Faster reading from the Lakehouse to Python with DuckDB/ArrowFlight
Accelerating the connection between the Feature Store and Python
In this article, we outline how we leveraged ArrowFlight with DuckDB to build a new service that massively improves the performance of Python clients reading from lakehouse data in the Feature Store

Introduction
Feature stores provide APIs for retrieving consistent snapshots of feature data for both model training and model inference. Feature stores are typically implemented as dual datastores, with a row-oriented database providing low latency access to the latest values of feature data for online models via an Online API, and a column-oriented data warehouse or lakehouse providing access to historical and new feature data for training and batch inference, respectively, via an Offline API. These two databases are typically called the Online Store and the Offline Store, respectively.
![]()
Figure 1: Arrow is now used end-to-end from the Lakehouse to Python clients that use an Offline API to read feature data for training models and for making batch predictions (inference)
Similar to other feature stores, Hopsworks has used Spark to implement the Offline API. This is great for large datasets, but for small or moderately sized datasets (think of the size of data that would fit in a Pandas DataFrame in your local Python environment), the overhead of a Spark job and transferring the data to Python clients can be significant. In this article, we introduce a new service in Hopsworks, ArrowFlight with DuckDB, that gives massive performance improvements for Python clients when reading data from the lakehouse via the Offline API. This improves the iteration speed of Python developers working with a feature store, opening up feature stores as a general purpose data platform usable by the wider Python community.
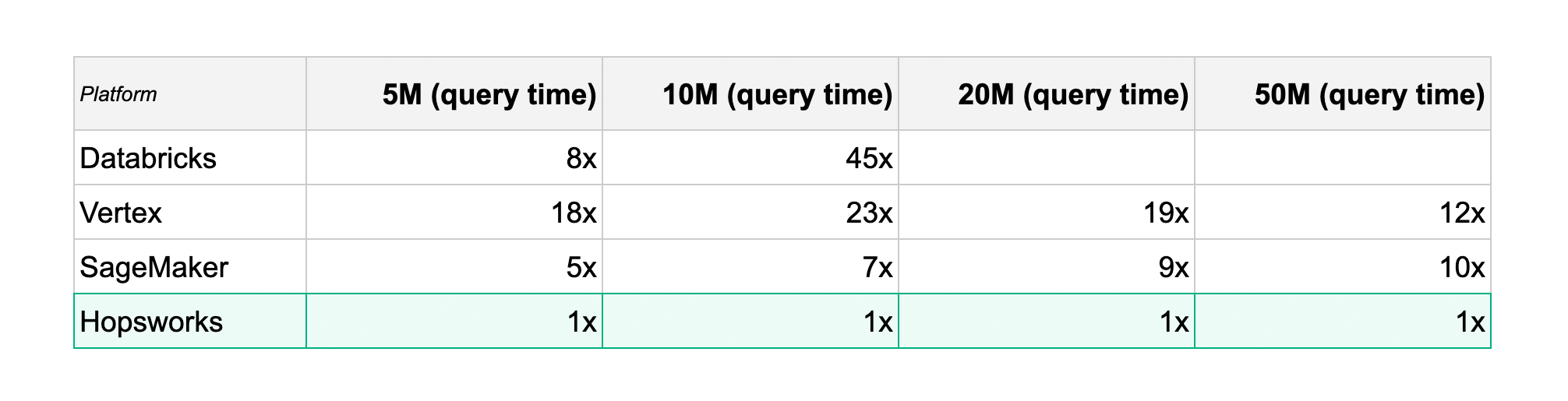
Table 1: Time taken to read feature data from the lakehouse to a Pandas DataFrame

Table 2: Time taken to read feature data from the lakehouse and write out to files
In tables 1,2, you can see a summary of the speedup we observed when using DuckDB/ArrowFlight for moderately sized data, compared to existing feature stores. The details are in the benchmark section below.
ArrowFlight with DuckDB Service
Firstly, let’s introduce the technologies. DuckDB is a lightweight and efficient database management system that has a columnar-vectorized query execution engine which is optimized for analytical workloads. It comes with a zero-copy integration with Pandas and Pyarrow and lots of flexibility in terms of input formats and storage connectors. Our service uses DuckDB to read from tables on object storage and perform point-in-time correct Joins over tables. However, as we built a network service, we needed to enable data to flow securely from DuckDB to Pandas clients without unnecessary serialization/deserialization (thanks Arrow!) or conversion of data from column-oriented to row-oriented and back again (bye bye JDBC!). For this, we used ArrowFlight, a high-performance client-server framework for building applications that transfer arrow data over the network. Independent benchmarks show that ArrowFlight outperforms existing database network protocols such as ODBC by up to 30x for arrow data.
