NVMe now in HopsFS
Read how HopsFS addresses this issue of storing and accessing datasets as image files stored in a distributed file system (DFS) at large scale.

Datasets used for deep learning may reach millions of files. The well known image dataset, ImageNet, contains 1m images, and its successor, the Open Images dataset has over 9m images. Google and Facebook have published papers on datasets with 300m and 2bn images, respectively. Typically, developers want to store and access these datasets as image files, stored in a distributed file system. However, according to Uber, there’s a problem:
“multiple round-trips to the filesystem are costly. It is hard to implement at large scale, especially using modern distributed file systems such as HDFS and S3 (these systems are typically optimized for fast reads of large chunks of data).”
Uber’s proposed solution is to pack image files into larger Apache Parquet files. Parquet is a columnar database file format, and thousands of individual image files can be packed into a single Parquet file, typically 64-256MB in size. For many image and NLP datasets, however, this introduces costly complexity. Existing tools for processing/viewing/indexing files/text need to be rewritten. An alternative approach would be to use HopsFS.
HopsFS solves this problem by now being able to transparently integrate NVMe disks into its HDFS-compatible file system, see our peer-reviewed paper at ACM Middleware 2018. HDFS (and S3) are designed around large blocks (optimized to overcome slow random I/O on disks), while new NVMe hardware supports fast random disk I/O (and potentially small blocks sizes). However, as NVMe disks are still expensive, it would be prohibitively expensive to store tens of terabytes or petabyte-sized datasets on only NVMe hardware. In Hops, our hybrid solution involves storing files smaller than a configurable threshold (default: 64KB, but scales up to around 1MB) on NVMe disks in our metadata layer. This design choice was informed from our collaboration with Spotify, where we observed that most of their filesystem operations are on small files (≈64% of file read operations are performed on files less than 16 KB). Similar file size distributions have been reported at Yahoo!, Facebook, and others.
The result is that when clients read and write small files, they can do so at an order of higher magnitude in throughput (number of files per second), and with massively reduced latency (>90% of file writes on the Spotify workload completed in less than 10ms, compared to >100ms for Apache HDFS). In HopsFS, most incredibly, the small files stored at the metadata layer are not cached and are replicated at more than one host. That is, the scale-out metadata layer in HopsFS, can be scaled out like a key-value store and provide file read/write performance for small files compatible with get/put performance for modern key-value stores.
NVMe Disk Performance
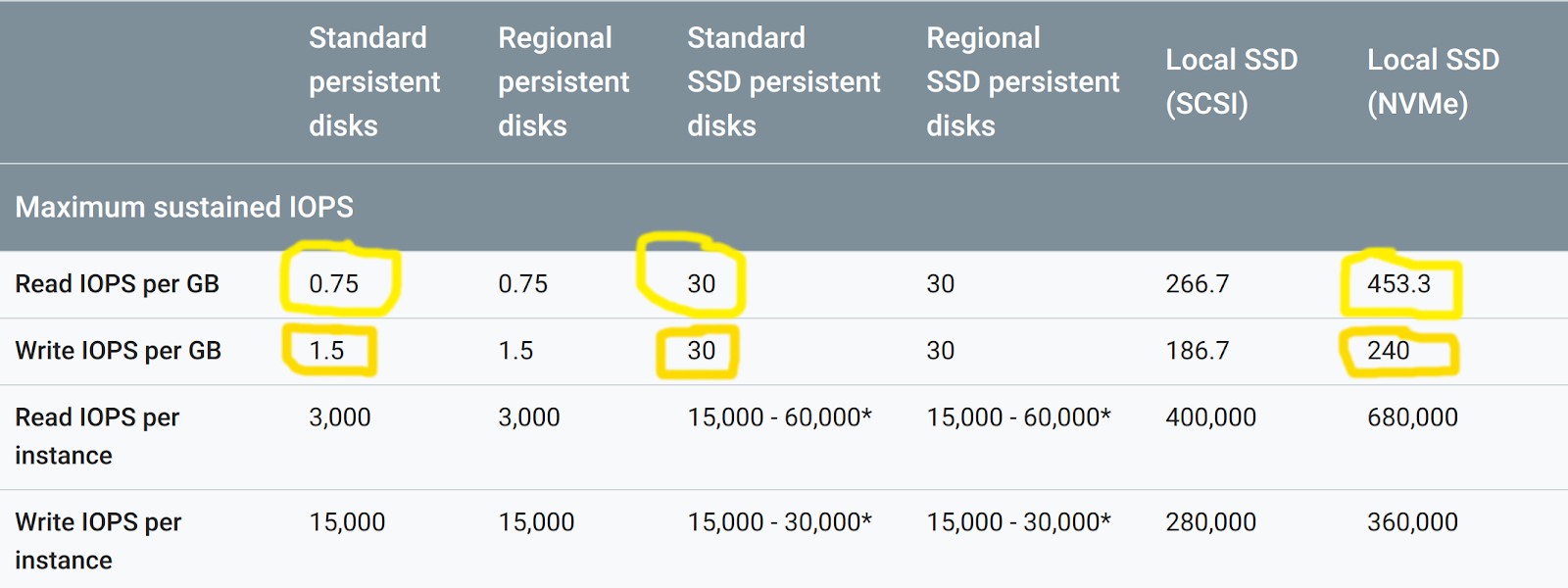
Figure 1. Disk performance figures
As we can see from Google Cloud disk performance figures, NVMe disks support more than 2 orders of magnitude more IOPs than magnetic disks, and over 1 order of magnitude more IOPs than standard SSD disks.
