MLOps with a Feature Store
This blog introduces platforms and methods for continuous integration (CI), delivery (CD), and training (CT) with ML platforms, with details on how to do CI/CD MLOps with a Feature Store.

What is Machine Learning Operations?
MLOps is a recent term that describes how to apply DevOps principles to automating the building, testing, and deployment of ML systems. The Continuous Delivery Foundation’s SIG-MLOps defines MLOps as “the extension of the DevOps methodology to include Machine Learning and Data Science assets as first class citizens within the DevOps ecology”. MLOps aims to unify ML application development and the operation of ML applications, making it easier for teams to deploy better models more frequently. Martinfowler.com defines MLOps as:
“a software engineering approach in which a cross-functional team produces machine learning applications based on code, data, and models in small and safe increments that can be reproduced and reliably released at any time, in short adaptation cycles.”
Some of the major challenges of MLOps, compared to DevOps, is how to deal with versioned data, not just versioned code, how to manage specialized hardware (graphical processing units (GPUs)), and how to manage data governance and compliance for models.
DevOps vs MLOps
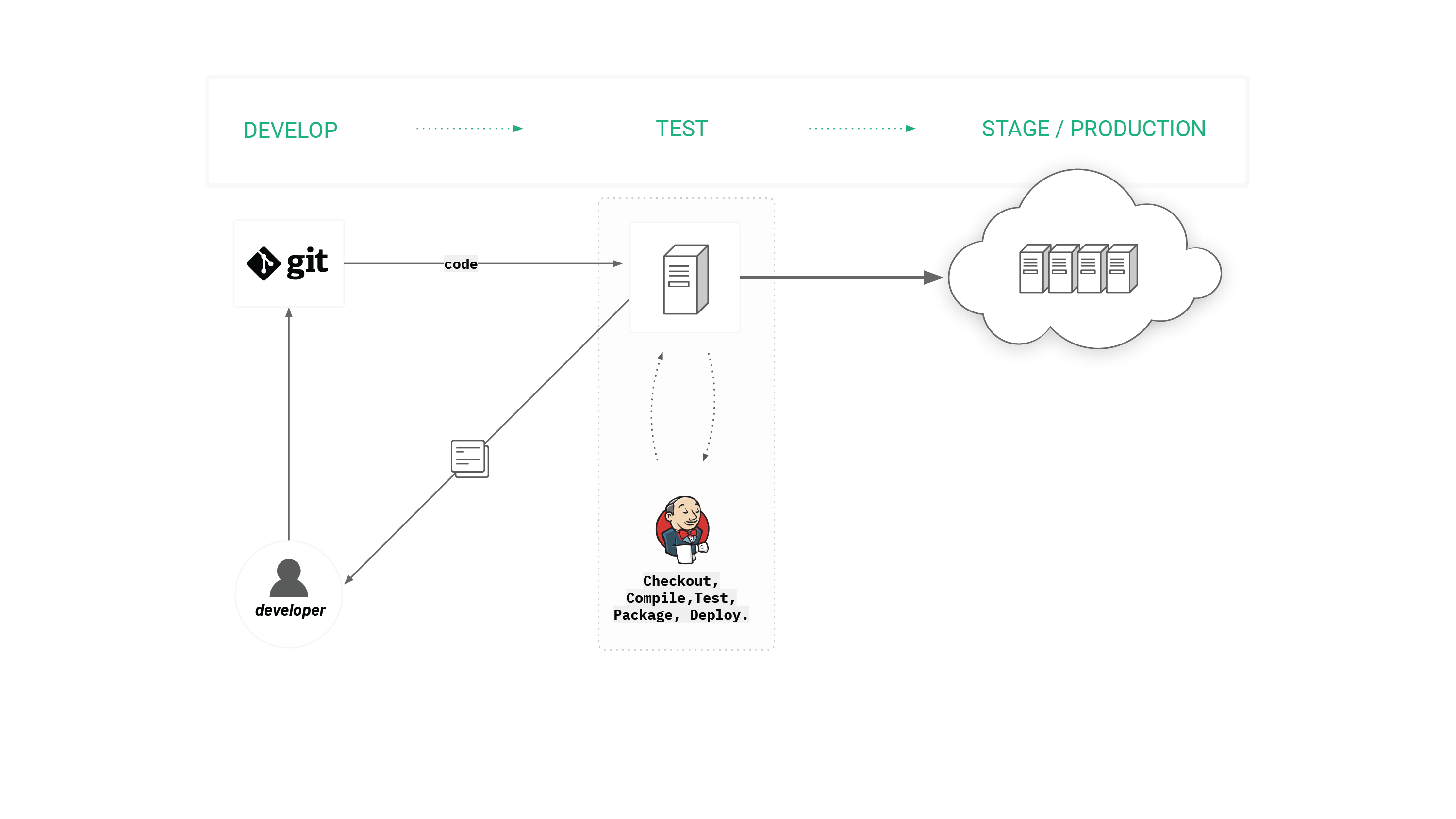
Figure 1. Traditional DevOps CI/CD Workflow triggered by changes to source code.
Git is the world’s most popular source-code version control system. It is used to track changes in source code over time and to support different versions of source code. Support for version control is a prerequisite for automation and continuous integration (CI) solutions as it enables reproducible provisioning of any environment in a fully automated fashion. That is, we assume the configuration information required to provision the environment is stored in a version control system, as well as the source code for the system we will be testing. Typically, when working with DevOps, every commit to Git triggers the automated creation of packages that can be deployed to any environment using only information in version control.