Figure 1 shows how ArrowFlight, DuckDB, and Pandas come together in our new Hopsworks service (here with a Hudi tables as the offline store). By leveraging Apache Arrow we have zero-copy data transfer on server- as well as on client-side, while being able to use ArrowFlight as a high-performance data transfer protocol. We secure data transfers using mutual TLS for client authentication and encryption in-flight and we build on Hopsworks’ existing authorization framework for access control.
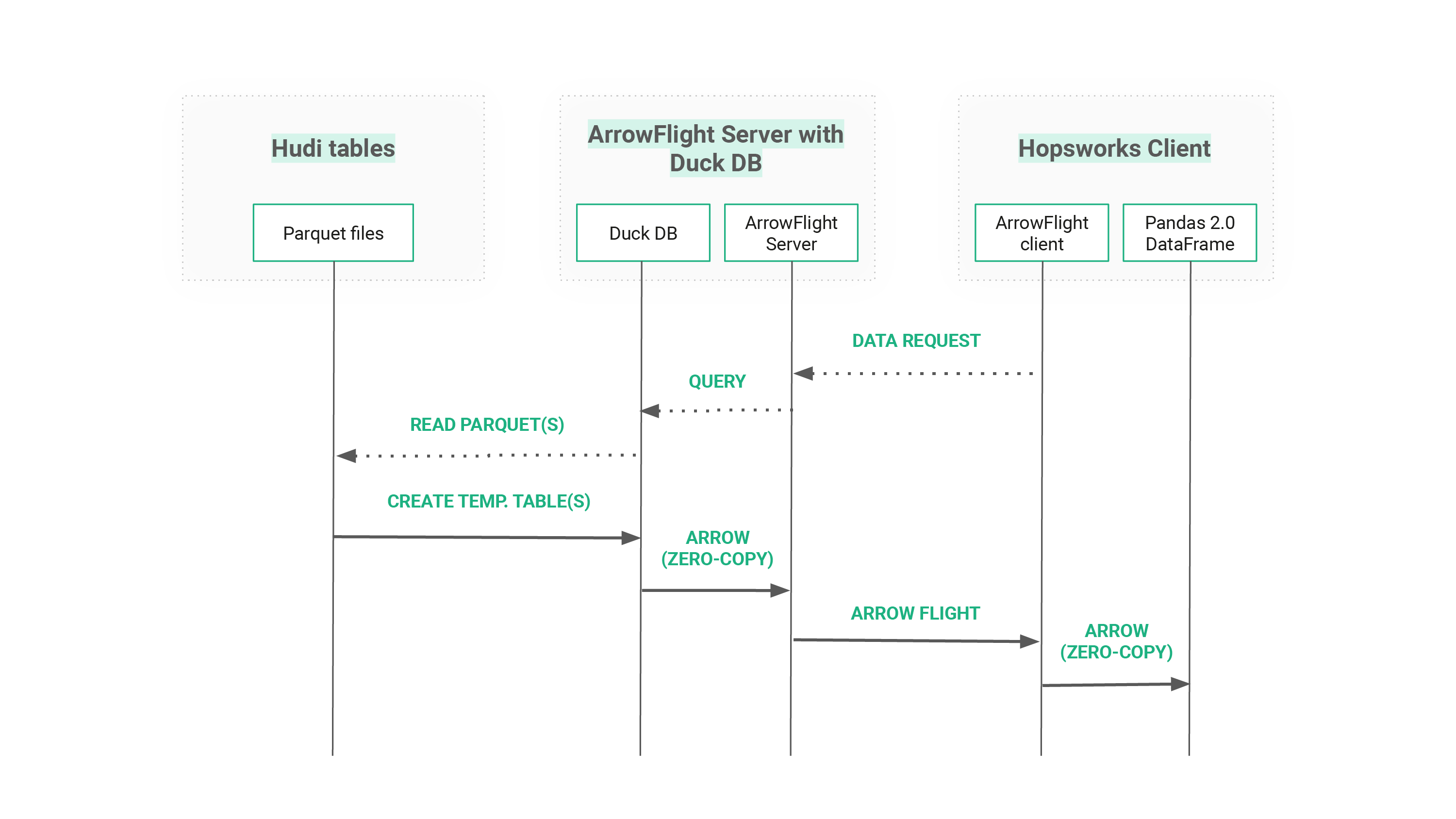
Figure 2: Zero-Copy Mechanism in ArrowFlight Server with DuckDB and Hopsworks Client
High Performance Python-native Access to Lakehouse Data
Apache Hudi is a parquet-based Lakehouse format that is the default offline store in Hopsworks. Whenever a feature store client reads Pandas DataFrames containing either training data or batch inference data, the data is read from Hudi tables (feature groups) and ends up in a Pandas DataFrame, which is then used as model input for training or batch inference.
