Delta Lake comes to Hopsworks
Hopsworks has added support for Delta Lake to accelerate our mission to build the Python-Native Data for AI platform.

Introduction
Hopsworks is an open data platform for AI, enabling the use of many compute engines (Pandas, Polars (coming soon), Apache Spark™, Flink, and dbt-SQL) for feature pipelines, training pipelines, and inference pipelines in machine learning. We have now applied our open philosophy to table formats for storing feature data. We have supported Apache Iceberg since Hopsworks 2.0, and now, with Hopsworks 3.7, we are adding support for Delta Lake. We have decided to support Delta Lake to accelerate our mission to build the Python-Native Data for AI platform.
Open and Modular Machine Learning Systems
Machine learning systems consist of (1) ML infrastructure (feature store, model registry, model serving, and vector database) and (2) ML pipelines that create the feature data, train the models, and make predictions (inference).
Hopsworks is a modular platform that enables the construction of modular ML systems. You can run feature pipelines, training pipelines, and inference pipelines on the widest range of compute platforms (Spark, Python, Flink, DBT/SQL, and Neo4J). You can plug in your own model registry, model serving servers, and vector databases to work alongside the industry’s highest-performance feature store - or you can just use Hopsworks for your entire ML infrastructure.
Listing 1. You create a feature group that stores its data in Delta Lake table format by specifying “DELTA” as its time-travel (table) format.
Support for Delta Lake is part of our vision to build a modular ML platform. If you run ML pipelines on Databricks or Microsoft Fabric, you may have Delta Lake tables, and native Delta Lake Feature Groups in Hopsworks provide easier integration. If, however, you want some of the additional capabilities of Apache Hudi, see Table 1, you can choose Hudi as your table format. You can also mix and match and store some feature groups in Delta Lake some in Hudi, depending on your requirements.
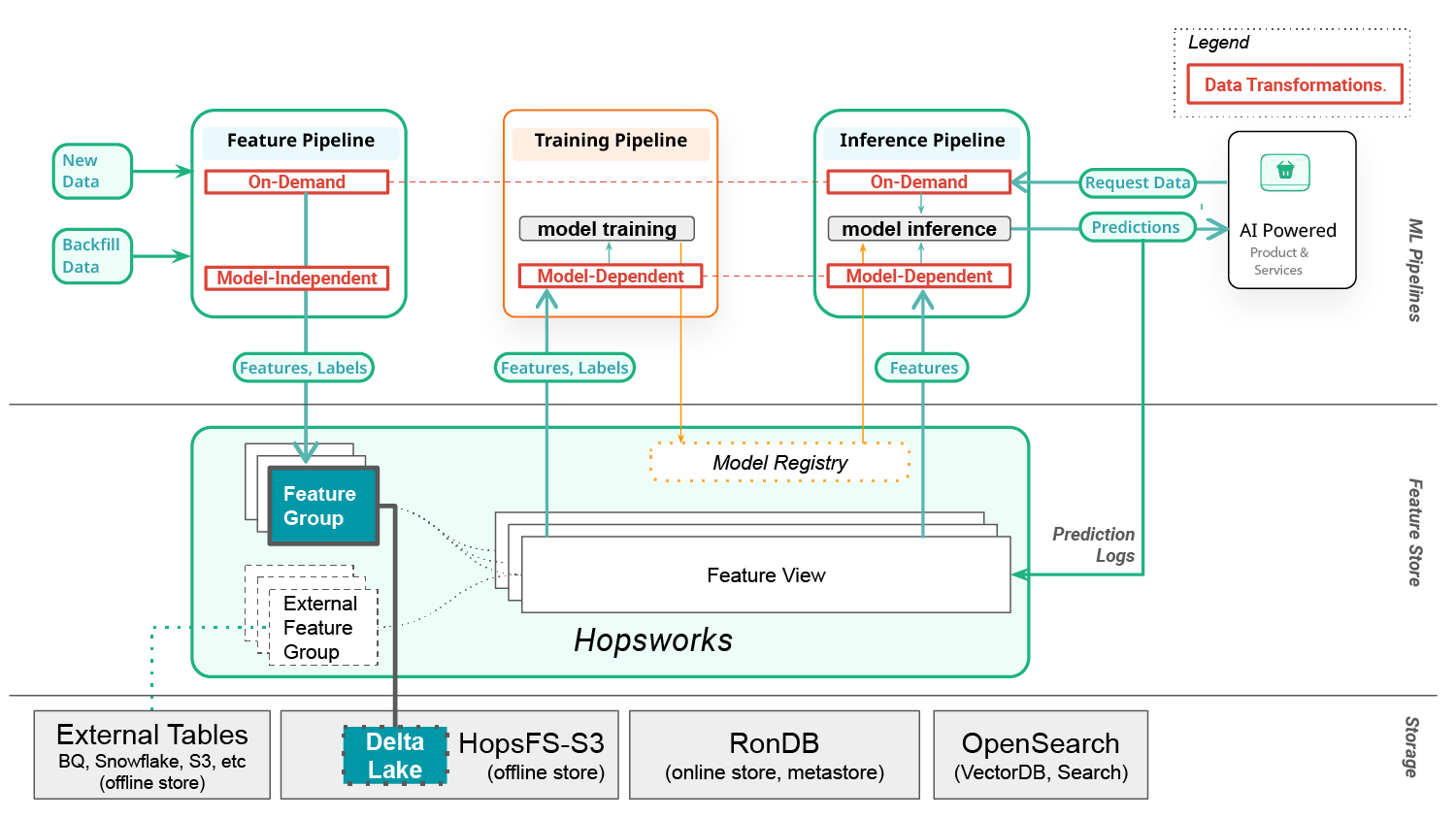
Figure 1. Delta Lake is now supported as a native storage format for Feature Groups in Hopsworks
As shown in figure 1, Delta Lake tables are stored in the Hopsworks Offline store in HopsFS/S3 tables. HopsFS-on-S3 provides the benefits of tiered storage with recent data on local work disks (NVMe), and S3 acts as the long-term store for feature data. HopsFS/S3 helps accelerate reading from table formats like Hudi and Delta Lake, as metadata is spread over many small files, and HopsFS/S3 has excellent performance for small files.
Delta Lake, Apache Hudi, and Apache Iceberg
