Feature Engineering for Categorical Features with Pandas
Explore the power of feature engineering for categorical features using Pandas. Learn essential techniques for handling categorical variables, and creating new features.

Introduction
Welcome to the world of advanced data management and feature engineering with Hopsworks Feature Store! In today's data-driven era, organizations face the challenge of efficiently managing and leveraging vast amounts of data to extract meaningful insights. Hopsworks Feature Store offers a powerful solution by providing a centralized hub for storing, managing, and serving feature data. With its seamless integration with popular tools and frameworks, Hopsworks empowers data scientists and engineers to easily access, share, and transform features, enabling them to build robust and accurate machine-learning models.
In this blog, we will deep dive into the types of Feature Engineering of categorical variables with Pandas and aggregation strategies. Additionally, we will also discuss the step-by-step process of creating a feature pipeline and inserting the aggregated data into the feature group.
Categorical Features
Features are measurable properties or data characteristics used as input variables in machine learning models. They capture relevant information and patterns from the data to make predictions or perform analysis. Features can be broadly categorized into two types: numerical features and categorical features. Feature engineering is a process of extracting features from raw data and transforming them into suitable formats for machine learning models.
Numerical features represent continuous or discrete numerical values, such as age or income. Categorical features represent discrete values or categories, such as gender or color. Proper selection and engineering of features are crucial for model performance and accurate predictions.
Feature Engineering for Categorical Variables
There are several types of categorical feature engineering techniques that can be applied to transform categorical variables into numerical or binary representations. Here are some commonly used techniques:
- One-Hot Encoding: One-hot encoding is a widely used technique where each category in a categorical variable is transformed into a binary feature. Each feature represents whether a particular category is present (1) or absent (0) in the original variable. This technique expands the feature space but allows algorithms to effectively utilize categorical information.
- Label Encoding: Label encoding assigns a unique numerical label to each category in a categorical variable. It replaces the original categories with their corresponding numerical labels.
- Ordinal Encoding: Ordinal encoding is similar to label encoding but preserves the order of the categories. It assigns numerical labels to categories based on their order or some predefined mapping. Ordinal encoding is suitable when the categories have a natural order, such as "low," "medium," and "high."
- Frequency Encoding: Frequency encoding replaces categories with their corresponding frequencies in the dataset. It assigns a numerical value to each category based on how frequently it appears. This technique captures the distribution of categories and can be useful when the frequency of occurrence is informative.
- Target Encoding: Target encoding incorporates the target variable's information into the categorical encoding process. Each category is encoded with the statistical summary (e.g., mean, median, etc.) of the target variable for that category. Target encoding can be effective in capturing the relationship between categorical variables and the target but may be prone to overfitting.
These techniques offer different ways to encode categorical variables, each with its strengths and considerations. The choice of which technique to apply depends on the specific characteristics of the dataset, the nature of the categorical variables, and the requirements of the machine learning algorithm or task at hand.
Understanding the data
In this article, we are using the North Carolina Voter Stats dataset. This dataset contains voter information based on election dates. Which means there will be a file for each election date. Each file contains the following features.
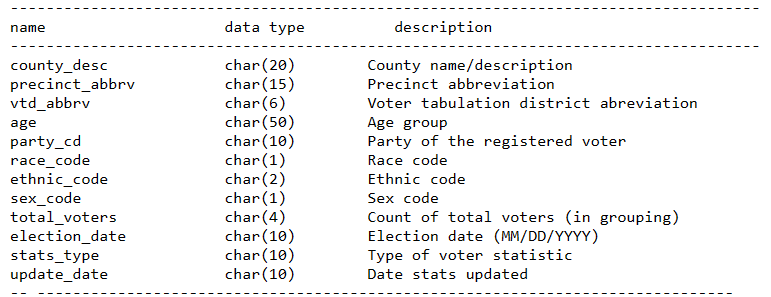
Figure 1. Features with data types and description
For the sake of brevity in the demonstration, the following features are used: party_cd, county_desc, race_code, age, sex_code, ethnic_code and total_voters.
- party_cd: This feature denotes the party of the registered voter. The available parties are DEM (DEMOCRATIC), LIB (LIBERTARIAN), REP (REPUBLICAN), and UNA (UNAFFILIATED). They are categorized into REP, DEM, and Others.
- county_desc: This feature denotes the County name of the registered voter. There are 100 counties in the state of North Carolina. Since this feature is a categorical variable we perform label encoding. The code for each county can be found here.
- race_code: This feature denotes the Race code of the registered voter. The available race codes are A (ASIAN), B (BLACK or AFRICAN AMERICAN), I (INDIAN AMERICAN or ALASKA NATIVE), M (TWO or MORE RACES), O (OTHER), U (UNDESIGNATED), W (WHITE). These features are label encoded into W, B, A, I, and Others.