With ArrowFlight and DuckDB we provide a fast Python-native API to the Hudi tables as well as high performance point-in-time correct Joins for reading consistent snapshots of feature data that span many tables. While Hudi is Parquet-based and DuckDB features a very efficient Parquet reader, DuckDB does not support reading Hudi Tables directly. We therefore developed a custom reader for Hudi Copy-on-Write tables. For all supported offline stores, such as Snowflake or BigQuery, we will provide a different Arrow reader for DuckDB.
Hudi Reader for DuckDB in Detail
Apache Hudi’s storage format is based on parquet files and additional metadata that are stored on HopsFS. One Feature Group is typically not stored as a single parquet file, but the data is broken down into individual files by partitions (based on the Feature Group’s partition key), and then, depending on the file size, further divided into smaller slices within each partition. Each slice has a unique name and is associated with a particular commit-timestamp. When a new commit is made (`fg.insert(df)`), Hudi will quickly identify the latest version of all slices that are affected by the insert/upsert using a bloom filter index and then create updated copies of those slices. Hudi will also create a new .commit metadata file, which contains the list of files that have been updated by the commit. That file will be retained for up to 30 commits. To read the latest snapshot view of a Hudi Table (most up-to-date version of the data), the latest versions of all slices have to be identified and all slices have to be read and unioned into a single Table. Figure 2 shows how Hudi data is organized in HopsFS. Files in Hopsworks are stored in cloud native object storage (S3 on AWS, GCS on GCP, Blob Storage on Azure) but accessed via a fast cache with a HDFS API, called HopsFS.
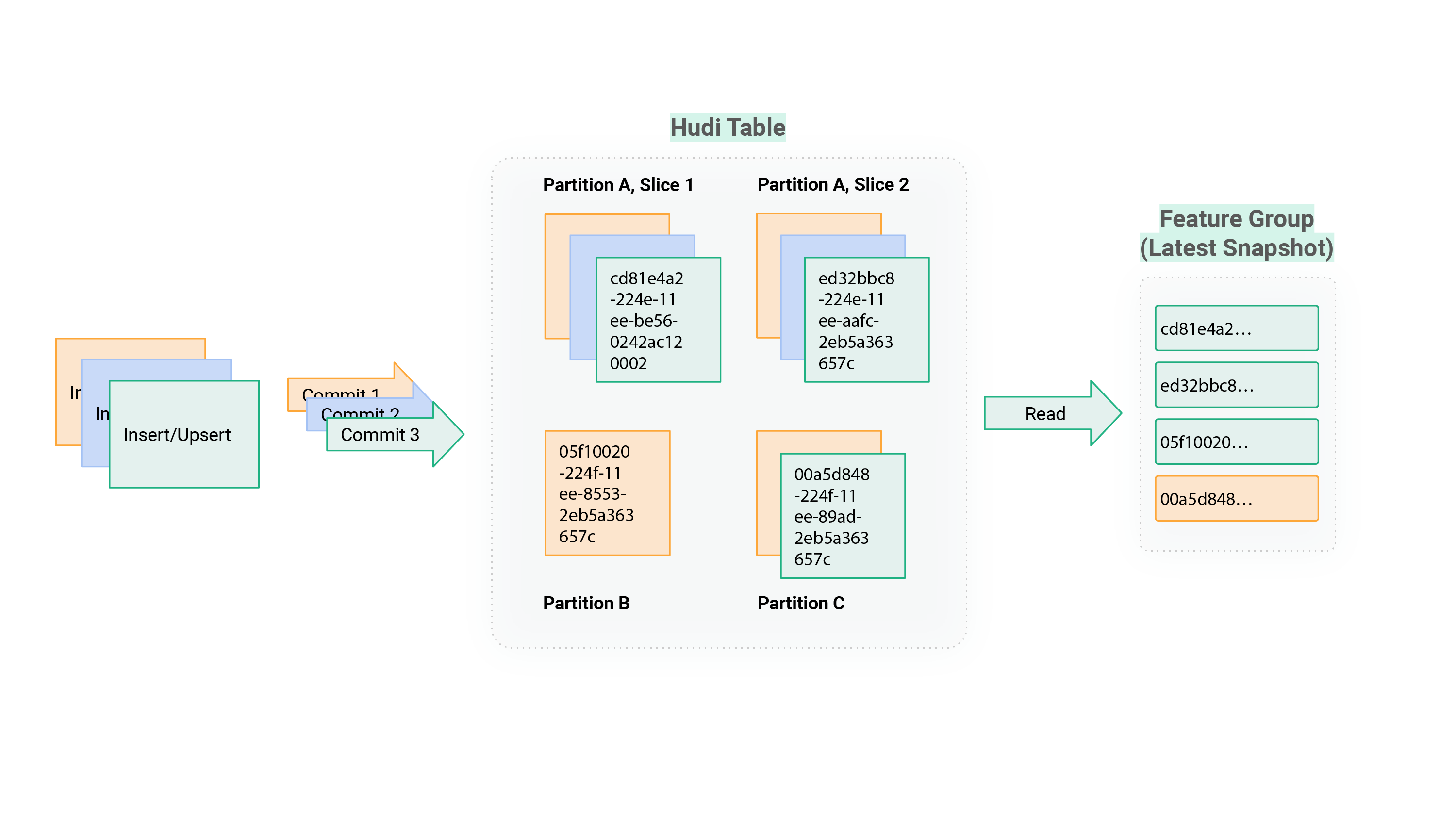
Figure 3: Hudi Copy-on-Write Mechanism with Offline Feature Groups
To read a Hudi Table/Feature Group with DuckDB, we make a recursive file listing in HopsFS to retrieve all parquet-files that belong to a certain Hudi Table. Based on the listing, we identify the latest commit timestamp (which is part of the filename) for each parquet file slice. Slices that are currently in-flight, meaning they belong to a commit that is currently in-progress, are discarded. The correct list of latest parquet files is then passed to DuckDB where we register a unionized temporary table based on all the latest files. This table represents the exact same data we would get with a Hudi Snapshot read via Spark.
If we execute a query (e.g. for creating a training dataset), this process is repeated for all Feature Groups that are required by the query. After the table registration, the input query will simply be executed by the DuckDB SQL engine on the previously registered tables.
