Feature Engineering with Apache Airflow
Unlock the power of Apache Airflow in the context of feature engineering. We will delve into building a feature pipeline using Airflow, focusing on two tasks: feature binning and aggregations.

Introduction
Feature engineering is a critical aspect of building robust and accurate machine learning models. It involves transforming raw data into meaningful features that capture the underlying patterns and relationships in the data. However, performing feature engineering efficiently and at scale can be challenging, especially when dealing with large datasets and complex transformations.
In this article, we explore the power of Apache Airflow, a popular open-source platform for workflow orchestration, in the context of feature engineering. We will delve into building a feature pipeline using Apache Airflow, focusing on two tasks: feature binning and aggregations. Feature binning allows us to discretize continuous features into bins, enabling better modeling of non-linear relationships. Aggregations, on the other hand, help summarize and condense data by grouping and computing statistical measures.
By leveraging Apache Airflow's capabilities, we can orchestrate and automate the feature engineering process, ensuring reproducibility and consistency. We will also explore how to seamlessly integrate the resulting features into a feature store, a centralized repository for storing and serving feature data. Each stage, from gathering data to storing the features in the feature store, is carried out as a task within the Airflow DAG. The code for this article can be found here.
What are the capabilities of Apache Airflow
Apache Airflow is an open-source platform used for orchestrating complex workflows and data processing pipelines. It provides several powerful features that make it a popular choice for managing and scheduling workflows in various data engineering and data science tasks. Some of the key features of Apache Airflow include:
- Directed Acyclic Graph (DAG) Based: Airflow uses Directed Acyclic Graphs (DAGs) to represent workflows. A DAG is a collection of tasks with defined dependencies, allowing users to visualize and understand the workflow structure easily.
- Extensibility and Custom Operators: Airflow provides a rich ecosystem of pre-built operators for common tasks like executing SQL queries, transferring files, and running Python scripts. Additionally, users can create their custom operators to integrate with any external system or execute specific tasks.
- Scalability: Airflow can scale to handle large-scale workflows making it suitable for enterprise-level data processing.
- Parallelism: Airflow can execute tasks in parallel, thereby optimizing the workflow execution and reducing the overall processing time.
- Task Dependency and Scheduling: Airflow allows users to define dependencies between tasks, ensuring that tasks are executed in the correct order. Users can schedule workflows to run at specified intervals or based on specific triggers.
- Monitoring and Logging: Airflow provides a web-based UI for monitoring the progress of workflows, inspecting logs, and understanding the status of tasks.
- Retry and Error Handling: Airflow supports task retries and error handling mechanisms, ensuring robustness and fault tolerance in workflows.
- Community and Third-Party Integrations: Airflow has a large and active community, continuously contributing to its growth and improvement. It also integrates with various third-party tools, allowing users to extend its functionality further.
In summary, Apache Airflow provides a comprehensive set of features for orchestrating complex data workflows. Its DAG-based design, extensibility, scalability, and integration capabilities make it a popular choice among data engineers and data scientists for managing data pipelines and workflows in modern data-driven applications.
Hopsworks and Apache Airflow Integration: Enhancing Data Workflows
Hopsworks and Apache Airflow, when combined, create a potent synergy that optimizes the end-to-end process of managing, scheduling, and orchestrating complex data workflows. Let's delve into how these two platforms collaborate to streamline data operations:
- Workflow Orchestration: Airflow excels in orchestrating complex workflows with dependencies and scheduling tasks. By incorporating Airflow into the Hopsworks ecosystem, you can automate the processes of data collection, feature selection, feature engineering and storing the features to the feature store. Airflow's DAG (Directed Acyclic Graph) structure enables you to define the sequence of tasks and their dependencies, ensuring that data operations are executed in the desired order and time frame.
- End-to-End Monitoring and Logging: Both Hopsworks and Airflow offer comprehensive monitoring and logging capabilities. When used together, you gain a holistic view of your data pipelines. You can monitor the progress of tasks, track execution times, and receive alerts for potential issues. This integrated monitoring enhances visibility, allowing you to proactively address any challenges that may arise during the workflow execution.
- Data Lineage and Governance: Hopsworks emphasizes data governance and lineage tracking. By integrating with Airflow, you can capture lineage information for tasks orchestrated by Airflow. This integration enhances data traceability and transparency, which are crucial aspects for compliance, auditing, and troubleshooting. The integration of Hopsworks and Apache Airflow creates a powerful ecosystem for managing end-to-end data workflows. By leveraging the strengths of both platforms, organizations can achieve streamlined data operations, optimal resource utilization, and enhanced collaboration among data engineers, data scientists, and other stakeholders.
