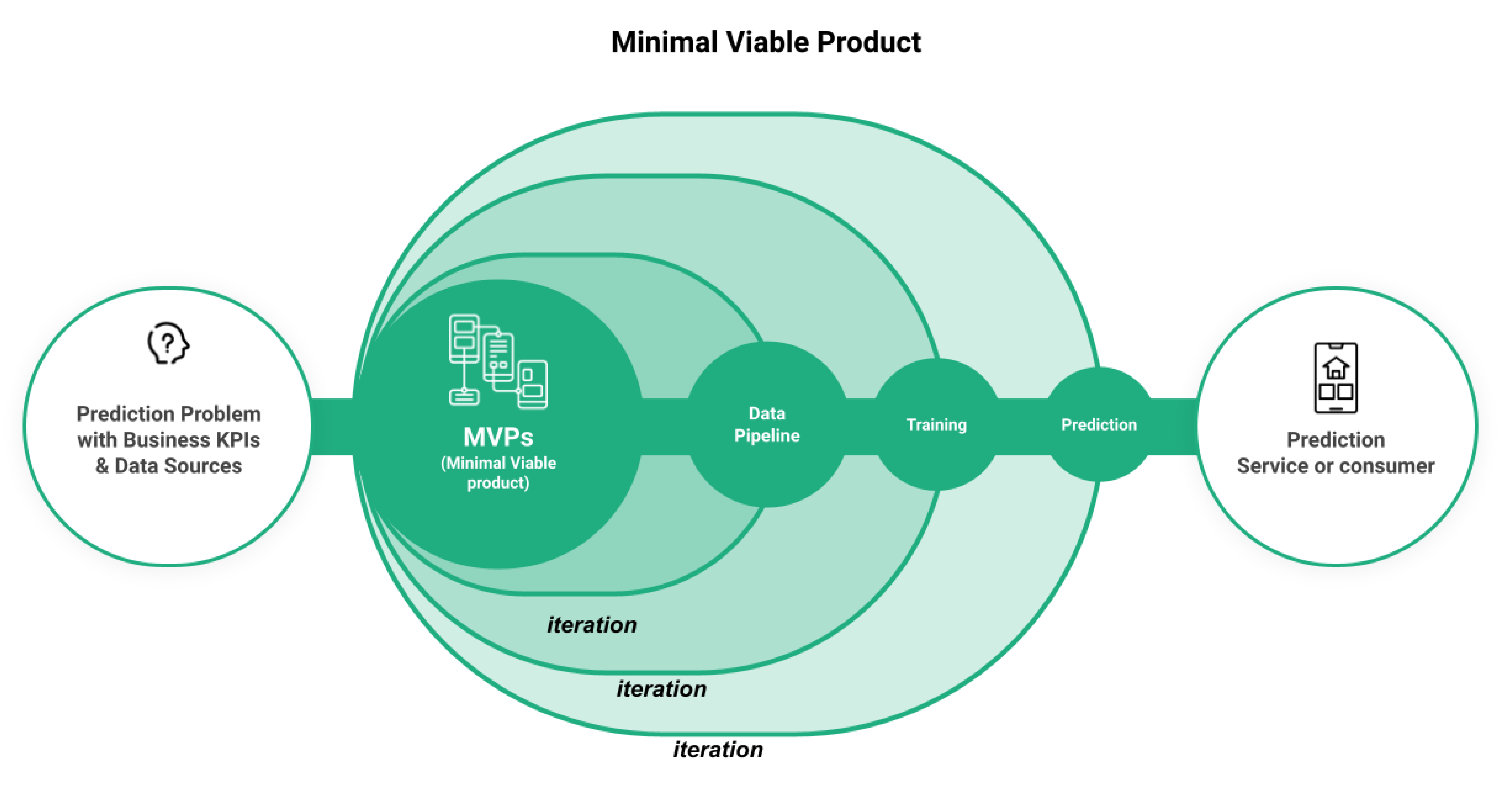
Figure 3. MVPs
The MVP approach allows you to be more nimble in making decisions and changes to your pipelines and with the appropriate technology it empowers your organization to generate value faster and helps onboard stakeholders in the process.