Incremental file listing updates
After the initial full file listing is established, we can keep the listing in-memory and update it incrementally whenever a new commit is made, using information from the Hudi .commit file. While file listings in HopsFS are very efficient, this further improves read performance on Feature Groups with deeply nested partition keys and/or a high number of commits.
Filter Pushdown
When Hudi Feature Groups are partitioned and you have defined a filter on the partition column in your Query, we leverage that to prune out paths from the full file listing that do not match the filter condition, before registering them in DuckDB. This can significantly reduce the memory requirements and query runtime for DuckDB.
DuckDB’s HopsFS access
Since data is stored on HopsFS, DuckDB needs to be able to read files directly from HopsFS. For this we leverage the extensibility of DuckDB’s filesystem layer via fsspec. Thanks to fsspec’s Hadoop File System Implementation, and HopsFS’s compatibility with HDFS, we can achieve that with minimal friction.
Read Training Datasets at Higher Throughput
With ArrowFlight and DuckDB, Python clients can read feature groups, batch inference data, as well as create in-memory training datasets at higher throughput than with Spark. Furthermore, users can also read materialized training datasets in Hopsworks at improved throughput compared to the previous REST API solution.
Client Integration
There are no API changes needed for Hopsworks clients to use ArrowFlight with DuckDB in the Python client, beyond upgrading to Hopsworks 3.3+. All notebooks and Python scripts you built with Hopsworks can remain the same. Once a cluster is deployed with “ArrowFlight Server'' (see installation guide), the following operations will automatically be performed by the new service:
- reading Feature Groups
- reading Queries
- reading Training Datasets
- creating In-Memory Training Datasets
- reading Batch Inference Data
For larger datasets, clients can still make use of the Spark/Hive backend by explicitly setting read_options={"use_hive": True}.
Offline Feature Store Benchmarks
We benchmarked the main four publicly available cloud-native feature stores using the NYC Taxi Dataset. We omitted open-source feature stores, as they require manual configuration for their offline data lake/warehouse, or feature stores that are not generally accessible. You can reproduce this benchmark using the code published on github.

Figure 4: This offline feature store benchmark measures the total time required to read data from the feature store to a Pandas client.
