ML Engineer Guide: Feature Store vs Data Warehouse
The feature store is a data warehouse of features for machine learning (ML). Architecturally, it differs from the traditional data warehouse in that it is a dual-database.

Features Store: Data Warehouse Déjà Vu
Data warehouses democratized access to Enterprise data by centralizing data in a single platform and then empowering business analysts with visual tools, such as Tableau and Power BI. No longer did they need to know what data resides where and how to query that data in that platform. They could derive historical insights into the business using BI tools.
Data scientists, in contrast, build predictive models to derive business insights. The feature store is the data warehouse for Data Science - it is a central vault for storing documented, curated, and access-controlled features that can be used across many different models. The feature store ingests data from the Enterprise’s many different sources after transforming, aggregating, and validating the data.
Feature pipelines need to be written to ensure that data reliably flows from existing sources and is available in a format ready to be consumed by ML training pipelines and models.
Most Data Scientists currently do not have a feature store. They spend most of their time looking for, cleaning, and featurizing data. Hence, the (very real) cliché that 80% of data science is data wrangling. Data Scientists without a feature store work in an era akin to how business analysts worked before the advent of data warehouses, with low individual and organizational productivity.
The Data Warehouse is an input to the Feature Store
Both platforms are a central store of curated data used to generate insights into the data. Both platforms have pipelines (ETL and feature pipelines, respectively) to ingest data from one or more disparate sources (operational databases, data lakes, etc).
