How to build your own Feature Store
We have many conversations with companies and organizations who are deciding between building their own feature store and buying one. We thought we would share our experience of building one.

As of May 2020, Hopsworks are the only vendor of a Feature Store for machine learning (ML) and the only maker of a fully open-source and cloud-native Feature Store for ML. As such, we have many conversations with companies and organizations who are deciding between building their own feature store and buying one. Given the increasing interest in building feature stores, we thought we would share our experience of building one and motivate some of the decisions and choices we took (and did not take) to help others who are considering following us down the same path.
8 Benefits of a Feature Store for ML
Here we list some of the reasons for wanting a feature store for ML in the first place.
1. Consistent Feature Engineering for Training Data and Serving
The feature store can eliminate the need for two different implementations for features: one when training a model and one when serving a model. With a feature store, you can have a single feature pipeline that computes the features and stores them into both an offline and online stores for use in both training models and serving models, respectively. The offline feature store needs to support large volumes of data for model training and for use by batch (analytical) applications for model scoring. The online store needs to support low latency access to features for models served in production.
2. Encourage Feature Reuse
Features should be reused between different models. In Twitter, they have a “sharing adoption” metric to evaluate the success of their feature store internally. The “sharing adoption” measures the number of teams that reuse in production models features created by other teams.
3. System support for Serving of Features
Operational models often need low latency access to features that may be computationally complex or generated from historical data. These types of features are often difficult or impossible to compute inside the applications themselves, either because of the lack of available data or because of the excessive time required to compute the features. The feature store can solve this problem by acting as a low-latency store for precomputed features for operational models (used by online applications).
4. Exploratory Data Analysis with a Feature Store
Data scientists can discover the available pre-computed features, the types of those features (numerical, categorical), their descriptive statistics , and the distribution of feature values. They can also view a small sample of feature values to help quickly identify any potential issues with using a given feature in a model.
5. Temporal Queries for Features
You would like to augment feature store queries with temporal logic. That is, you want to know the value of a given feature at:
- an instant in time (for example, when joining features together from different feature groups);
- a time interval - a length of time (for example, the last 3 months);
- a time period: an anchored duration of time (for example, training data for years 2012-2018, test data for 2019).
In relational databases, temporal queries are typically supported by a user-defined table that keeps a full history of data changes and allows easy point in time analysis, such as SQL Server. In scalable SQL systems, examples of columnar storage formats that support temporal queries are Apache Hudi and Delta Lake as well as streaming support in Apache Flink. These systems require increased storage (to store updates as well as the current values) for the ability to query the value of features at points in time, time intervals or time periods.
6. Security, Governance, and Tracking
The feature store is a central repository for an organization’s features enabling them to be access controlled, governed, and to have their usage tracked. The feature store also provides common standards for metadata, consistent documentation and coding standards for features. The repository can maintain popularity counts for features to show which ones are widely used which ones could potentially be removed, enabling better management of features.
7. Reproducibility for Training Datasets
The feature store should enable the re-creation of training datasets for given points-in-time to enable the reproducibility of models. An alternative to recreating training datasets is to archive them, but for many industries, such as healthcare and insurance, they will need to be reproducible for regulatory reasons. The ability to recreate training datasets for models is also useful for debugging models, even when you are not required by law to keep the training dataset.
8. Data Drift for Model Serving
The feature store can compute and store statistics over training datasets and make those statistics available to model serving platforms via API calls. In operational models, the training data statistics can then be compared with statistics computed over time windows of live data (last minute, hour, day) sent to the model for predictions. Simple (or complex) statistical tests can identify data drift - when live feature values diverge significantly from the model’s training data.
Feature Store Design Flow Chart
The feature store design flow chart below shows some of the decisions that need to be taken when deciding to roll your own feature store. This set of decisions is obviously not complete, and we omitted systems design issues that are commonly found in any scalable system, such as schema design, API design, language support, and platform support (on-premises, cloud-native).