Key-Value Store Performance for Small Files
In our Middleware paper, we observed up to 66X throughput improvements for writing small files and up 4.5X throughput improvements for reading small files, compared to HDFS. For latency, we saw operational latencies on Spotify’s Hadoop workload were 7.39 times lower for writing small files and 3.15 times lower for reading small files. For real-world datasets, like the Open Images 9m images dataset, we saw 4.5X improvements for reading files and 5.9X improvements for writing files. These figures were generated using only 6 NVMe disks, and we are confident that we can scale to much higher numbers with more NVMe disks.
We also discuss in the paper how we solved the problems of maintaining full-HDFS Compatibility: changes for handling small files do not break HopsFS’ compatibility with HDFS clients. We also address the problem of migrating data between different storage types: when the size of a small file that is stored in the metadata layer exceeds some threshold then the file is reliably and safely moved to the HopsFS datanodes.
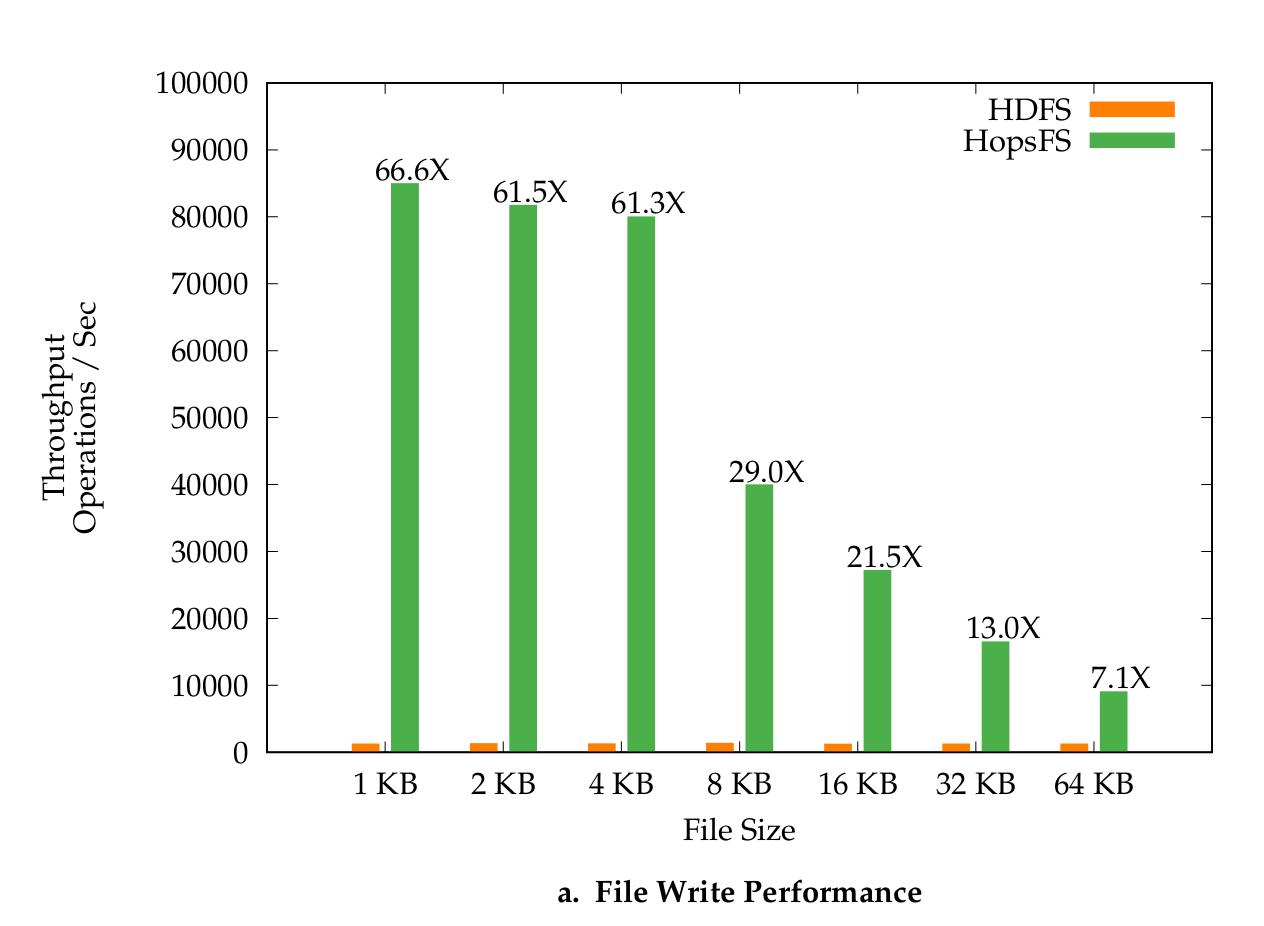
Figure 2. File Write Performance