In most DevOps setups, Jenkins is used together with Git as an automation server that builds, tests and deploys your versioned code in a controlled and predictable way. The typical steps Jenkins follows for a CI/CD pipeline is to: provision testing virtual machines (VMs)/containers, checkout code onto machines, compile the code, run tests, package binaries, and deploy binaries. For Java, this involves running a build tool like maven to compile, test, and package Java binaries before deploying the binaries in some staging or production system. For Docker, this means compiling a Dockerfile and deploying the Docker image to a Docker registry.
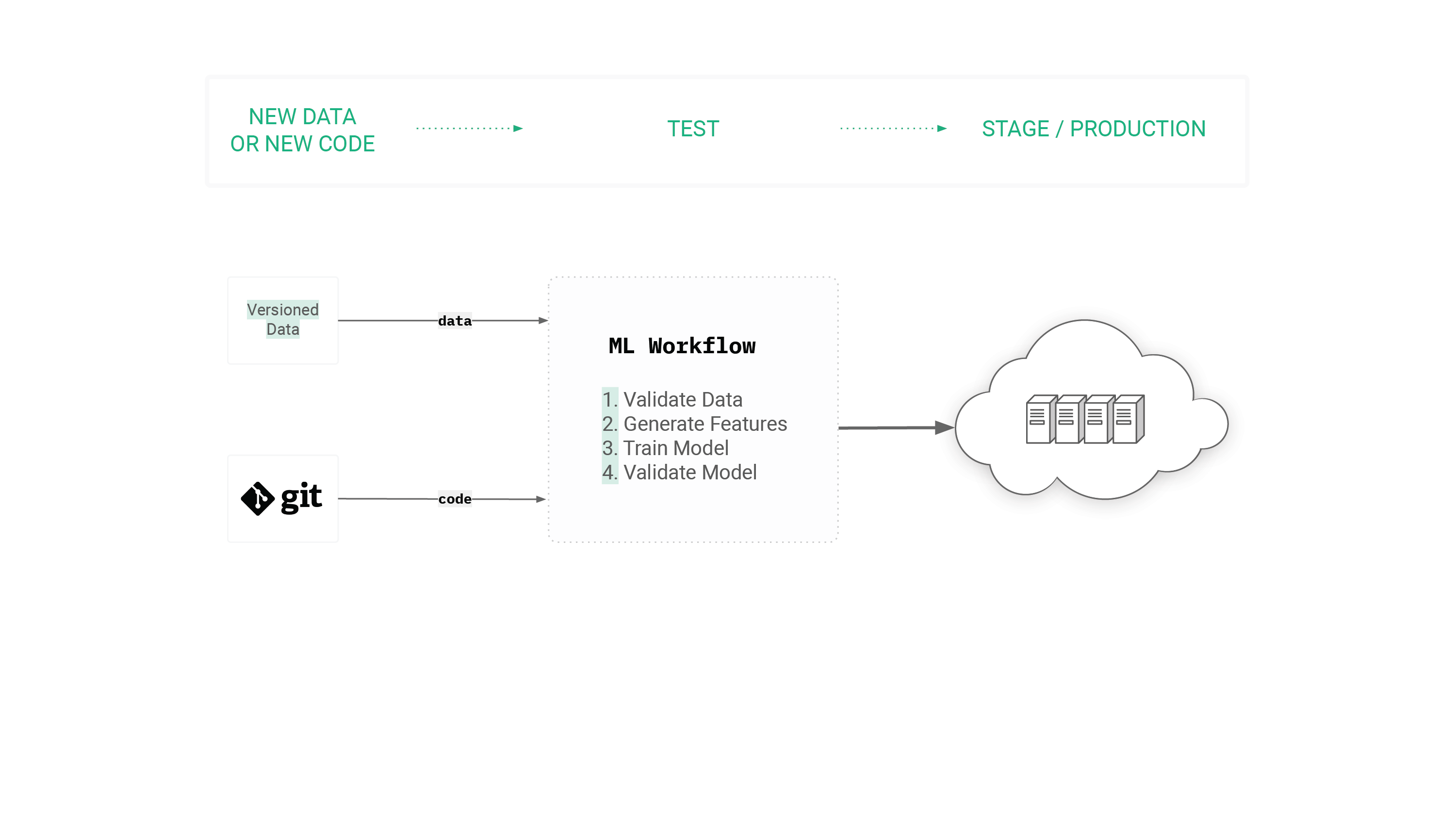
Figure 2. High Level MLOps CI/CD Workflow triggered by changes in either source code or data.
Perhaps the most defining characteristic of MLOps is the need to version data as well as code to enable reproducible workflows for training models. Git is not suitable as a platform for versioning data, as it does not scale to store large volumes of data. Luckily, others have been working on alternative platforms in recent years.
However, Git and Jenkins are not enough for MLOps, where the build process involves running a complex distributed workflow and we need both versioned code and versioned data to ensure reproducible automated builds. The workflow is what we call a Machine Learning pipeline, a graph of components, where each component takes input parameters and data, and at the end, a successful workflow run deploys a trained model to production. A standard ML pipeline consists of at least the following components: validate incoming data, compute features on the incoming data, generate train/test data, train the model, validate the model, deploy the model, and monitor the model in production. This simplified pipeline can, in practice, be even more complex, where the model training stage can be broken into smaller components: hyperparameter tuning, ablation studies, and distributed training.