The “Offline API” to a feature store is a batch API for reading point-in-time consistent feature data. The Offline API is used by both training pipelines (you read feature data and output a trained model) and batch inference pipelines (you read a batch of new feature data and the model, and then output the model’s predictions on the batch of new feature data).
There are typically two versions of the Offline API:
- read the feature data directly as a Pandas DataFrame or
- create a batch of feature (and label) data as (parquet or csv) files that will be used by either a subsequent model training pipeline or batch inference pipeline.
As such, we provide benchmarks for both (1) the Read an In-Memory Pandas DataFrame use case and the (2) create feature data (training data) as files.
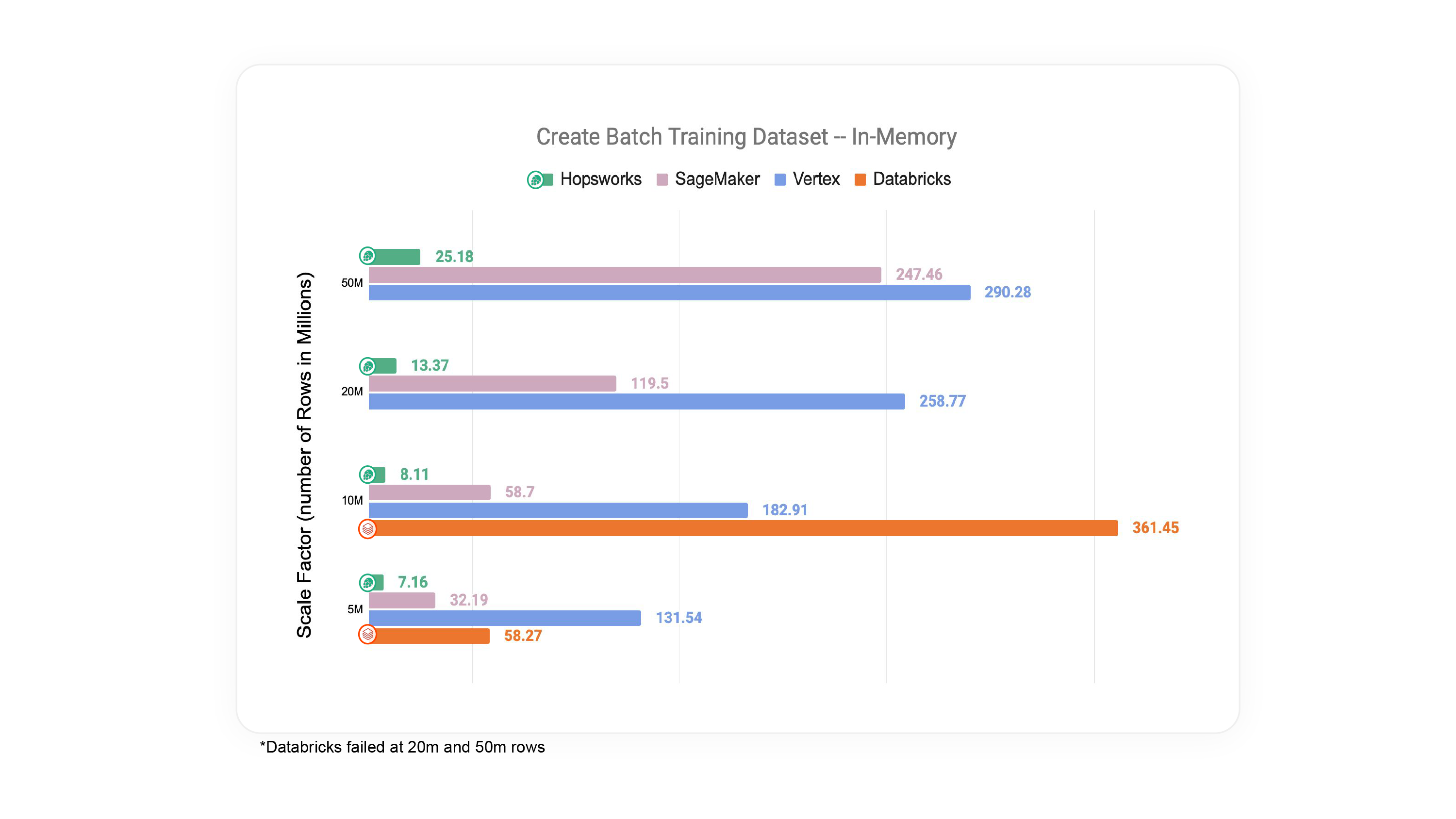
Figure 5: Total time required to read data from the feature store to a Pandas client for NYC dataset.