Both benefit from metadata catalogs to organize data sets and access control to share data with only authorized actors.
Both platforms can be designed to scale-out on commodity hardware and store large volumes of data, although typically a data warehouse stores only relevant to analysis (modern data lakehouses are designed to store large volumes of data more cost efficiently).
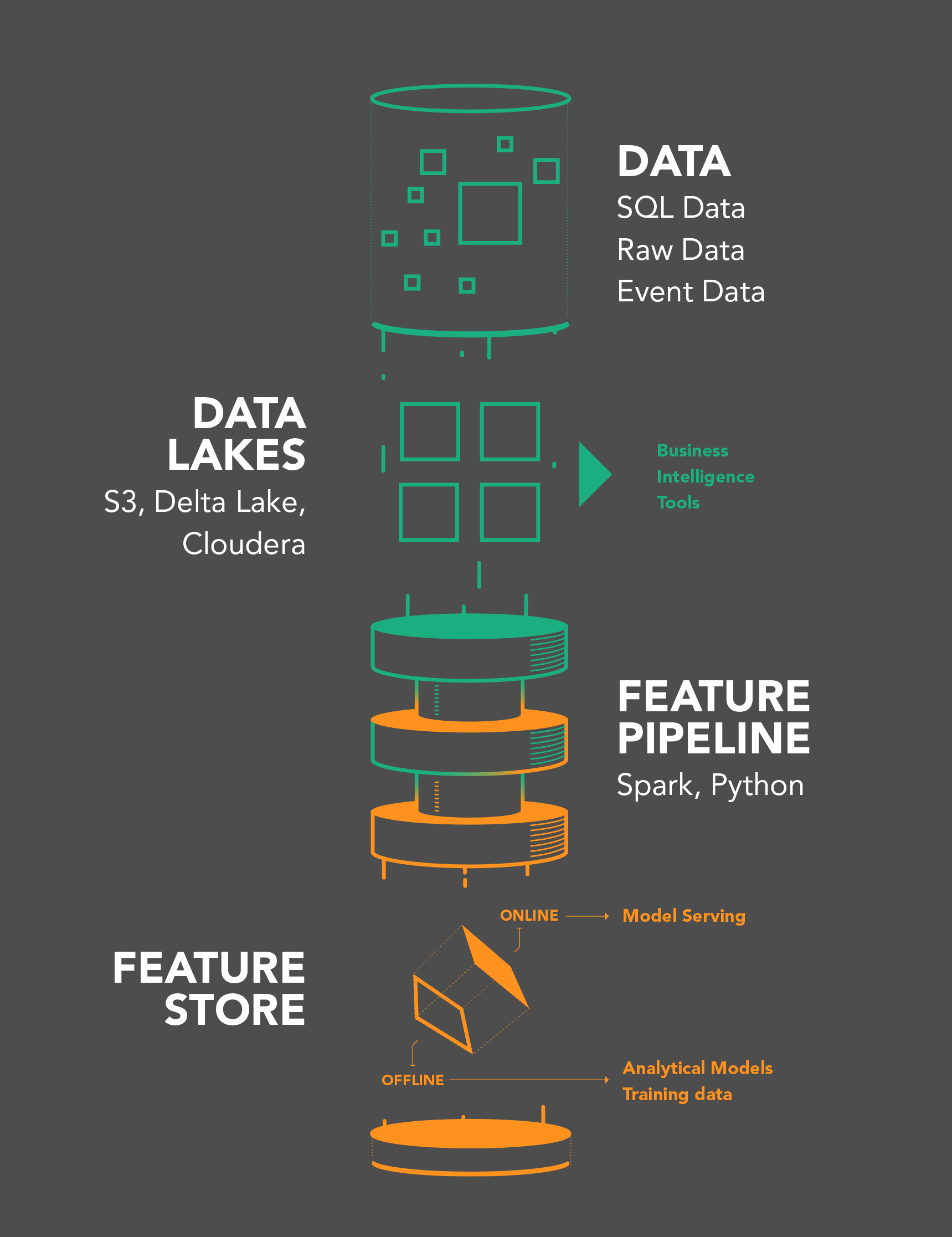
Feature Store as a Dual Database
The main architectural difference between a data warehouse and a feature store is that the data warehouse is typically a single columnar database, while the feature store is typically implemented as two databases:
- an offline feature store for serving large batches of features to (1) create train/test datasets and (2) batch applications scoring models using those batches of features, and
- an online feature store for serving a single row of features (a feature vector) to be used as input features for an online model for an individual prediction.
The offline feature store is typically required to efficiently serve and store large amounts of feature data, while the online feature store is required to return feature vectors in very low latency (e.g., < 10ms). Examples of databases used for the offline feature store are Apache Hive and BigQuery and examples of online feature stores include MySQL Cluster, Redis, and DynamoDB.
Note that if you want to reuse features in different train/test datasets for different models, your database or application will need to join features together. This is true for both the offline and online feature stores. If your feature store does not support joining features, that is, you do not reuse features across different models, you (or some system) will need to create a new ingestion pipeline for every new model you support in production.