There are many already several end-to-end ML frameworks that support orchestration frameworks to run ML pipelines: TensorFlow Extended (TFX) supports Airflow, Beam and Kubeflow pipelines, Hopsworks supports Airflow, MLFlow supports Spark, and Kubeflow supports Kubeflow pipelines. These frameworks enable the automated execution of workflows, the ability to repeat steps, such as re-training a model, with only input parameter changes, the ability to pass data between components, and the ability to specify event-based triggering of workflows (e.g., at a specific time of day, on the arrival of new data, or when model performance degrades below a given level). TFX, MLFlow, and Hopsworks also support distributed processing using Beam and/or Spark, enabling scale-out execution on clusters using very large amounts of data.
MLOps: versioned Code and Data
Data Versioning, Git-Style
DVC, developed by the affable Dmitry Petrov, provides an open-source tool for versioning files/objects in cloud storage that uses Git to store metadata about files and reflinks (that support transparent copy-on-write for data files) to ensure consistency between git entries and the data files. Similarly, Pachyderm, a ML platform on Kubernetes, also provides a data versioning platform using git-like semantics. However, these git-like approaches just track immutable files, they do not store the differences between files. They cannot handle time-travel queries, such as “give me train/test data for the range between the years 2016-2018” or “give me the value of these features on the 6th September 2018”. Without time-travel, they cannot support incremental feature engineering: compute features only on the data that has changed since the last time run (1 hour ago, a day ago, etc).
Data Versioning with Time-Travel Queries and Incremental Pulling
An alternative to git-like data versioning systems is to use a transactional data-lake that provides versioned, structured datasets. A versioned dataset does not just have a version of the schema for its data (schemas may evolve over time), but also updates to the data-lake are executed atomically and identified by a commit. The most well known such platforms are the open-source projects: Delta Lake, Apache Hudi, Apache Iceberg. Here users can perform time-travel queries that return the data at a given point-in-time (commit-id), or the data for a given time-interval, or the changes to the data since a given point in time. They execute time travel queries efficiently using indexes (bloom filters, z-indexes, data-skipping indexes) that massively reduce the amount of data that needs to be read from the file system or object store. Transactional data lakes also enable incremental feature engineering - compute features only for the data that has changed in the last hour or day - by enabling clients to read only those changes in a dataset since a given point in time.
Hopsworks Feature Store
The Feature Store for machine learning is a feature computation and storage service that enables features to be registered, discovered, and used both as part of ML pipelines as well as by online applications for model inferencing.