Beyond the frame of work you choose; here are other considerations that are important when you have decided on implementing (or even building!) a feature store:
- Establish the role of the Feature Store, for you: As they play essential functions in the management of machine learning systems and provide an unified layer for feature data, feature stores are also very often rich in a diverse set of capabilities. It is essential that you first establish the dominant roles that you want your feature store to play in your team’s ML ecosystem. As we see in some of the next points; leveraging existing tools, skills and tables is important. Spend time establishing a clear picture as to what your feature store accomplishes for your organization.
- Build or buy decision: decide on where you can add most value to your ML system, fastest. Do you need to first build the infrastructure for managing data for ML (build) or can you start by building ML pipelines for your data and build on existing ML infrastructure (buy). While building provides you with the most tailor-made solution for your problem; it might also build a cage around your needs and costs; you are in essence architecting a system for your current requirements, and committing to upgrading that system to keep up with useful new features that appear in other feature stores. Buying enables you to focus on building the pipelines and models that add value to your applications and/or services.
- Leverage existing skills and tools: build the ML pipelines and models using the languages and frameworks that your team already use. Consider what parts of your existing data infrastructure might be already efficiently implemented and could be extended to the feature store. For example, could you reuse existing tables containing feature data in Snowflake without the need to re-implement your existing pipelines? How well does the feature store integrate with your existing data tools for cataloging, visualization, and pipeline orchestration?
- Modularity and future-proofing: Most data science teams use Python for data science - creating features, models, and making predictions (inference). What is the cost for you (and them) to change languages or tools that will lock you in to a specific vendor and they will not see as adding value to their careers. Your feature store should be open, and fit well into the wider technical ecosystem of data science.
- Scalability: What happens if the service or application you “AI-enable” increases in popularity? Scaling a machine learning system is no small task. It is not merely a matter of handling a larger quantity of data, but it also involves managing an increasing number of features, dealing with a higher frequency of updates, and coordinating more complex model serving scenarios. Your feature store implementation should be flexible enough to allow for that change in scale and be resilient enough to support it.
4- Additional Considerations before Implementing a Feature Store
Before moving to your implementation of a feature store, you might want to tackle a few common misconceptions of feature stores. Some are benign misunderstandings that require a deeper understanding of the technology and challenges, while others might lead your organization down a rabbit hole from which it will take months, or even years to emerge.
- “A feature store is just storage” This falls under a benign misconception. Yes, the feature store provides storage of feature data and metadata. From that perspective anything could be a feature store; a warehouse, a database, or any kind of object storage. Yes, feature stores use the same underlying storage technologies - large volumes of historical data on less expensive object storage, and smaller volumes of “online” data in a low-latency database. The challenge is in building the APIs for ingestion and retrieval of consistent data from these stores, and providing the metadata to enable security and governance. Creating a cohesive ensemble of tools that can communicate with the different systems via an productive API is what makes the feature store more than just a storage.
- “We can build it” This falls under a not so benign misconception. Yes, some hyperscale AI organizations may require extremely use-case specific particularities and have large enough budgets to pull this off (and talk loudly about their achievements), but most companies do not need to build a feature store from scratch. There is a huge opportunity cost in first building the infrastructure for AI, rather than the ML pipelines and models needed for your actual AI systems. As a feature store vendor, we are obviously biased here, but we also have deep experience of the challenges involved. A significant portion of the users of our platform first started by building their own, then reverted to buying over building. Starting by building, and transitioning to buying, also creates tensions in an organization as personal projects get abandoned and sunk costs fallacies often mean decisions are delayed longer than reasonable, leading to larger costs.
- ”Feature Stores are only necessary for large volumes of data”. This belief is derived from the assumption that feature stores are only necessary in certain specialized cases, perhaps for large enterprises with large teams, and an organization may need a feature store only if, and when, they handle large volumes of data. However, it is important not to overlook the other important added value of feature stores – they bring consistency to ML operations, enforce good architectural patterns, connect ML pipelines, enable the reuse of features, support MLOps best practices around versioning, automated testing, and monitoring. Even for smaller data sets, feature stores can deliver substantial benefits in terms of operations, collaboration, security, and governance.
