Feature Store for MLOps? Feature reuse means JOINs
Use JOINs for feature reuse to save on infrastructure and the number of feature pipelines needed to maintain models in production.


Img from OSDC talk by Twitter. Twitter evaluates their Feature Store by the number of features that are reused across teams.
The Cost of No JOINs: One Feature Pipeline per Model
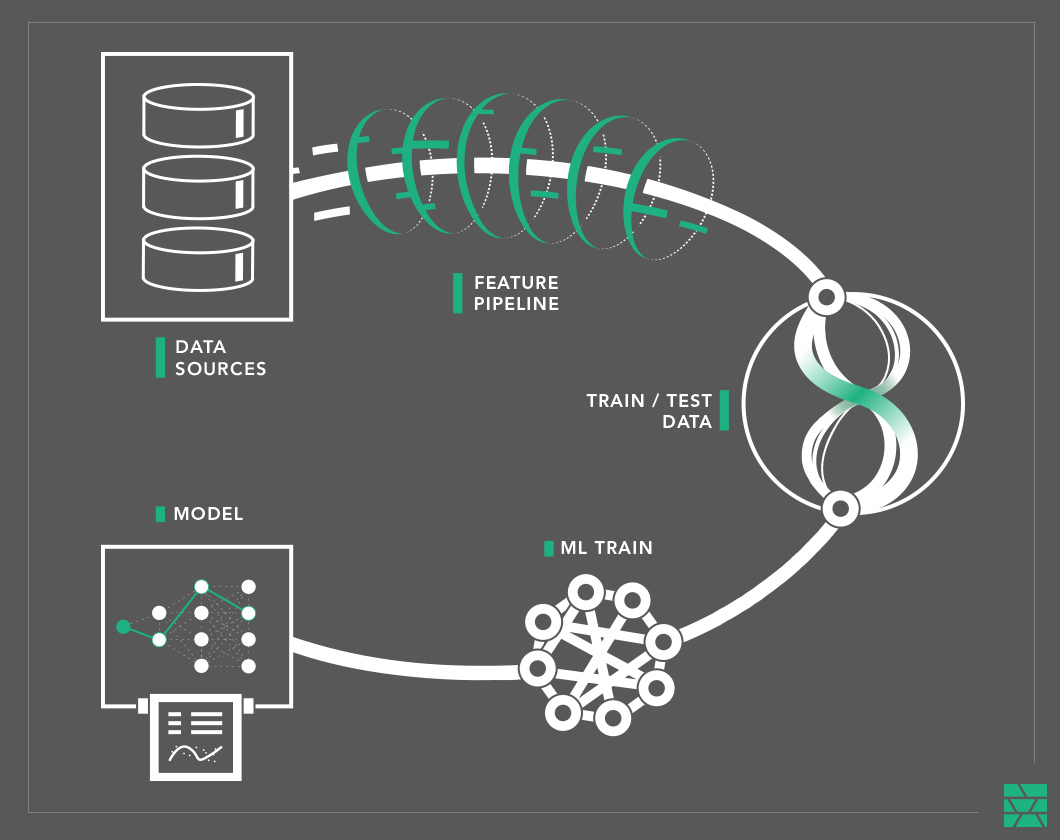
If you don’t reuse features across different models, you will need a new feature pipeline for every new model you put in production. In the diagram below, there is a 1:1 mapping between train/test datasets and models. For every new model you put in production, you will write a new feature pipeline from your data stores that transforms and validates the raw data and performs aggregations, materializing train/test data to files. A ML training program (or pipeline) then trains and validates a model with the train/test data, after which it is tested and deployed to production.
It is very difficult to reuse the features in the materialized train/test datasets, as they tend to be stored in a format specific to a ML framework: .tfrecord for TensorFlow,.npy for PyTorch - and they cannot be easily combined with features stored in other train/test datasets. This is often due to the limitations of the file formats: neither TFRecord nor NPY support projections (selecting just a subset of columns).
If you intend to run hundreds of models in production, running hundreds of pipelines will explode your technical debt.