Understanding the data
In this article, we are using the North Carolina Voter Stats dataset. This dataset contains voter information based on election dates. Which means there will be a file for each election date. Each file contains the following features.
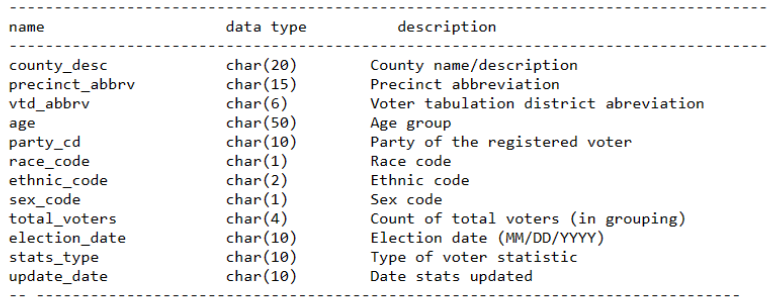
Figure 1: Features with data types and description
For the sake of brevity in the demonstration, the following features are used: party_cd, county_desc, race_code, age, sex_code, ethnic_code and total_voters.
party_cd: This feature denotes the party of the registered voter. The available parties are DEM (DEMOCRATIC), LIB (LIBERTARIAN), REP (REPUBLICAN), and UNA (UNAFFILIATED). They are categorized into REP, DEM, and Others.
county_desc: This feature denotes the County name of the registered voter. There are 100 counties in the state of North Carolina. Since this feature is a categorical variable we perform label encoding. The code for each county can be found here.
race_code: This feature denotes the Race code of the registered voter. The available race codes are A (ASIAN), B (BLACK or AFRICAN AMERICAN), I (INDIAN AMERICAN or ALASKA NATIVE), M (TWO or MORE RACES), O (OTHER), U (UNDESIGNATED), W (WHITE). These features are label encoded into W, B, A, I, and Others.
age: This feature denotes the age group of the registered voter. The available age groups are: Age < 18 Or Invalid Birth Dates, Age 18 - 25, Age 26 - 40, Age 41 - 65, Age Over 66. They are encoded with the same name.
sex_code: This feature denotes the sex code of the registered voter. The available sex codes are F (FEMALE), M (MALE), and U (UNDESIGNATED). They are label encoded into F, M, and Others.
ethnic_code: This feature denotes the ethnic code of the registered voter. The available ethnic codes are HL (HISPANIC or LATINO), NL (NOT HISPANIC or NOT LATINO), and UN (UNDESIGNATED). They are encoded into HL, NL, and Others.
total_voters: This feature denotes the count of total voters. This is a numerical variable.
Apache Airflow specifics
In this section, we explore key Apache Airflow concepts and functionalities that are essential for building robust and scalable data workflows. You will learn about defining DAGs, leveraging operators, utilizing XCom for data communication, and establishing task dependencies to orchestrate complex data processing pipelines efficiently.
Defining a DAG
Whenever we define a DAG in airflow we need to import the DAG object, instantiate the DAG object, define a unique DAG Id, define a start date, define a scheduled interval and define a catchup parameter.
Start Date: The "start_date" parameter in Airflow represents the date and time when a DAG should begin its execution. It determines the earliest time at which Airflow starts scheduling and running tasks within the DAG.
Scheduled Interval: The "scheduled_interval" parameter defines the frequency at which a DAG's tasks are scheduled to run. It determines how often the DAG's execution is triggered, such as daily, hourly, or at a specific time.
Catchup Parameter: The "catchup" parameter, when set to True, allows Airflow to backfill or schedule runs for the DAG starting from the "start_date" for all the intervals up to the current time. If set to False, Airflow will only schedule tasks from the current time onwards, ignoring past intervals.
**Operators in Apache Airflow
**In Apache Airflow, operators are the building blocks of a workflow and represent individual tasks that perform specific actions. Each operator encapsulates a unit of work, such as running a script, executing a SQL query, transferring files, or interacting with cloud services. Apache Airflow provides various built-in operators and allows users to create custom operators, making it a flexible and extensible platform for defining and orchestrating complex data processing and data pipeline workflows.
In our case we use the "PythonOperator" which is a specific type of operator used to execute arbitrary Python functions as tasks within Airflow workflows. It allows you to define custom logic or computations using Python code as part of your data pipeline.
You can define a task by creating an operator that represents a specific unit of work within a Directed Acyclic Graph (DAG). The operator defines the task's behavior and functionality. Here's an example of how to define a task using the PythonOperator, which executes a Python function as a task:
In the above example, a task is created by providing the unique task id and the python callable. This python callable is the function which will be called when it is the turn for the particular task in the DAG to execute.