In figure 4, we can see that Hopsworks has the lowest time required to read 5m, 10m, 20m, and 50m rows as a Pandas DataFrame. The performance differences can be explained by a combination of
- no serialization/deserialization in Hopsworks due to use of Arrow end-to-end,
- no conversions from columnar-to-row-oriented or row-oriented-to-columnar (as happens when you use JDBC/ODBC), and
- DuckDB is a higher performance point-in-time-join engine.
The other feature stores use distributed query engines, Spark/Photon (Databricks), Athena (Sagemaker), and BigQuery (Vertex). The Python APIs for these frameworks act as wrappers for ease-of-use but there is significant overhead when using these systems. While Spark, Athena, and BigQuery do support Arrow as a data interchange format, it is not enough in these cases to remove the additional overhead that comes with a distributed and serverless engine. Spark is designed to handle large-scale data processing across multiple nodes in a cluster. While this architecture allows Spark to scale horizontally and process massive datasets, it introduces additional overhead in data distribution and communication between nodes. Often, Spark can require data to be repartitioned across workers to enable parallel processing. This additional step called shuffling can introduce significant latency in the process.affecting performance. Once Spark is finished doing transformations, there is an additional wait for it to collect all the data from each of its executors and then convert that data to a Pandas DataFrame. With Databricks Photon integration with Spark we see also that Photon is a library loaded into the JVM from where it communicates with Spark via the Java Native Interface (JNI), passing data pointers to off-heap memory. Despite Photon itself being written in C++ as a native, vectorized engine, it passes data back through the Spark pathway before it reaches the client. With BigQuery we see another issue when materializing data as a DataFrame. BigQuery doesn’t materialize directly to the client. Instead, a temporary, intermediate table is first created which acts as the materialization source from which the DataFrame is then served and the table is deleted after use. This introduces a latency almost equivalent to doing a file write for in-memory datasets. Sagemaker’s Athena does somewhat better, but is doing row-oriented to/from columnar conversions.