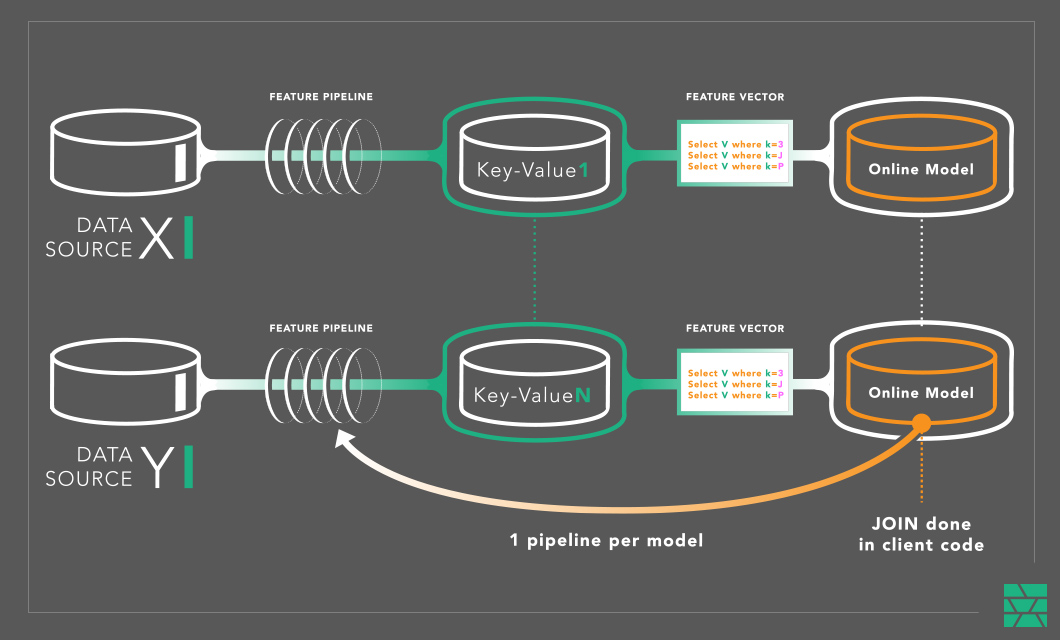
In online feature stores that do not support JOINs, it is typically the responsibility of the application to perform the JOIN of the cached features to create the feature vector. So, if you build your own online feature store using Cassandra or DynamoDB, you will need to also add logic for joining (and ordering) features in your applications/models.
Every new feature you add to that model will need an update to the feature pipeline and changes to the application logic - making it costly and potentially cross-team work.
JOINs enable Feature Reuse
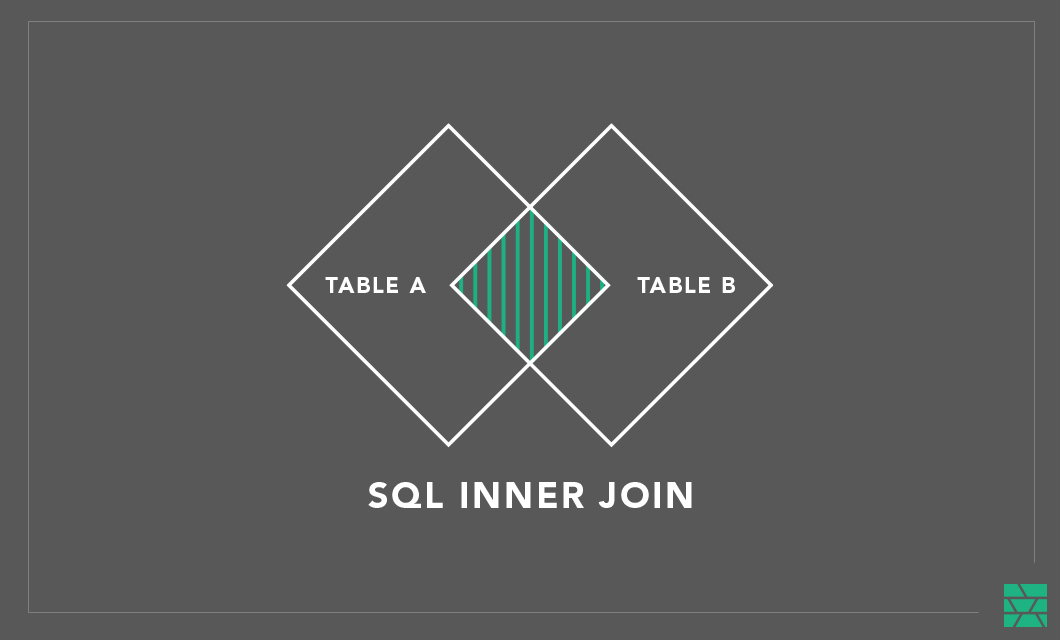
A JOIN is a Structured Query Language (SQL) command to combine data from two different two database tables. JOINs are used to create a view over the data that originates from one or more tables. If we assume that we store features normalized in database tables, then we are able to create sets of features (training datasets) by selecting different features from different tables and joining them together using a common join key. The join key(s) identify the common entity these feature values represent.