Feature Stores are typically required to store both large volumes of feature data and provide low latency access to features for online applications. As such, they are typically implemented as a dual-database system: a low latency online feature store (typically a key-value store or real-time database) and a scale-out SQL database to store large volumes of feature data for training and batch applications.
The online feature store enables online applications to enrich feature vectors with near real-time feature data before performing inference requests. The offline feature store can store large volumes of feature data that is used to create train/test data for model development or by batch applications for model scoring.
The Feature Store solves the following problems in pipelines for machine learning:
- reuse of feature pipelines by sharing features between teams/projects;
- enables the serving of features at scale and with low latency;
- ensures the consistency of features between training and serving - features are engineered once and can be cached in both the Online and Offline Feature Stores;
- ensures point-in-time correctness for featuress - when a prediction was made and an outcome arrives later, we need to be able to query the values of different features at a given point in time in the past.
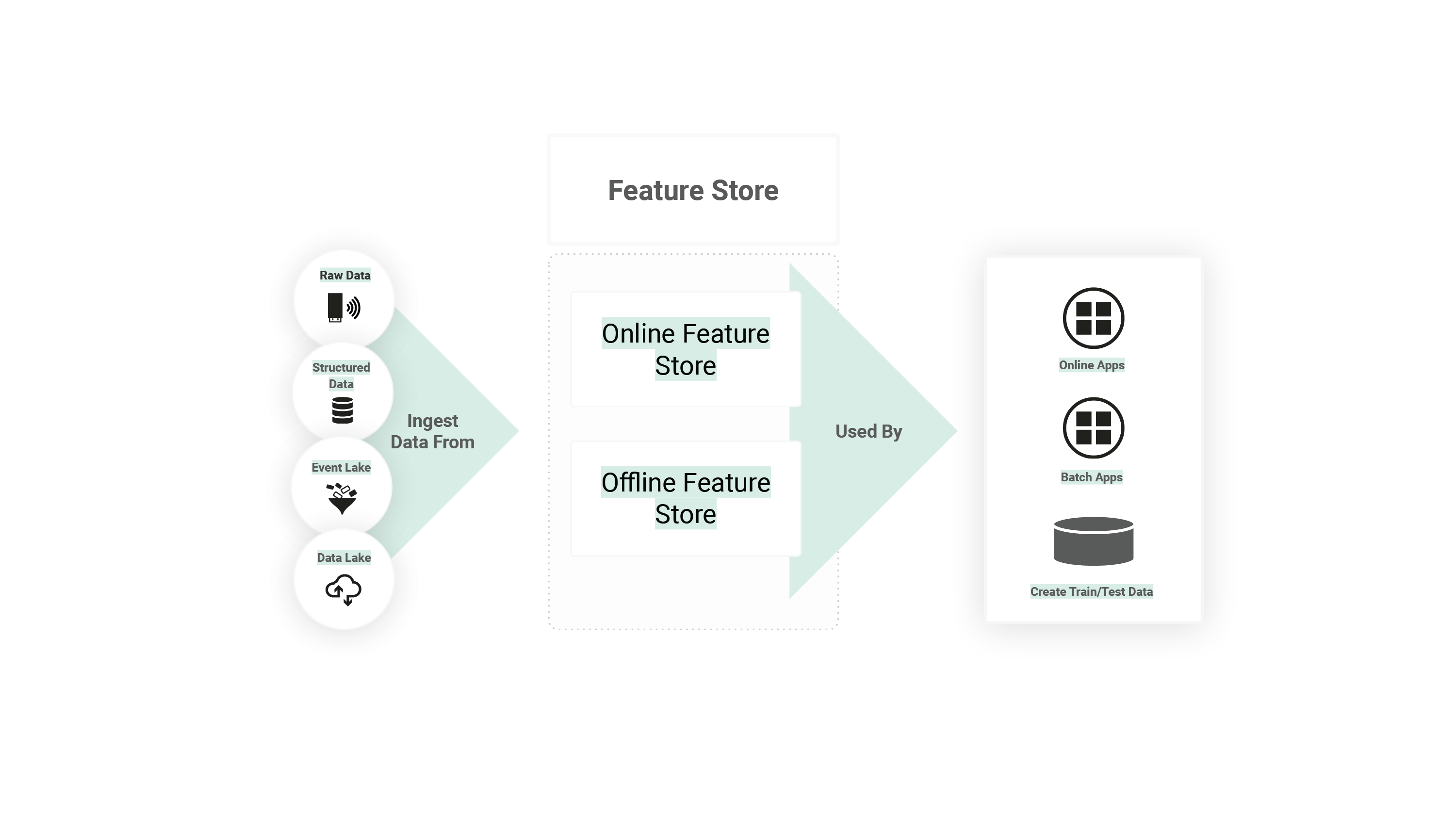
Figure 3. The Feature Store for ML consists of both an Online and Offline database and transforms raw data from backend systems into engineered features that are made available to online and batch applications for inferencing and to Data Scientists to create train/test data for model development.
Most hyperscale AI companies have built internal feature stores (Uber, Twitter, AirBnb, Google, Facebook, Netflix, Comcast), but there are also two open-source Feature Stores: Hopsworks Feature Store (built on Apache Hudi/Hive, MySQL Cluster and HopsFS) and Feast (built on Big Query, BigTable, and Redis). Other databases used by existing Feature Stores include Cassandra, S3, and Kafka, and custom key-value stores.
End-to-End ML Pipelines with the Hopsworks Feature Store
Both MLOps and DataOps CI/CD pipelines differ from traditional DevOps in that they may be triggered by new data arriving for processing (as well as triggering due to updates to the source code for the data engineering or model training pipelines). DataOps is concerned with automating test and deployment of data processing pipelines (or feature pipelines, in our case), with stages such as data validation and data pipelines. MLOps, on the other hand, is concerned with the automation of training and deploying production ML models, with stages such as model training, model validation, and model deployment.
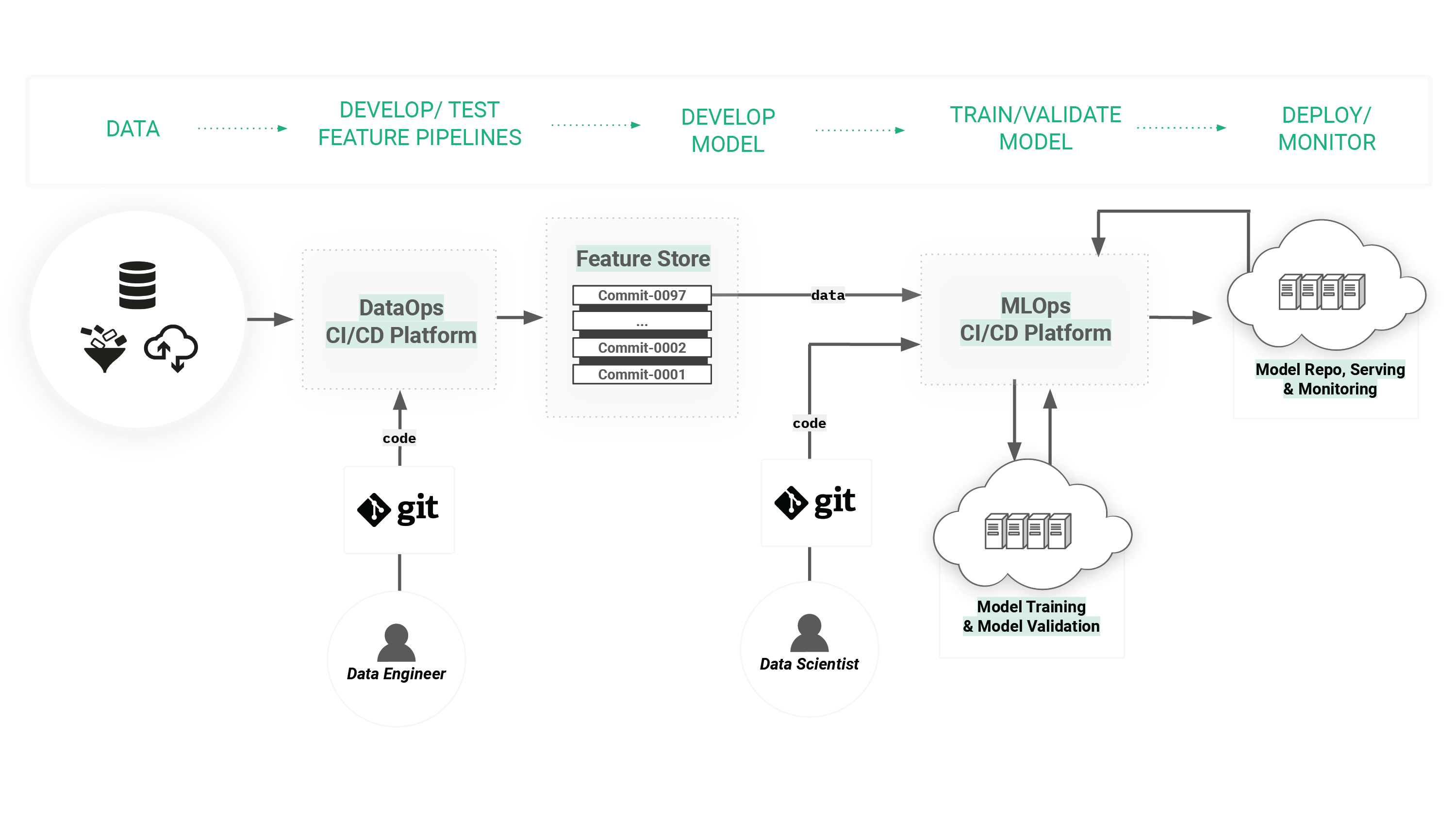
Figure 4. The Feature Store enables ML workflows to be decomposed into two workflows: (1) a “DataOps” workflow for engineering features and validating incoming data that caches the features in the Feature Store, and (2) a “MLOps” workflow for training models using features from the Feature Store, analyzing and validating those models, deploying them into online model serving infrastructure, and monitoring model performance in production.