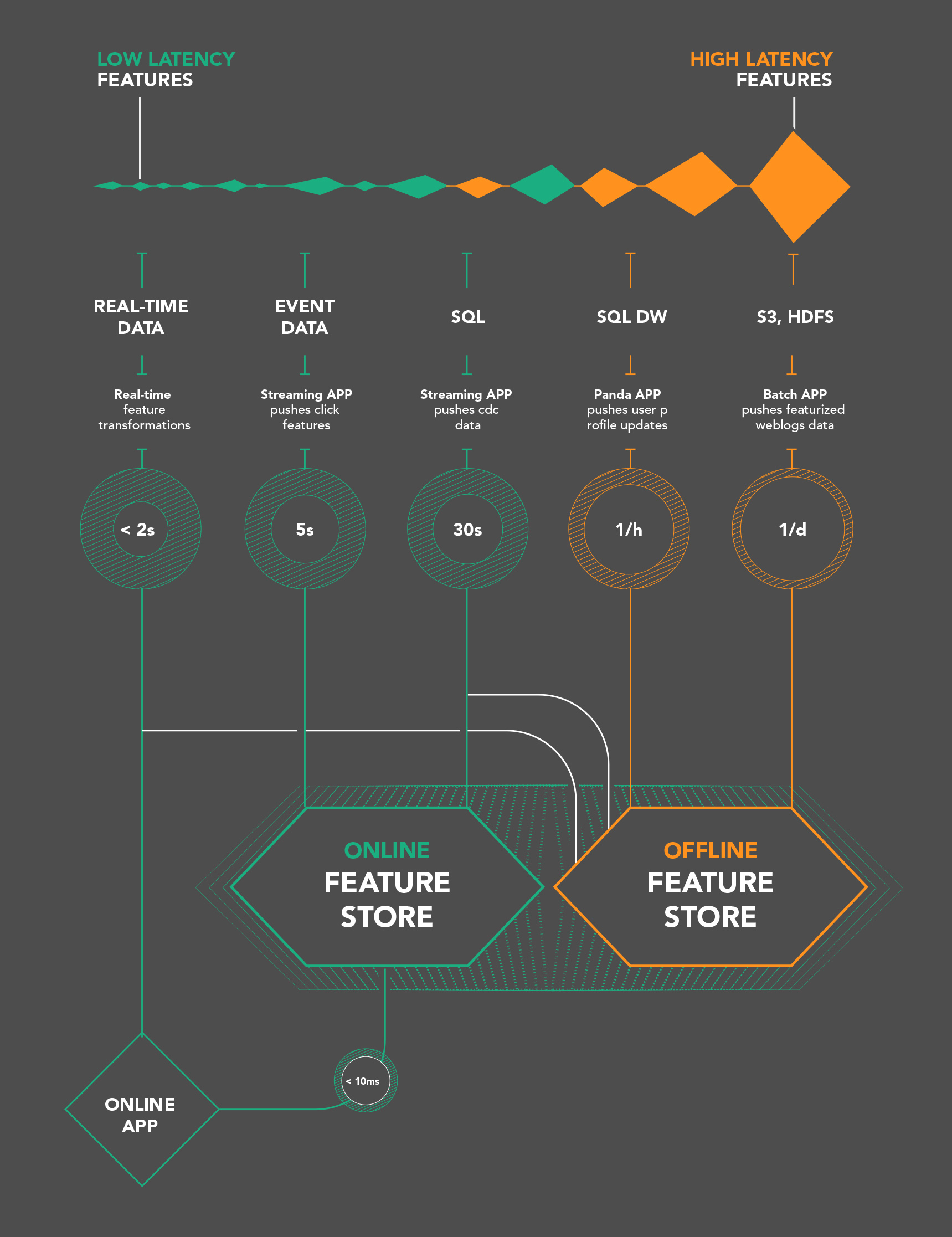
Detailed Comparison
In the table below, we see an overview of the main architectural differences between feature stores and data warehouses. Data warehouses are used primarily by business analysts for interactive querying and for generating historical reports/dashboards on the business. Feature stores are used by both data scientists and by the online/batch applications, and they are fed data by feature pipelines, typically written in Python or Scala/Java.
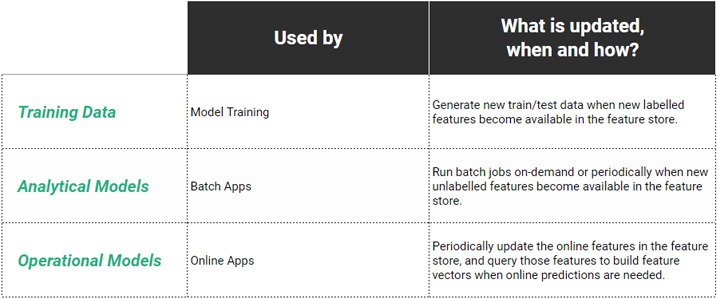
Data scientists typically use Python programs to create train/test datasets by joining existing features in the feature store together and materializing the train/test datasets in a file format best suited to the framework they are going to train their model in (e.g., TFRecord for TensorFlow, NPY for PyTorch). Data warehouses and SQL currently lack this capability to create train/test datasets in ML file formats.
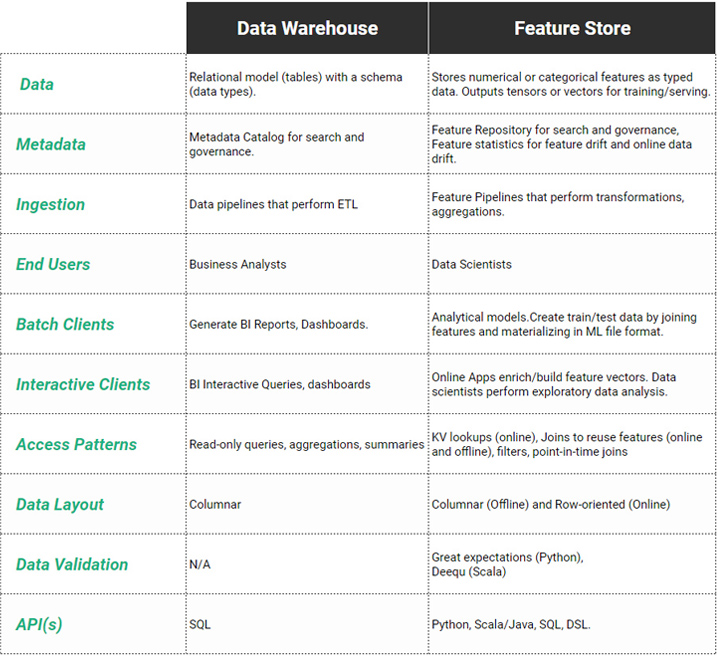
Feature Data should be Validated before Ingestion
The table also shows the differences in the types of data stored, as well as how the data is stored, validated, and queried. A data warehouse stores data in tables along with schemas for describing the type of data and constraints for columns. Similarly, the feature store stores typed data (typically in tables), but as features are typically stored as ready-to-consume numerical values or vectors (embeddings) or tensors, there is less need for a richer set of column types compared to a data warehouse. Foreign key constraints are typically not supported in feature stores, due to the difficulty in enforcing such constraints between online and offline stores.