If we now assume that features are stored as columns in tables, then what is a train/test dataset? It is a set of features along with a target column. Assuming the features are already present in existing tables, we can just join those features (columns) together to create a view - this view is the train/test dataset. The order of features (in a view) that makes up a train/test dataset is significant - a train/test dataset is a permutations of features - not a combination. Views (enabled by JOINs) enable a massive number of train/test datasets to be defined over a small number of shared features (stored in tables)
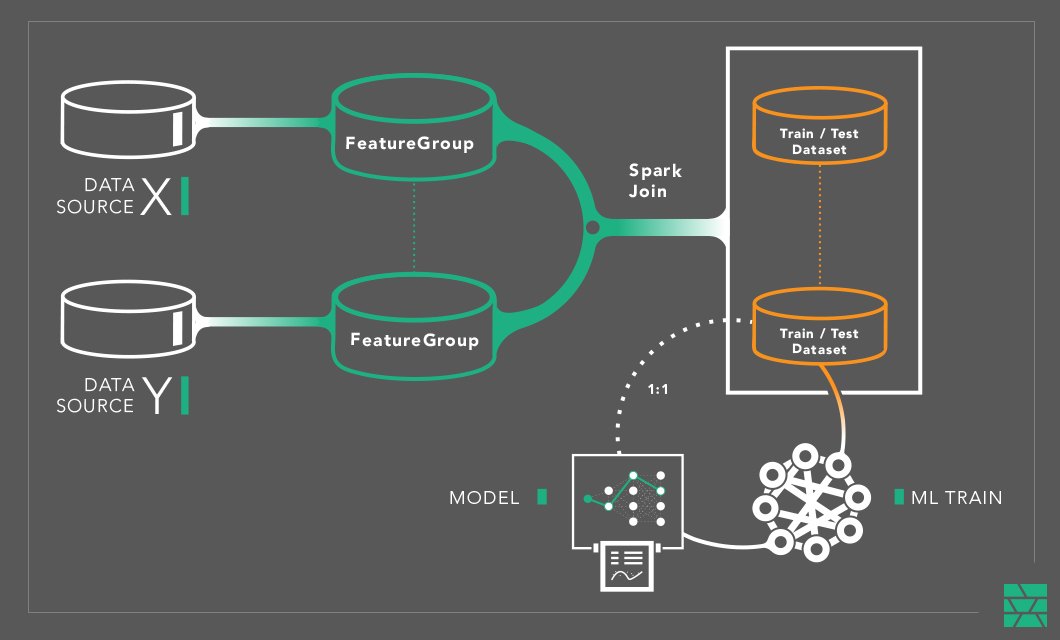
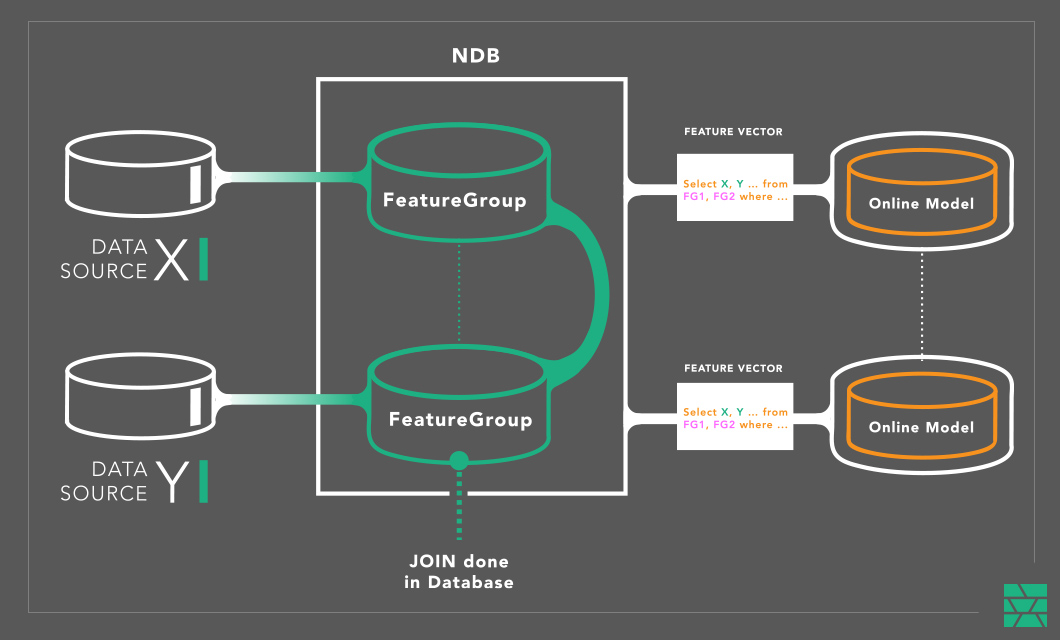
In Hopsworks, we store features in tables that we call “Feature Groups”. Feature Groups introduce a level of indirection between the raw input data and the train/test datasets used to train models, see below. They store a cached copy of the features, computed using the same feature pipeline from earlier, but this time, the feature pipeline writes to one or both of the stores that much a feature store: (1) a scalable store for train/test features (offline feature store) and (2) a low latency, high throughput store for features for serving (online feature store).
In Hopsworks, we use Apache Hive as a scalable database for the offline store, and MySQL Cluster (NDB) as the online store. Our version of Hive stores its metadata in NDB and its data files in HopsFS/S3. In Hopsworks, FeatureGroups are database tables in Hive and MySQL Cluster, along with feature metadata (also tables in the same NDB database).