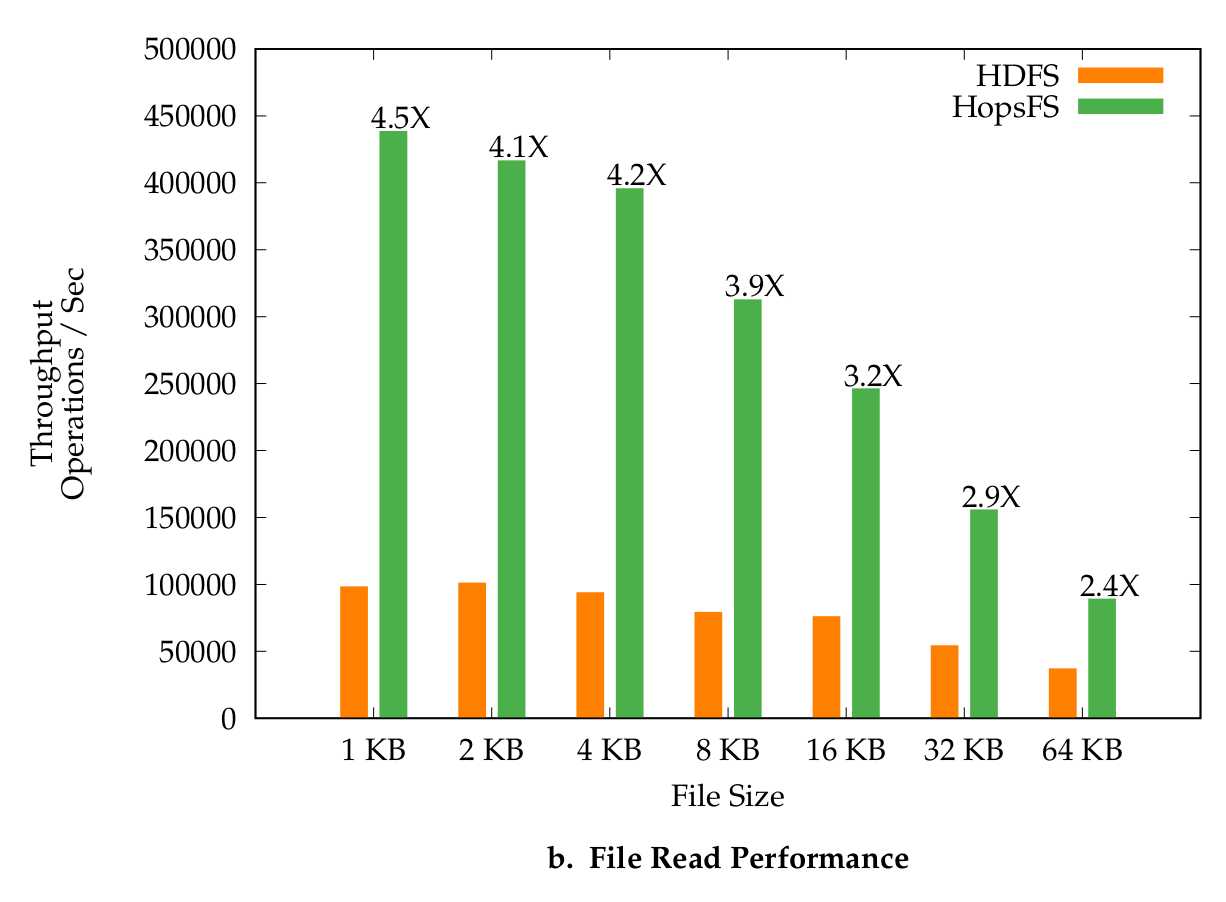
Figure 3. File Read Performance
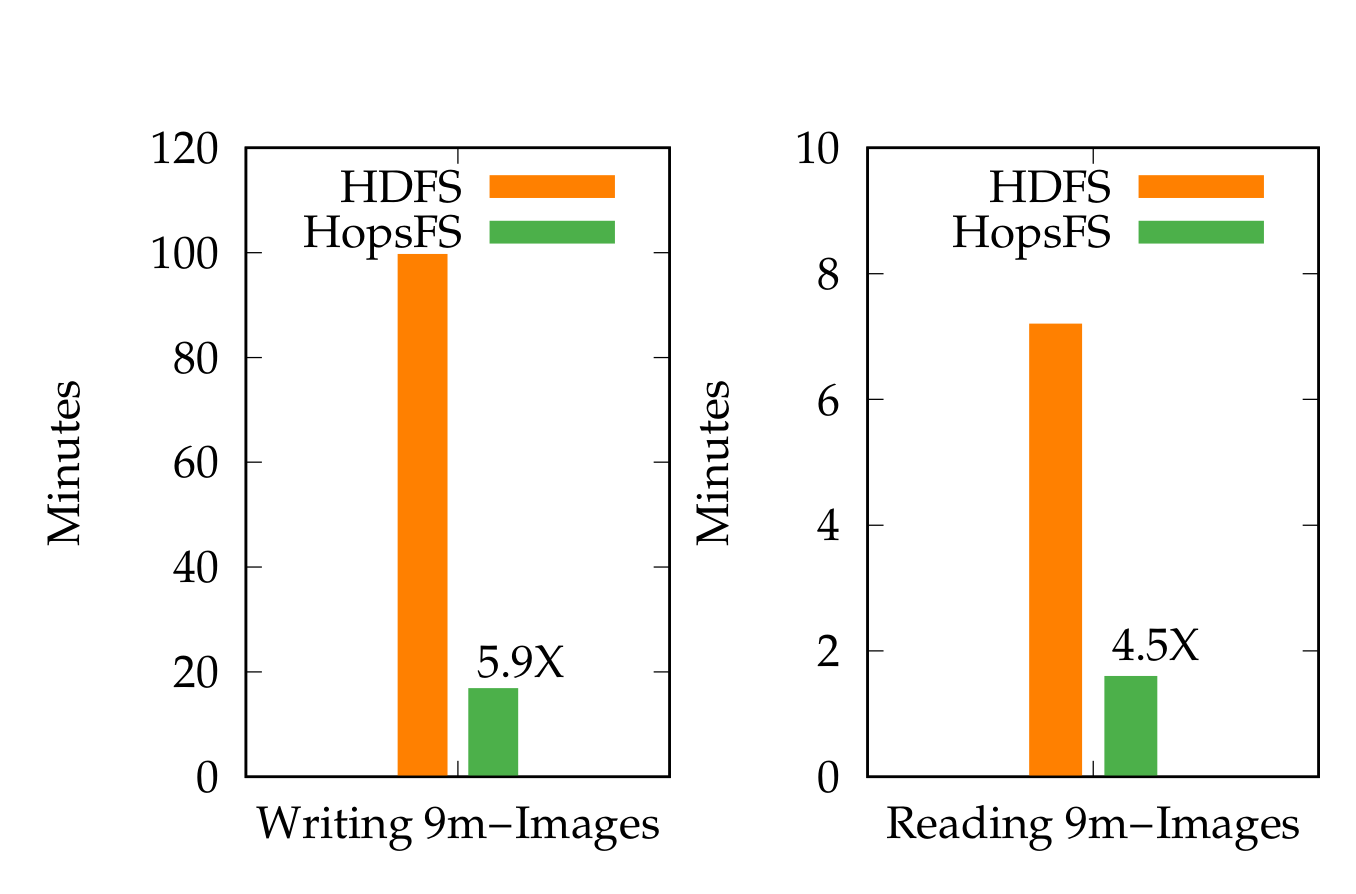
Figure 4. Reading - Writing Comparison
Running HopsFS (on-premise or in the cloud)
You can already benefit from our small files solution for HopsFS that has been available since HopsFS 2.8.2, released in 2017.
Since early 2018, NVMe disks are now available at Google Cloud, AWS, and Azure. Hopsworks can help with providing support for running HopsFS in the cloud, including running HopsFS in an availability-zone fault-tolerant configuration, available only in Enterprise Hops.