5- Real-world Examples of Feature Store Implementations
Here we cover some real-world examples of companies that successfully implemented feature stores, in particular, we will look at how Hopsworks has been leveraged to make a positive impact in the machine learning operations of a few organizations and we will look at the general lessons we learned along the way in assisting those customers.
American First Credit Union; fast ROI, improved team collaboration
At AFCU, Hopsworks’ feature store powers the Enterprise AI services and integrates all operational and analytical data into machine learning processes, allowing for faster development cycles, integration with existing data warehouses, and providing a flexible environment for data scientists.
Outcome: AFCU achieved significant gains over their previous process for training models. They saw a 3 to 4 times productivity gain while simplifying their machine learning codebase/pipelines. New features were easier to test and data science workflows were improved. AFCU was able to reduce complexity and increase the readability of new features. There was also improved visibility and reusability of features across models and use cases.
Arbetsförmedlingen, National Swedish Employment Agency; Job recommendation system and end to end machine learning.
The Swedish National Employment Agency “Arbetsförmedlingen” needed a highly available production environment for AI and was looking for a feature store capable of not only working as a unified data layer but also to manage and orchestrate workflows and processes around AI, including GPUs for model training and serving models.
Outcome: Arbetsförmedlingen used Hopsworks to quickly serve real-time predictions of suitable job postings. Hopsworks also helped identify discriminatory texts in job announcements. The platform offered centralization and collaboration allowing Data Scientists to work with modern libraries developing, creating feature pipelines and developing AI models in a structured manner.
Human Exposome Assessment Project; Access and analysis of genomic data.
HEAP requires large-scale processing of genomic data on Apache Spark and deep learning to analyze large datasets of human exposome data. HEAP has many activities around identifying novel viruses, performing large cohort studies, and identifying genetic mutations causing diseases.
Outcome: HEAP used Hopsworks to lead the delivery of the Informatics Platform and Knowledge Engine. This enabled data warehousing, stream processing, and deep learning with advanced analytics. As a result, HEAP saw a 90% cost reduction, faster data processing, and an integrated data science platform.
6- Conclusions and lessons learned
In examining many of our customers’ journeys in implementing a feature store, and as one of the leaders in this new field, we have gleaned valuable insights in how data for AI has emerged as the core capabilities for operational machine learning systems. Our main conclusion is that companies that implement a feature store see faster iteration and faster models in production; it also allows them to scale and move to real-time machine learning use cases with more ease.
There has also been an obvious increase in market interest in feature stores in 2023 (Snowflake Summit had 4 tracks dedicated to feature stores this 2023 summer, and Microsoft is the last of the 4 main cloud players to announce their own light-weight implementation of one), which only reinforces the position of the feature store as a core technology in the ML system and MLOps spaces.
Here are some additional lessons we believe are valuable for anyone considering machine learning systems as a whole, and even more importantly through the scope a feature store;
- Plan for changes: Whether it's a matter of adjusting to changes in feature data or supporting new use cases, you need the agility to evolve rapidly
- Promote collaboration: Create an environment that removes the silos between the different data and ai teams, you can not build a system that is isolated from the business or from the other systems
- Build for High Availability and fault tolerance: machine learning models are business critical operations, and if they are not they will likely be! Design your ML systems with high availability and fault tolerance in mind.
- Data governance is not an afterthought: Control and audit access to the data and models. ML assets should be versioned and cataloged - as data volumes and complexity increases, managing metadata for ML assets effectively becomes a non-negotiable requirement.
- Design to be part of an ecosystem: Do not create a system that operates in isolation but rather as part of a wider data ecosystem of tools. Compatibility is a significant advantage.
Ultimately, you need a feature store not because we say so, but because your models need a feature store to run in production. You need a feature store to generate value from your models.