- age: This feature denotes the age group of the registered voter. The available age groups are: Age < 18 Or Invalid Birth Dates, Age 18 - 25, Age 26 - 40, Age 41 - 65, Age Over 66. They are encoded with the same name.
- sex_code: This feature denotes the sex code of the registered voter. The available sex codes are F (FEMALE), M (MALE), and U (UNDESIGNATED). They are label encoded into F, M, and Others.
- ethnic_code: This feature denotes the ethnic code of the registered voter. The available ethnic codes are HL (HISPANIC or LATINO), NL (NOT HISPANIC or NOT LATINO), and UN (UNDESIGNATED). They are encoded into HL, NL, and Others.
- total_voters: This feature denotes the count of total voters. This is a numerical variable.
Code Organization
The repository is organized as a Python package. Both the feature engineering code and the feature pipeline code are hosted in the same repository. The features module contains the voters.py file which contains the logic for Feature Engineering. Each feature is engineered in a separate function.
Installation and setting up of the environment
The First step is the installation and setup of a working environment. The driver code is in the operational_feature_pipeline.ipynb file which is present in the root of the repository. This code contains the logic for downloading the source code from the repository and placing it in the working directory.
Connecting to Hopsworks Feature Store
Once the basic setup is done we connect to Hopswork’s API. To fetch the API we need to log in to Hopsworks. In Account Settings, we can create a new API key or use an existing one.
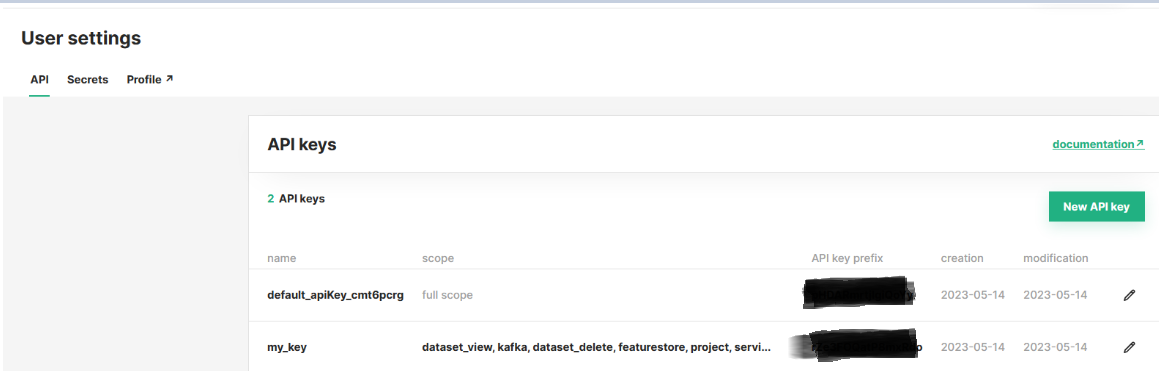
Figure 2. API key for connecting to Hopsworks workspace
By running the below commands a prompt will open up, where you need to provide the API key. On successful completion, you will be connected to the Hopsworks workspace.
Running the driver code
The main function of your feature pipeline requires the URL that hosts your data. When you execute the main function, the following steps will occur:
- Downloading data from the provided URL.
- Performing feature selection to obtain the required features.
- Performing feature engineering to obtain the feature dataframe.
- Performing aggregation to obtain the final dataframe.
Creating a Feature Group
A feature group serves as a logical grouping of features, typically derived from the same data source. Through experience, it has been observed that features within a group share a common origin. By associating metadata with features, the Feature Group defines how the Feature Store interprets, combines, and reproduces training datasets based on these features. This allows for efficient organization and management of feature-related information, facilitating better understanding and utilization of data within the Feature Store.
It is recommended that the Feature values in Feature Groups are human-readable so that it is possible to perform Exploratory Data Analysis (EDA). For example using "Male," "Female," and "Others" is recommended as they are more interpretable, compared to "M," "F," and "O." In Hopsworks, you can store features in Feature Groups and retrieve them using feature views. If your model requires transforming to numerical representation during training and inferencing, you can define transformation functions when you read data using Feature Views.
The following code can be used to create a feature group. It requires name, version, description, and primary key as parameters. If the feature group already exists you will get access to the existing feature group.
Inserting data into the Feature Group
Once the Feature group is created you can insert the data to the feature group with the code given below. The insert function accepts a Pandas data frame as a parameter to push data to the Feature group. The column names in the data frame must follow the prescribed naming convention. The progress of insertion can be monitored via the link provided by the Hopsworks API.
Exploring features from UI
From Hopsworks UI you can explore feature group’s metadata information such as feature names, types, primary key, Statistics, Descriptions, etc. The provenance of the data, Expectations, Tags, and Alerts can be directly managed in the UI.