Delta Lake, Apache Hudi, and Apache Iceberg are the most popular table formats in use today. They all support low-cost storage of tabular data on scalable storage (object stores like S3). They also provide atomic transactions for updating data, isolated and concurrent reads/writes, and metadata to improve slow S3 operations like file listings. In the table below, we summarize some of the differences between the table formats that we see as important for AI workloads.
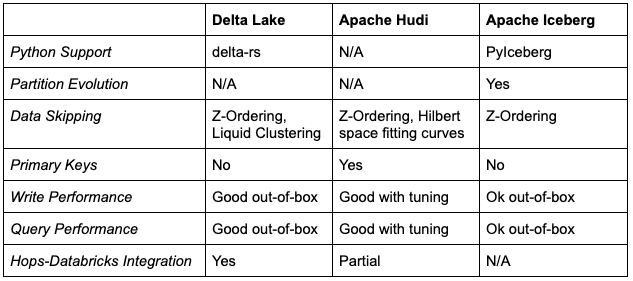
Table 1. A comparison of Table Formats based on different capabilities important for AI workloads with Hopsworks
As you can see, the different table formats each have their own unique selling points and missing capabilities. There is no free lunch when picking a table format - choose the best table format for your workload requirements. Hudi is listed as partial Databricks integration support, as some workloads are compatible, but workloads that use multiple Hive Metastores are not compatible. We also note that although PyIceberg is a promising Python client, it only recently added support for writing in early 2024 but still doesn’t support writing to partitioned tables. For that reason, we see Delta Lake as a faster path to native Python write support for Hopsworks.
Towards a Python-Native Data for AI Platform
Of all Data/AI platforms, Hopsworks supports the largest number of compute engines (Pandas, Polars (coming soon), Spark, Flink, and DBT/SQL) for feature pipelines, training pipelines, and inference pipelines in machine learning. Since Hopsworks 3.0, we have provided native Python support for reading and writing data to feature groups, with the data stored in Apache Hudi tables. However, Apache Hudi does not yet have native Python support, so we developed a Feature Query Service powered by DuckDB and ArrowFlight that provides blazing-fast access to Hudi data for Pandas and Polars clients. However, for Hudi, when Python clients write to Hopsworks, an ingestion job is currently run in Spark to update the Hudi tables. Hopsworks support for Delta Lake will accelerate the ability of Python clients to write directly to the Offline Store with delta-rs, bypassing the need for Spark-based ingestion jobs. Expect some interesting announcements on Python support in Hopsworks in 2024.
Summary
We are always excited to see Hopsworks support more integrations and more use cases. Delta Lake enables better Databricks integration and a path towards Python native feature pipelines. As of Hopsworks 3.7, Delta Lake is currently only supported for jobs that run on Databricks, but wider support is coming in the next Hopsworks release. We still have work to do on periodic auto-compaction and other optimizations, but support for multiple table formats is here to stay in Hopsworks.