Some ML lifecycle frameworks, such as TensorFlow Extended (TFX) and MLFlow, are based around end-to-end ML pipelines that start with raw data and end in production models. However, the first steps of an end-to-end ML pipeline, that take raw data and turn it into training data for models can be very expensive. According to Airbnb, without a feature store, creating train/test data can take up to 60-80% of data scientists time.
The feature store enables transformed data (features) to be reused in different models. When you have a feature store, you no longer need end-to-end ML pipelines from raw data to models. You can decompose end-to-end ML pipelines into two separate pipelines that each run at their own cadence: (1) feature pipelines that ingest data from backend systems, validate it, featurize it and cache it in the feature store, and (2) training pipelines that train models from feature data, validate those models, and deploy them to production.
The motivation for introducing the Feature Store for MLOps is that the process for ingesting and featurizing new data is separate from the process for training models using features that come from potentially many different sources. That is, there are often differences in the cadence for feature engineering compared to the cadence for model training. Some features may be updated every few seconds, while others are updated every few months. Models, on the other hand, can be trained on demand, regularly (every day or every week, for example), or when monitoring shows a model’s performance has degraded. Feature engineering pipelines are typically triggered at regular intervals when new data arrives or on-demand when source code is pushed to git because changes were made in how features are engineered.
ML Pipelines are Stateful
The best practice when developing data pipelines is for them to be stateless and idempotent, so that they can be safely re-run in case of failures. ML pipelines, however, have state. Before you deploy a model to production, you need some contextual information - does this model perform better than the currently deployed model? This decision requires state about the currently deployed model. Ideally, we also want historical state, so we can observe and evaluate the performance of models over time and the processing time/success-rate of building models over time. Hopsworks, TFX and MLFlow provide a metadata store to enable ML pipelines to make stateful decisions, to log their execution steps, store the artifacts they produce, and store the provenance of the final models.
Both TFX and MLFlow are obtrusive - they make developers re-write the code at each of the stages with their component models (with well-defined inputs and outputs to each stage). This way, they can intercept input parameters to components and log them to the metadata store. Hopsworks provides an inobtrusive metadata model, where pipelines read/write to the HopsFS (HDFS) file system and use Hopsworks APIs to interact with its feature store. This way, metadata events, artifacts, executions, and provenance are implicitly stored to the metadata store without the need to rewrite notebooks or python programs, as is needed in TFX or MLFlow.