Given the improved performance in Hopsworks, we can see that there is a clear benefit when data processing engines are optimized for the storage format against which they are interacting. DuckDB optimizes query execution with filter pushdowns and predicate scans and is partition-aware. Additionally, DuckDB can operate directly on Arrow Tables and stream Arrow data back and forth which allows it to utilize Arrow’s zerocopy data transfer mechanism for fast data transfer. With a format-aware and storage-optimized engine consistently using Arrow from lakehouse all the way to the client we can see data transfer happening at near network-line speeds. Arrow Flight securely transfers data across all languages and frameworks without requiring any serialization/deserialization. Arrow Flight achieves this by operating directly on Arrow RecordBatch streams and does not require accessing data on a row level as opposed to JDBC/ODBC protocols. Our higher performance results are not surprising as VoltronData have shown how the ADBC protocol massively outperforms JDBC/ODBC for columnar datastores.
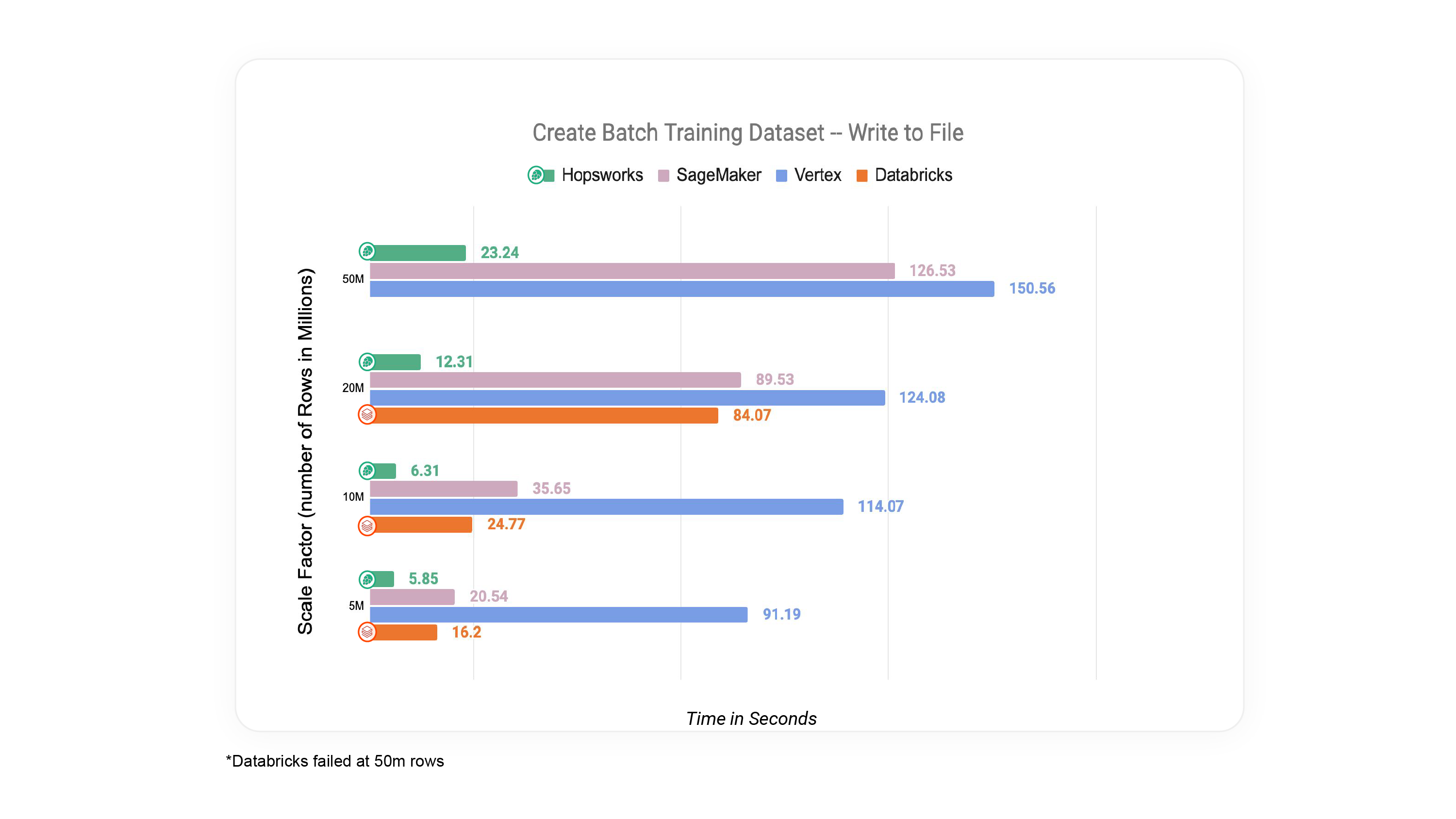
Figure 6: Total time required to create training data as Parquet files using the feature for NYC dataset.
Similarly, when we create files containing feature data, for training data or for batch inference data, we can see similar performance gains using Hopsworks, compared to other feature stores.
Performance Benefits for Python Developers in Hopsworks
To provide a more concrete example for Python developers, we compare the runtime of our Hopsworks Fraud Detection Batch Tutorial using ArrowFlight w. DuckDB against Spark (see Table 1). The total runtime of all compute-intensive tasks, goes down from 4.6 minutes to less than 16 seconds. Instead of waiting 10s for a training dataset to load, it now only takes 0.4s and feels almost instantaneous, which demonstrates the practical benefits that our new service brings to interactive Python client environments. This will significantly improve the iteration speed for Python developers working with feature data in Hopsworks. Note, we are big fans of Spark - we have worked hard on improving Point-in-Time Join performance in Spark, but for Python clients and moderately sized data, ArrowFlight and DuckDB is a better fit.