In Great Expectations, you have the ability to create expectation suites and link them to feature groups. When data is written to a feature group, the associated expectations are automatically evaluated. You can then establish a policy for the feature group to determine the appropriate action if any of the expectations fail.
Hopsworks supports alerts when pre-defined expectations fail in feature pipelines. Alerts can be sent to various endpoints like email or Slack, configurable in the Hopsworks UI, e.g., notifying missing input data during feature writes.
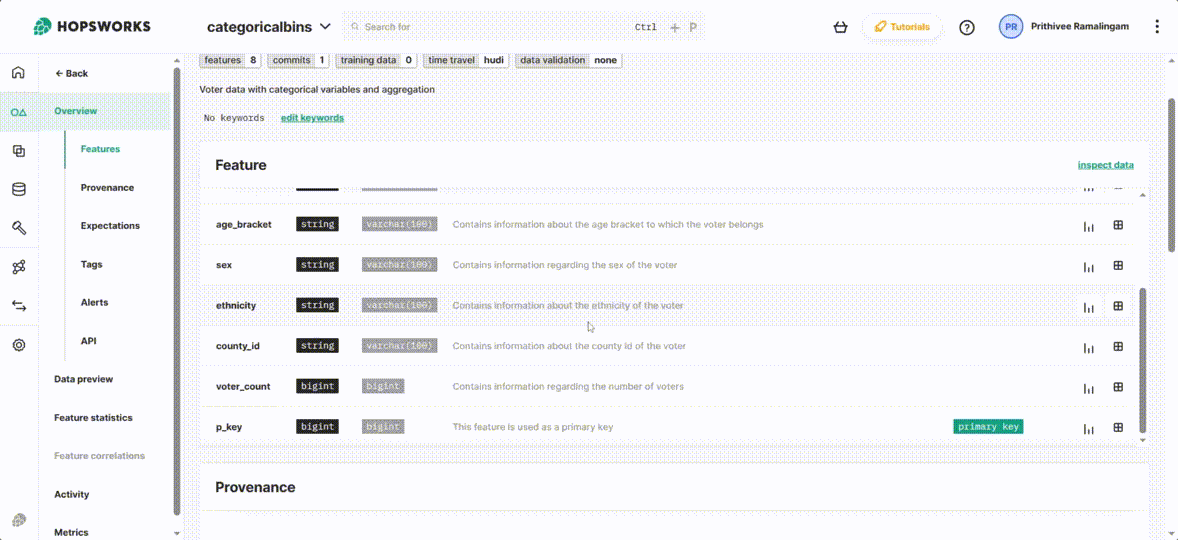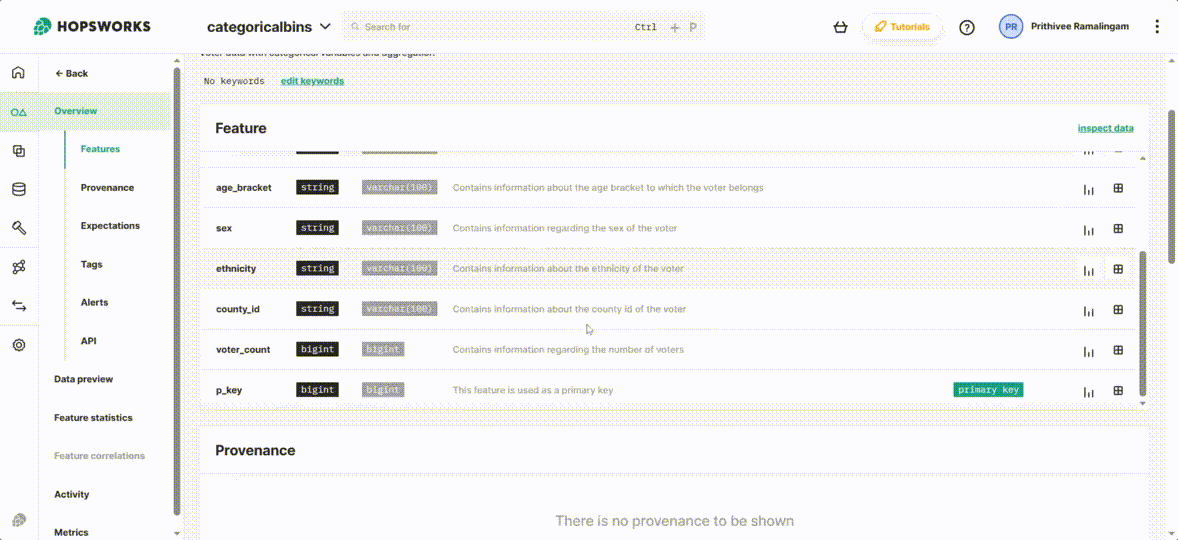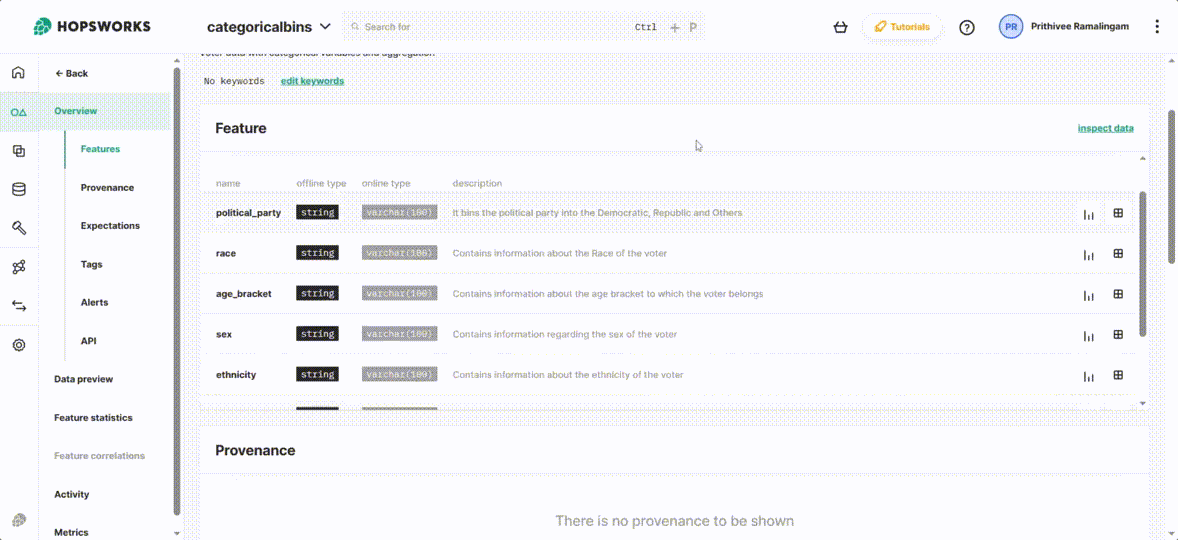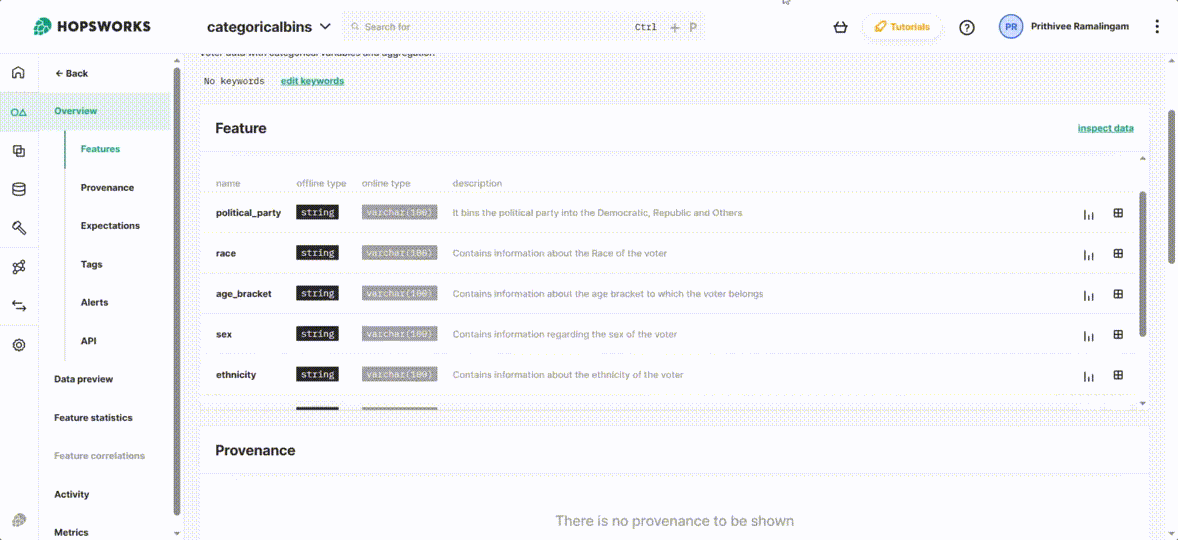
Figure 3. Features on the Hopsworks UI
Conclusion
In conclusion, this blog has provided a comprehensive exploration of categorical variable feature engineering using Pandas. We have covered the step-by-step process of creating a feature pipeline and demonstrated how to insert the aggregated data into a feature group. By mastering these techniques and understanding the importance of feature engineering, you can enhance the quality and effectiveness of your data analysis and machine learning projects. With the knowledge gained from this blog, you are well-equipped to leverage Hopsworks to unlock valuable insights from your categorical variables and drive better decision-making processes.