As we can see in the diagram below, if we have N features available in the Feature Store, we can create an unlimited number of train/test datasets by simply joining features together from the offline feature store.
In Hopsworks, we use Spark, with its cost-based optimizer, to perform JOINs. Spark, together with Parquet/Hudi/ORC help optimize joins by supporting partitioned data, push-down projections, SortMergeJoin, and
- a hint;
- a join type (inner, left, outer, etc);
- a join condition (equi-join);
- an estimation of the input data size .
JOINs in Online Feature Stores
If you use a KV store as your online store, you are back in the same situation as at start - you need a feature pipeline for every new model you put in production. But with Feature Groups (tables in NDB), we can materialize feature vectors (the individual row of features that is fed directly to the model for scoring) from the different tables by performing a join.
NDB supports sophisticated optimizations for JOINs, and can push-down many JOINs to the database nodes. In practice, in NDB even complex queries can “achieve latency down to 5-10 ms for a transaction that contains around 30 SQL statements”.
Conclusions
Reuse features to save on infrastructure and the number of feature pipelines needed to maintain models in production. JOINs is the method we use in Hopsworks to reuse cached features across different models - both for training and serving. We use Spark as the JOIN engine for the offline feature store and NDB with its parallelized, push-down JOINs for low-latency joins in the online feature store.