Feature Pipelines feed the Hopsworks Feature Store
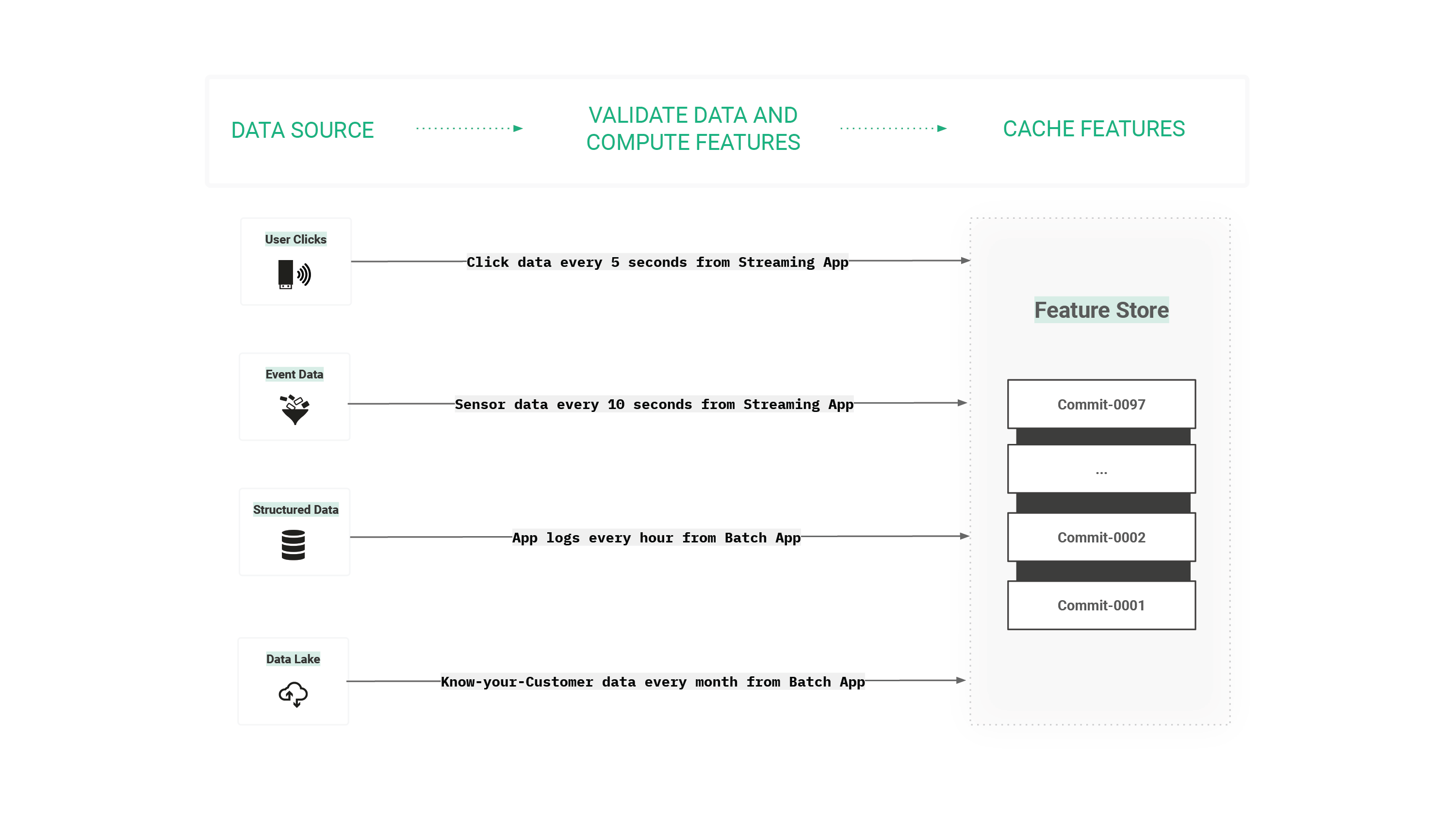
Figure 5. Feature pipelines have a natural cadence for each data source, and the cached features can be reused by many downstream model training pipelines.
The feature store enables feature pipelines to cache feature data for use by many downstream model training pipelines, reducing the time to create/backfill features. Groups of features are often computed together and have their own natural ingestion cadence, see figure above. Real-time features may be updated in the online feature store every few seconds using a streaming application, while batch features could be updated hourly, daily, weekly, or monthly.
In practice, feature pipelines are data pipelines, where the output is cleaned, validated, featurized data. As there are typically no guarantees on the correctness of the incoming data, input data must be validated and any missing values must be handled (often by either imputing them or ignoring them). Two popular frameworks for data validation are TFX data validation and AWS Deequ, as they allow you to extend traditional schema-based support for validating data (e.g., this column should contain integers) with data validation rules for checking if numerical or categorical values are as expected. For example, while a schema ensures that a numerical feature is of type float, additional validation rules are needed to ensure those floats lie within an expected range. You can also check to ensure a columns’ values are unique, not null, that its descriptive statistics are within certain ranges. Validated data is then transformed into numeric and categorical features that are then cached in the feature store, and subsequently used both to train models and for batch/online model inferencing.
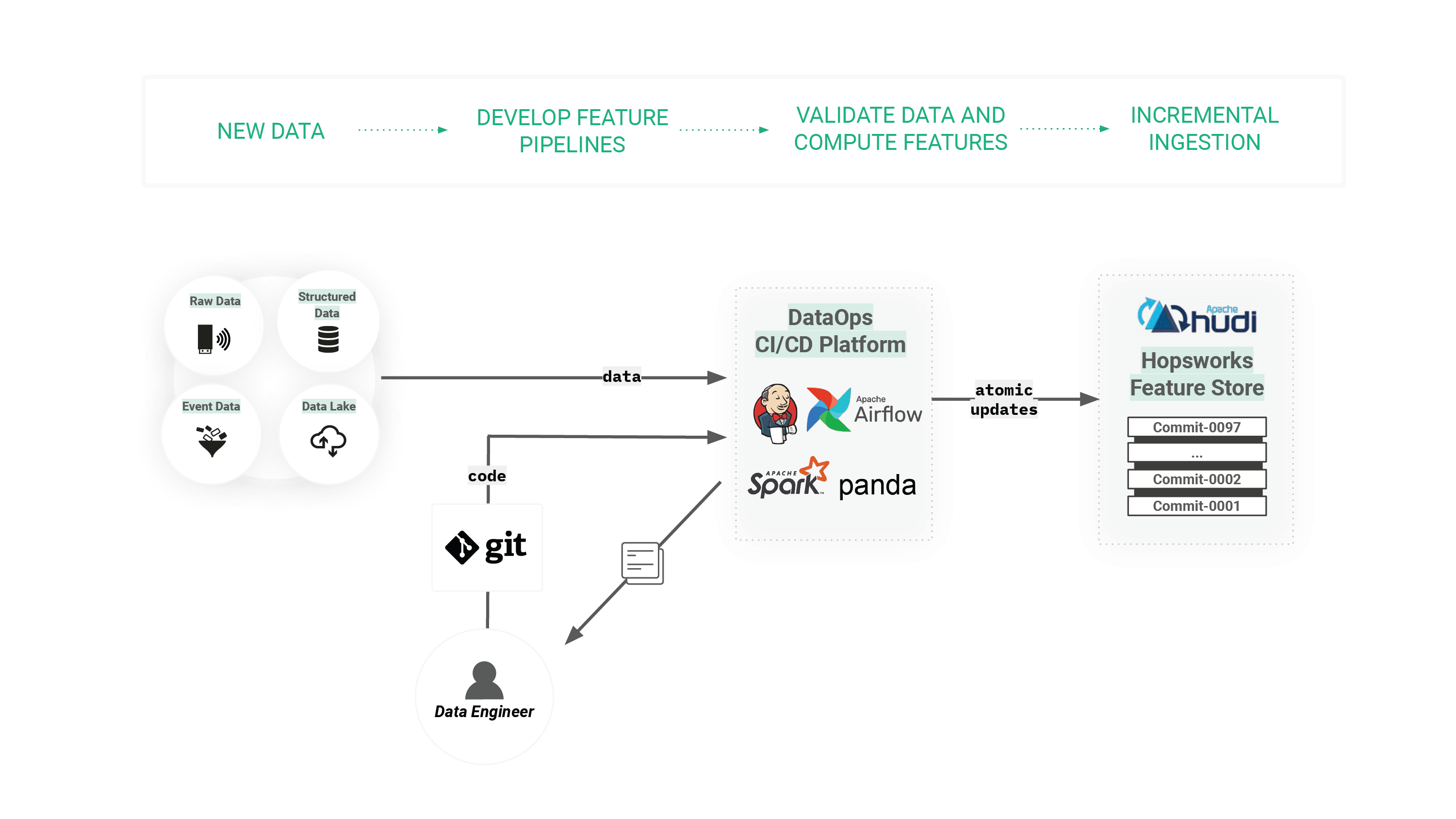
Figure 6. Feature Pipelines belong to the DataOps paradigm, where frameworks like Spark, PySpark, Pandas, and Featuretools are used along with data validation libraries like TFX data validation and Deequ.
Feature pipelines share many of the same best-practice DevOps practices with data pipelines. Some of the types of automated tests for data/features, include:
- unit test and integration tests for all featurization code (Jenkins can run these tests when code is pushed to Git);
- test that feature values fall within expected ranges (TFX data validation or Deequ);
- test the uniqueness, completeness, and distinctness of features (Deequ);
- test that feature distributions match your expectations (TFX data validation or Deequ);
- test the relationship between each feature and the label, and the pairwise correlations between individual signals (Deequ);
- test the cost of each feature (custom tests);
- test that personally identifiable information is not leaking into features (custom tests).