XCom
XCom (Cross-Communication) is a mechanism for exchanging data between tasks within a DAG. It allows tasks to pass information to downstream tasks by pushing and pulling data through XComs. This enables seamless communication and data sharing between different tasks in a workflow.
Task Dependency
Task dependency in Apache Airflow determines the order in which tasks within a Directed Acyclic Graph (DAG) are executed. Each task represents a specific unit of work, and dependencies define how tasks are related to each other in terms of execution order.
For example, let's say we have 3 tasks - task1,task2 and task3 and they have to be executed one after the another. That is, task2 should begin after the successful completion of task1 and task3 should begin after the successful completion of task2. Then in airflow terminology we specify it as
Code Organization
In Apache Airflow, the "dags" folder is a directory where you store Directed Acyclic Graph (DAG) definitions. DAGs represent workflows, and the scripts inside the "dags" folder define tasks and their dependencies, allowing Airflow to schedule and execute these workflows as specified by the DAG scheduler. Accordingly, you have the features module and data_transformation.py file in the dags folder.
The features module contains the voters.py file which contains the logic for Feature Engineering. Each feature is engineered in a separate function. The data_transformation.py file hosts the data transformation pipeline which will be identified by airflow to create the DAG. In addition to that we have the requirements.txt which contains the dependencies for running the DAG.
Connecting to Hopsworks Feature Store
Once the basic setup is done we connect to Hopswork’s API. To fetch the API we need to log in to Hopsworks. In Account Settings, we can create a new API key or use an existing one. This API key will be used by Hopsworks for authentication.
Figure 2: API key for connecting to Hopsworks workspace
**Triggering the DAG
**A DAG has been created with the name “data_transformation”. This DAG has 5 tasks and all the tasks here are python operators.
-> “get_raw_data_task”. This task takes in the voter stats link as configuration argument and returns the file path of the raw data, stored as a csv file.
-> “get_preprocessed_df_task”. This task gets the file path from get_raw_data_task and preprocesses the data. Finally it returns the filepath of the preprocessed data stored as a csv file.
-> “get_aggregated_df_task”. This task gets the file path from get_preprocessed_df_task and performs aggregation on the data. Finally it returns the file path of the aggregated data, stored as a csv file.
-> “update_columns_task”. This task gets the file path from get_aggregated_df_task and updates the column names. Finally it returns the file path of the data, stored as a csv file.
-> “push_to_fs_task“. This task gets the file path from update_columns_task and pushes the data to the Feature Store.
To trigger this DAG in airflow we have to run the following command
Creating a Feature Group
A feature group serves as a logical grouping of features, typically derived from the same data source. Through experience, it has been observed that features within a group share a common origin. This allows for efficient organization and management of feature-related information, facilitating better understanding and utilization of data within the Feature Store.
The following code can be used to create a feature group. It requires name, version, description, and primary key as parameters. If the feature group already exists you will get access to the existing feature group.
**Inserting data into the Feature Group
**Once the Feature group is created you can insert the data to the feature group with the code given below. The insert function accepts a Pandas data frame as a parameter to push data to the Feature group. The column names in the data frame must follow the prescribed naming convention. The progress of insertion can be monitored via the link provided by the Hopsworks API.
Exploring features from UI
From the Hopsworks UI you can explore feature group’s metadata information such as feature names, types, primary key, Statistics, Descriptions, etc. The provenance of the data, Expectations, Tags, and Alerts can be directly managed in the UI.
In Great Expectations, you have the ability to create expectation suites and link them to feature groups. When data is written to a feature group, the associated expectations are automatically evaluated. You can then establish a policy for the feature group to determine the appropriate action if any of the expectations fail.
Hopsworks supports alerts when pre-defined expectations fail in feature pipelines. Alerts can be sent to various endpoints like email or Slack, configurable in the Hopsworks UI, e.g., notifying missing input data during feature writes.
Conclusion
In conclusion, Apache Airflow proves to be a versatile and powerful tool for feature engineering in data processing pipelines. By leveraging Airflow's DAG-based workflow design, we efficiently build a feature pipeline encompassing feature binning and aggregations. The aggregated data is seamlessly stored in Hopsworks Feature Store, further enhancing the workflow by providing a centralized repository for high-quality, reusable features.
The combination of Apache Airflow and Hopsworks Feature Store enables us to streamline the feature engineering process, ensuring consistency and efficiency across data analysis and modeling workflows.