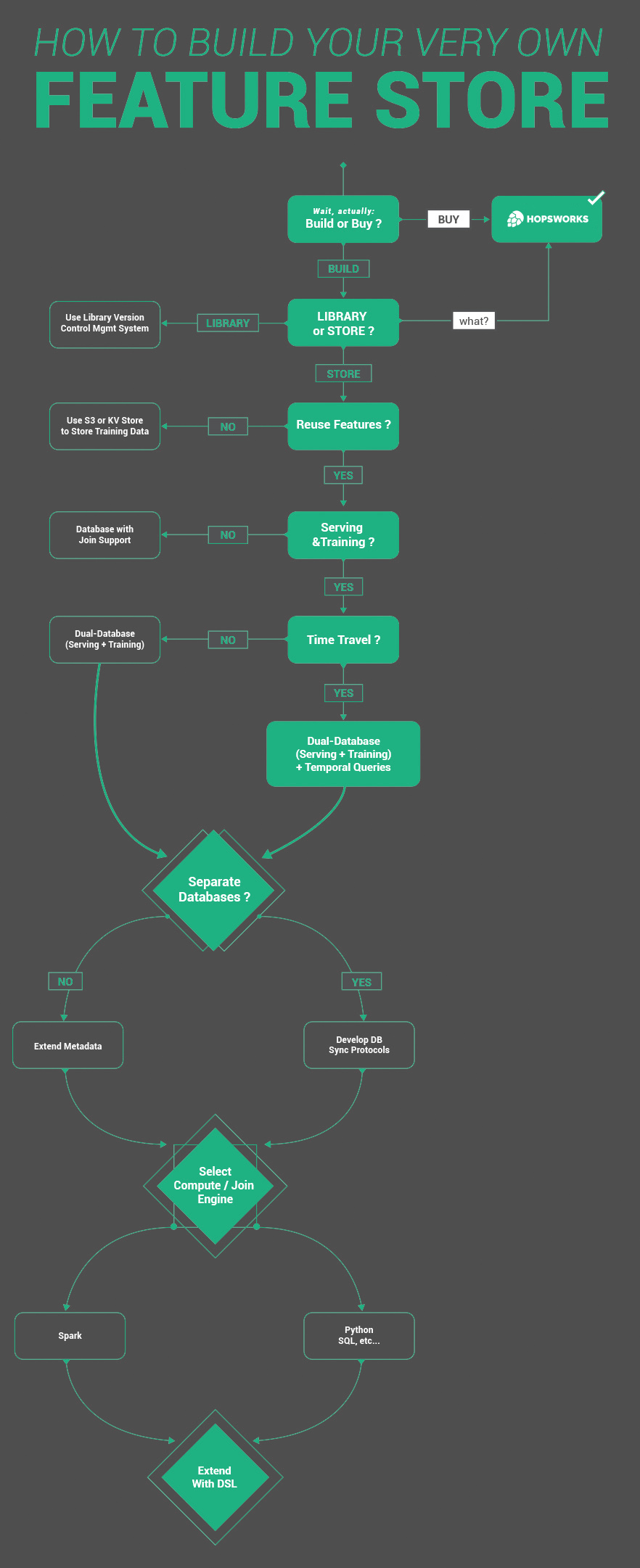
The first decision point is whether you really want to go ahead and build a data platform to support your ML efforts, knowing the considerable time it will take (at least 6-12 months before you will have anything production-ready) and the future costs of maintaining and updating your platform. If you decide that building a feature store is too much, then give us a shout - mention that Jim sent you and ask for the blog reader discount :)
If you still are determined to build one, you need to take your first big decision: is your feature store a library or a store (a materialized cache of your features)? If the only problem you want to solve is consistent features between training and serving, then the library approach may be suitable. In the library approach, you write your feature encoding functions in versioned libraries that are included in both training and serving pipelines. A downside to this is that both training and serving pipelines need to be implemented in the same (or compatible) programming languages. Another downside is that you may need to wait a long time to backfill training data, as you need to run a job to compute the features. Netflix’s early fact/feature store introduced shared, versioned feature encoders to ensure consistent feature engineering.
Your next decision is whether you want to reuse features across different models or not. Reusing features means you will need to join normalized features together to create training datasets and also when serving features. If you decide you do not want to reuse features, you will still be able to solve the problems of consistent feature engineering and system support for serving features. There are feature stores, like Condé Nest based on Cassandra, that have a single datastore used for storing training and serving features.
The next decision is consequential if you are only working with analytical models and not online (operational) models, you might decide you only need a single (scalable) database to store your features. Assuming you are a typical user who needs the feature store for both training and serving models, you then need to decide if you need support for time-travel queries. Many online models with windowed features (how many times a user did ‘X’ in the last 15 minutes) often need time-travel support to ensure consistent features for feature serving and creating training data. Assuming you decide to add time-travel support, you now need to build on a system with, or add application support for, temporal queries.
Your next decision also depends on your choice of data stores for the offline (scalable SQL) and online (low latency feature serving) stores. In Hopsworks, uniquely, we have a unified metadata layer for our file system, HopsFS, our feature serving layer, MySQL Cluster, and our scalable SQL layer, Apache Hive (-on-Hops). We could easily add extended metadata to our unified metadata layer to describe features, their statistics, and tag them. A CDC (change-data-capture) API to our unified metadata layer enabled us to also index feature descriptions in Elasticsearch, which supports free-text search and searches do not affect the performance of the unified metadata service. The bad news if you do not have unified metadata for your dual databases is that you need to design and develop agreement protocols to ensure that the 3 different systems are kept in sync, presenting a consistent view of your features: your offline, online, and feature metadata platforms. This is a tough distributed systems engineering challenge - good luck!
Finally, you need to decide on a compute engine (maybe internal or external to your platform) for both joining features to create training datasets, but also to compute your features. You may decide on a domain-specific language (like Michelangelo or Zipline) or a more general purpose language or framework like Python (Feast) or Spark (Hopsworks).
Apart from all these issues, you also need to decide on whether you need a UI to discover and manage features (Hopsworks, Michelangelo, Twitter, Zipline) or not (Feast). You also need to decide on whether you need to support multiple feature stores (such as development, production, and sensitive feature stores), and access control to those different feature stores (as in Hopsworks).
Phew! Finally you have navigated some of the decisions that you need to make to tailor your feature store platform for your needs. Although we have not covered the problem of API design to your feature store, we can confide that most feature store platforms have gone through more than one generation of API (we were not immune to that, either). So, good luck, give us a call if you decide to buy rather than build.