When a feature store is available, the output of feature pipelines is cached feature data, stored in the feature store. Ideally, the destination data sink will have support for versioned data, such as in Apache Hudi in Hopsworks Feature Store. In Hopsworks, feature pipelines upsert (insert or update) data into existing feature groups, where a feature group is a set of features computed together (typically because they come from the same backend system and are related by some entity or key). Every time a feature pipeline runs for a feature group, it creates a new commit in the sink Hudi dataset. This way, we can track and query different commits to feature groups in the Feature Store, and monitor changes to statistics of ingested data over time.
MLOps: Model Training Pipelines start at the Feature Store
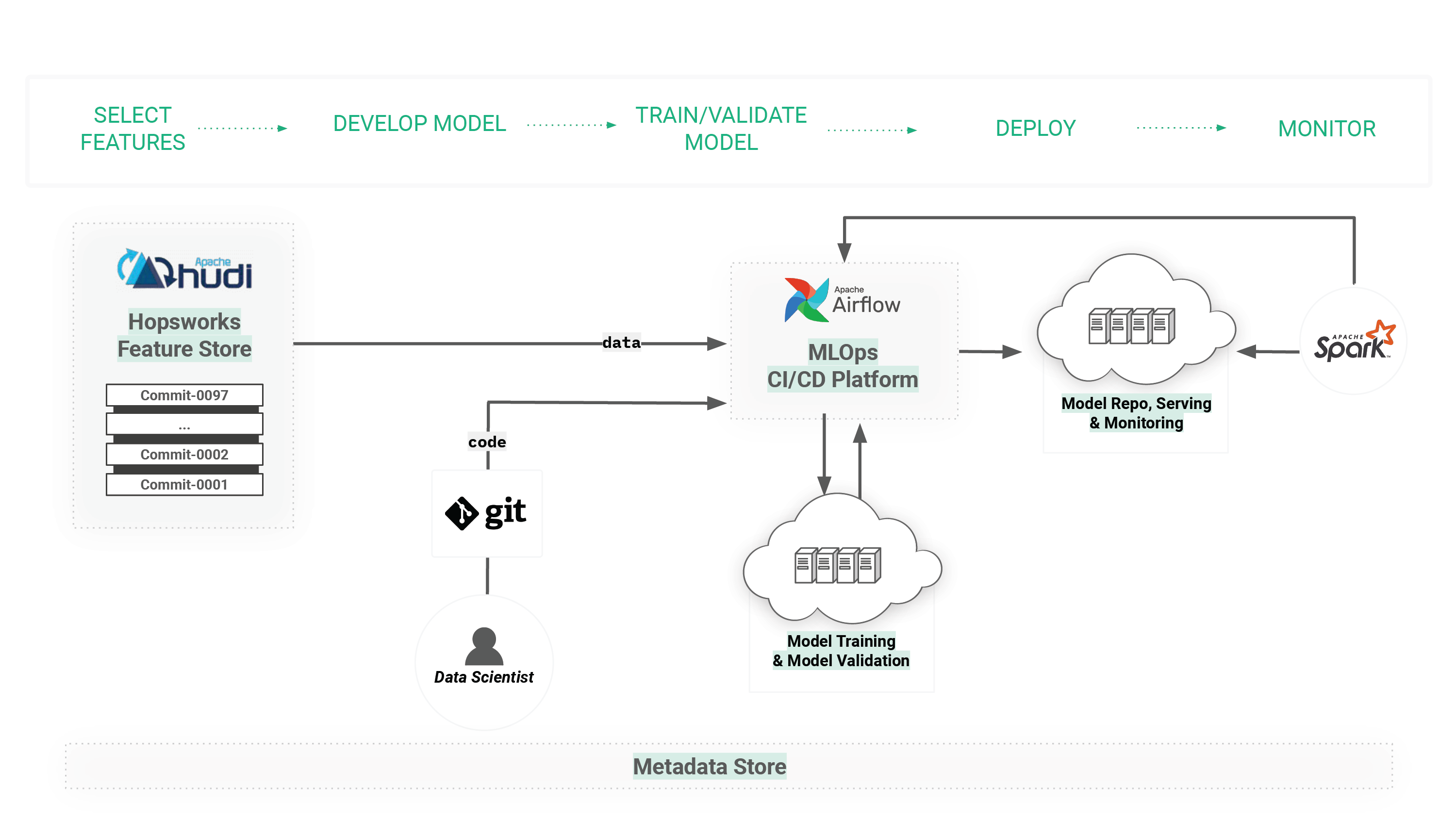
Figure 7. Model training pipelines belong to the MLOps paradigm, where versioned features are read from Apache Hudi in the Hopsworks Feature Store to create train/test data that is used to train models that are then deployed and monitored in production. Provenance of ML artifacts and executions are stored in the Metadata store in Hopsworks, and ML pipelines are orchestrated by Hopsworks.
Model training with a feature store typically involves at least three stages (or programs) in a workflow:
- select the features to include, the file format, and the file system (or object store) for the train/test dataset that will be created from features in the feature store. Note that for Hopsworks Feature store, a timestamp (corresponding to Hudi commit-ids), can also be supplied to reproduce a train/test dataset exactly as it was at a point of time in the past;
- train the model using the training dataset created in step 1 (training can be further decomposed into the following steps: hyperparameter optimization, ablation study, and model training);
- validate the model using automated tests and deploy it to a model registry for batch applications and/or an online model server for online applications.
In the Hopsworks platform, these three steps would typically be python programs or Jupyter notebooks and they are executed as part of an Airflow DAG (directed acyclic graph). That is, Airflow orchestrates the execution of the pipeline. Airflow enables DAGs to be scheduled periodically, but it can also be configured to run workflows when new feature data arrives in the feature store or when Git commits are pushed for model training pipeline code.
The type of automated tests that are performed during the model validation step include:
- test how the model performs on different data slices to check for bias,
- test the robustness of the model to out-of-distribution feature vectors.
Hopsworks supports Google’s What-If Tool for model analysis using Jupyter notebooks. It is useful to investigate counterfactuals (compare a datapoint to the most similar point where your model predicts a different result), making it easier to develop model validation tests that can subsequently be used in production pipelines.
Google’s What-If Tool can be used to analyze a model, asking counterfactuals and testing for bias on different slices of data. Knowledge discovered here can be transferred into model validation tests.
Monitoring Online Models