As model training is very sensitive to bad data (null values, outliers cause numerical instability, missing values), feature data should be validated before ingestion. Data validation frameworks, such as Great Expectations and Deequ, have appeared to help implement feature pipelines that apply predicates (data validation rules) on all the features ingested into the feature store, ensuring high data quality in the feature store.
Domain specific languages (DSL) are sometimes used to define the feature transformations, aggregations, and data validation rules in feature pipelines, but general purpose languages (Python, Scala) are commonly used when non-trivial feature engineering is required.
Using the feature store to create train/test data
Data scientists are one of the main users of the feature store. They use a feature repository to perform exploratory data analysis (EDA) - searching/browsing for available features and inspecting feature values/schemas/statistics. Data Scientists mainly use Python to select features to create train/test datasets. This typically involves joining features together to create a train/test dataset in their file format of choice (.tfrecord, .csv, .npy, .petastorm, etc). Sometimes feature stores support a DSL (domain specific language) to create train/test datasets or other languages such as Scala/Java.
Online feature store
Online applications use the online feature store to retrieve feature values with low latency to build feature vectors that are sent to models for predictions. In contrast to higher latency data warehouses, feature stores may be required to return feature vectors in single millisecond latency - only really achievable in row-oriented or key-value stores.
The typical access pattern for retrieving features is a key-value lookup, but if features are to be reused in the online feature store, then joins are again required (either in the database or in the application). In some databases (such as MySQL Cluster), a small number of joins can be performed at very low latency.
Feature statistics to monitor for feature drift and data drift
Descriptive statistics (e.g., mean, standard deviation) for features are also useful when identifying data drift in online models. Your monitoring infrastructure can calculate statistics on live prediction traffic, and compare those statistics with the values in the feature store to identify data drift for the live traffic, potentially required retraining of the model.
Time-Travel
Temporal databases support time-travel: the ability to query data as it was at a given point-in-time or data changes in a given time-interval. The “AS OF SYSTEM TIME” syntax was introduced to SQL 2011 to standardize point-in-time queries, while the “VERSIONS BETWEEN SYSTEM TIME ... AND ... “ syntax was introduced to identify the versioned changes to data in a time interval. Time-travel is supported in some data warehouses, but does not have universal support across all vendors.
For a feature store time-travel has several important uses: when creating train/test data (e.g., training data is data from the years 2010-2018, while test data is data from the range 2019-2020). Time-travel is also useful to make changes to a dataset (e.g., rollback a bad commit of data to the dataset) or to compare metadata (statistics) for features and how they change over time. We rarely require time-travel for features used in serving. Time-travel is also important when performing point-in-time joins, where we ensure that there is no data leakage from the future when we create train/test datasets from historical data.
Feature Pipelines
Data warehouses typically have timed triggers for running ETL jobs (or data pipelines) to ingest the latest data from operational databases, message queues, and data lakes. Similarly, feature pipelines can timed triggers to transform and aggregate the latest data from different sources before storing it in both the online and offline feature store for scoring by online and offline applications. However, additional pipelines can also feed features to the feature store.
Predictions made by models can be stored in the feature store along with the outcomes for those predictions. There can be long lags of even days or months or years before outcomes become available - e.g., a prediction on whether a loan will be repaid or not), but as they arrive new training data becomes available that can be used to trigger re-training of models.
Conclusion
Data warehouses can be used to store pre-computed features, but they do not provide much more functionality beyond that for ML pipelines. When Data Scientists need to create train/test data using Python or when online features (for serving features to online models) are needed at low latency, you need a feature store. Similarly, if you want to detect feature drift or data drift, you need support for computing feature statistics and identifying drift.