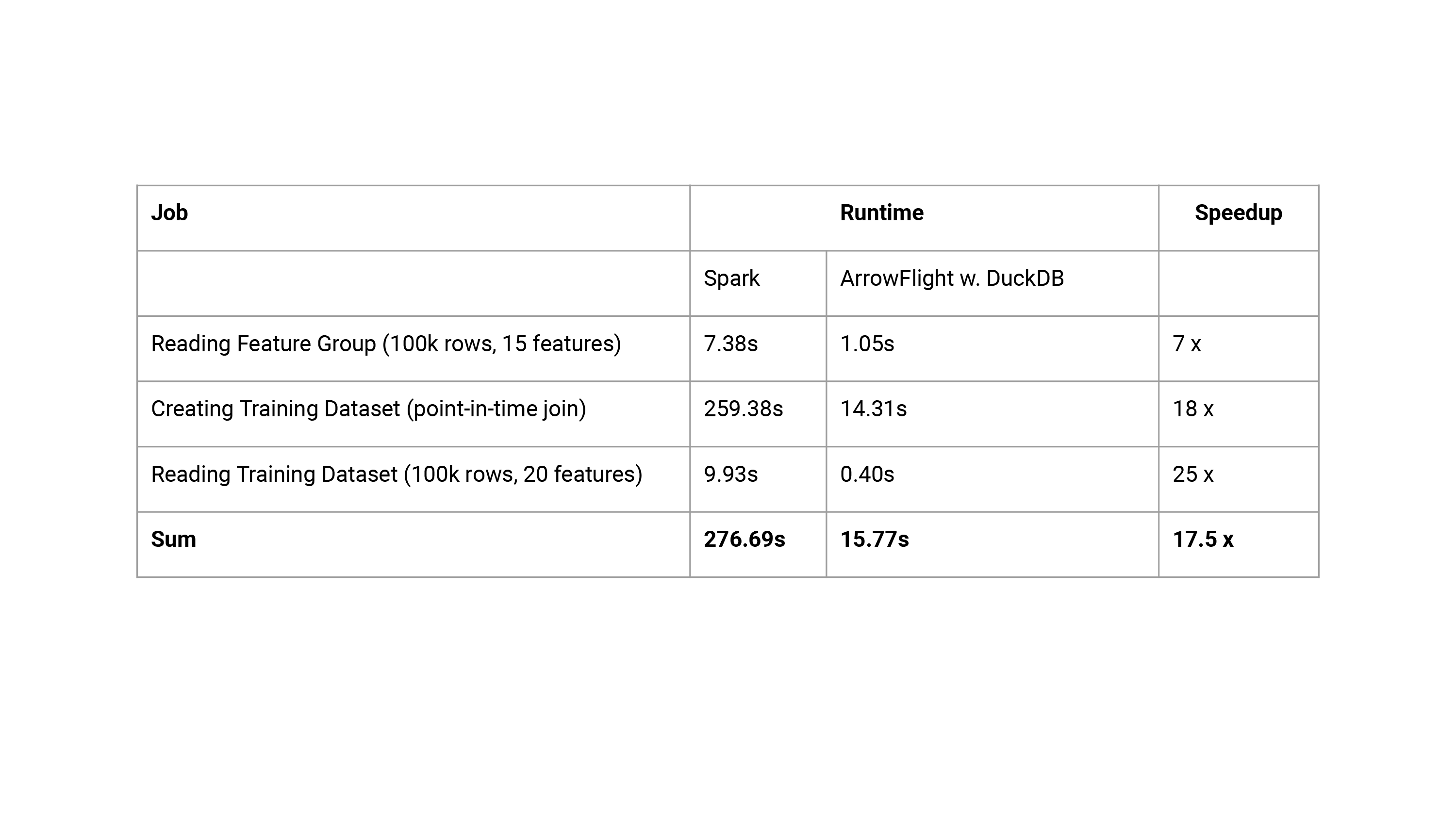
Table 3: Runtime numbers comparison on Hopsworks’ Fraud Batch Tutorial
Support for Other Offline Stores
We are soon going to add support for DuckDB reading from External Feature Groups (external tables in Snowflake, BigQuery, etc). This will include the support of creating point-in-time correct training datasets across Hudi Feature Groups and External Feature Groups.
PyArrow-backed Pandas 2.0 DataFrames
Arrow already supports zero-copy conversion from Arrow tables to Pandas 1.x DataFrames for a limited subset of types (foremost int and float types). Other types, such as strings, usually come with a minor runtime and memory overhead for the conversion (<10% end-to-end for an in-memory training dataset with 50M rows and 3 numeric, 2 string columns). With Pandas 2.0’s PyArrow-backed Pandas DataFrames this overhead can be fully alleviated. Since downstream libraries like scikit-learn do not fully support such types, yet, we will maintain support of regular Pandas types by default and offer PyArrow-backed DataFrames as an optional feature in the future.
Summary
This blog post introduces a new service in Hopsworks, ArrowFlight with DuckDB, which offers significant performance improvements for Python clients reading/writing with feature data. We chose to build a service rather than making our feature store clients heavier by embedding DuckDB and the drivers required to access the many different offline stores supported in Hopsworks. We showed in benchmarks up to 45X throughput improvements compared to existing feature stores, showing the value of working with Arrow data end-to-end, from the lakehouse to Pandas clients. We have built a bridge for Python-native access to Lakehouse Data in Hopsworks, and we hope it will enable Python developers to be more productive working with our feature store.