When a model is deployed to a model server for use by online applications, we need to monitor its performance and its input features. We need to identify if the input features in production are statistically different from the input features used to train the model. In practice, we can do this by comparing statistics computed over the training data (accessible through feature store API calls) with statistics collected from input features at runtime. In Hopsworks, we log all prediction requests sent to models to a topic in Kafka. You can then write a Spark Streaming or Flink application that processes the prediction requests in Kafka, computing statistics in time-based windows and comparing those statistics with the training data statistics from the Feature Store. If the time-based windows statistics for a given feature diverge significantly from the training statistics, your streaming application can notify ML engineers that input features are not as expected. Your streaming application will typically also compute business-level KPIs for the models and provide a UI to enable operators to visualize model performance. More concretely, the error signals to look for in online monitoring include:
Concept drift
In a model, the target variable is what the model is trying to predict. It could be, for example, if a financial transaction is suspected as fraud or not fraud. When the statistical properties of a model change over time in an unexpected way (for example, a new fraud scheme appears that increases the overall amount of fraud), we have concept drift.
Data drift
If, however, the statistical properties of the input features change over time in an unexpected way, it will negatively impact the model’s performance. For example, if users execute many more financial transactions than normal due to it being a holiday period, but the model was not trained to handle holiday periods, then the model performance may degrade (either missing fraud or flagging up too many transactions as suspicious).
Feature pipeline changes
If there are changes in how a feature is computed in a feature pipeline, and an online model enriches its feature vector with that feature data from the online feature store, then this can negatively impact the model’s performance. For example, if you change how to compute the number of transactions a user carries out, it may negatively impact the model’s performance.
Summary
We have now covered an End-to-End ML pipeline with a Feature Store based on MLOps principles. Updates to pipeline code or newly arrived data enable changes to be continuously tested and models to be continually updated and deployed in production. We showed how the Feature Store enables monolithic end-to-end ML pipelines to be decomposed into feature pipelines and model training pipelines. We also discussed how data versioning is possible with modern data lake frameworks such as Apache Hudi. In the next blog, we will cover ML pipelines and reproducible experiments in Hopsworks in more detail, and how to easily move pipelines from development to production environments. We will also show how to develop both feature pipelines and model training pipelines using Airflow.