AI/ML needs a Key-Value store, and Redis is not up to it
Seeing how Redis is a popular open-source feature store with features significantly similar to RonDB, we compared the innards of RonDB’s multithreading architecture to the commercial Redis products.

Online feature stores are the data layer for operational machine learning models - the models that make online shopping recommendations for you and help identify financial fraud. When you train a machine learning model, you feed it with high signal-to-noise data called features. When the model is used in operation, it needs the same types of features that it was trained on (e.g., how many times you used your credit card during the previous week), but the online feature store should have low latency to keep the end-to-end latency of using a model low. Using a model requires both retrieving the features from the online feature store and then sending them to the model for prediction.
Hopsworks has been using NDB Cluster as our online feature store from its first release. It has the unique combination of low latency, high availability, high throughput, and scalable storage that we call LATS. However, we knew we could make it even better as an online feature store in the cloud, so we asked one of the world’s leading database developers to do it - the person who invented NDB, Mikael Ronström. Together we have made RonDB, a key-value store with SQL capabilities, that is the world’s most advanced and performant online feature store. Although NDB Cluster is open-source, its adoption has been hampered by an undeserved reputation of being challenging to configure and operate. With RonDB, we overcome this limitation by providing it as a managed service in the cloud on AWS and Azure.
Requirements for an Online Feature Store
Figure 1. LATS Framework
The main requirements from a database used as an online feature store are: low latency, high throughput for mixed read/write operations, high availability and the ability to store large data sets (larger than fit on a single host). We unified these properties in a single muscular term LATS:
LATS: low Latency, high Availability, high Throughput, scalable Storage.
RonDB is not without competition as the premier choice as an online feature store. To quote Khan and Hassan from DoorDash, it should be a low latency database:
“latency on feature stores is a part of model serving, and model serving latencies tend to be in the low milliseconds range. Thus, read latency has to be proportionately lower.”
To that end, Redis fits this requirement as it is an in-memory key-value store (without SQL capabilities). Redis is open source (BSD Licence), and it enjoys popularity as an online feature store. Doordash even invested significant resources in increasing Redis’ storage capacity as an online feature store, by adding custom serialization and compression schemes. Significantly, similar to RonDB, it provides sub-millisecond latency for single key-value store operations. There are other databases that have been proposed as online feature stores, but they were not considered in this post as they have significantly higher latency (over one order-of-magnitude!), such as DynamoDB, BigTable, and SpliceMachine.
As such, we thought it would be informative to compare the performance of RonDB and Redis as an online feature store. The comparison was between Redis open-source and RonDB open-source (the commercial version of Redis does not allow any benchmarks). In addition to our benchmark, we compare the innards of RonDB’s multithreading architecture to the commercial Redis products (since our benchmark identifies CPU scalability bottlenecks in Redis that commercial products claim to overcome).
Benchmark: RonDB vs Redis
In this simple benchmark, I wanted to compare apples with apples, so I compared open-source RonDB to the open-source version of Redis, since the commercial versions disallow reporting any benchmarks. In the benchmark, I deliberately hobbled the performance of RonDB by configuring it with only a single database thread, as Redis is “a single-threaded server from the POV of command execution”. I then proceed to describe the historical evolution of RonDB’s multithreaded architecture, consisting of three different generations, and how open-source Redis is still at the first generation, while commercial Redis products are now at generation two.
Firstly, for our single-threaded database benchmark, we performed our experiments on a 32-core Lenovo P620 workstation with 64 GB of RAM. We performed key-value lookups. Our experiments show that a single-threaded RonDB instance reached around 1.1M reads per second, while Redis reached more than 800k reads per second - both with a mean latency of around 25 microseconds. The throughput benchmark performed batch reads with 50 reads per batch and had 16 threads issuing batch requests in parallel. Batching reads/writes improves throughput at the cost of increased latency.
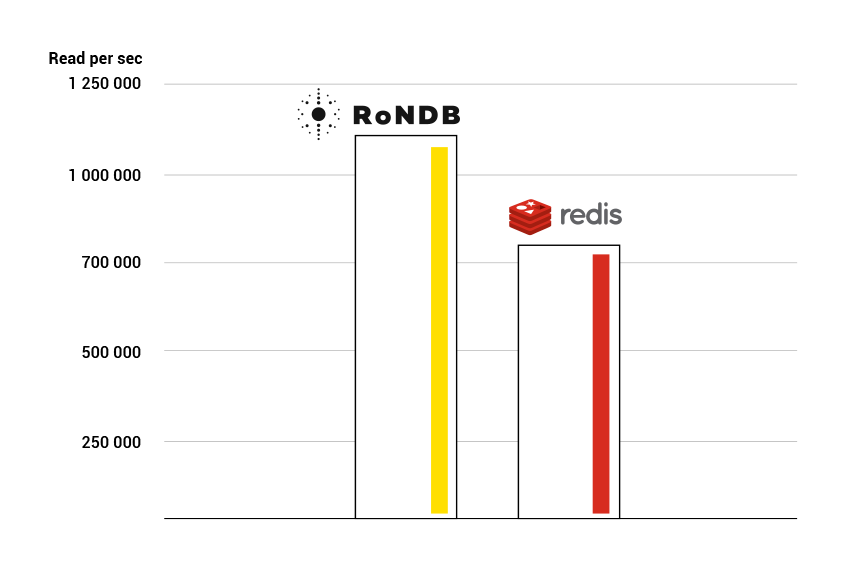
Figure 2. RonDB vs Redis
On the same 32-core server, both RonDB and Redis reached around 600k writes per second when performing SET for Redis and INSERT, UPDATE or DELETE operations for RonDB. For high availability, both of those tests were done with a setup using two replicas in both RonDB and in Redis.
Low latency
We expected that the read latency and throughput of RonDB and Redis would be similar since both require two network jumps to read data. In case of updates (and writes/deletes), Redis should have lower latency since an update is only performed on the main replica before returning. That is, Redis only supports asynchronous replication from the main replica to a backup replica, which can result in data loss on failure of the main node. In contrast, RonDB performs an update using a synchronous replication protocol that requires 6 messages (a non-blocking version of two-phase commit). Thus, the expected latency is 3 times higher for RonDB for writes.
High Throughput
A comparison of latency and throughput shows that RonDB already has a slight advantage in a single-threaded architecture, but with its third-generation multithreaded architecture, described below, RonDB has an even bigger performance advantage compared to Redis commercial or open-source. RonDB can be scaled up by adding more CPUs and memory or scaled out, by automatically sharding the database. As early as 2013, we developed a benchmark with NDB Cluster (RonDB’s predecessor) that showed how NDB could handle 200M Reads per second in a large cluster of 30 data nodes with 28 cores each.
High Availability
The story of high availability is different. A write in Redis is only written to one replica. The replication to other replicas is then done asynchronously, thus consistency can be seriously affected by failures and data can be lost. An online feature store must accept writes that change the online features constantly in parallel with all the batched key reads. Thus handling node failures in an online feature store must be very smooth.
Given that an online feature store may need to scale to millions of writes per second as part of a normal operation, this means that a failed node can cause millions of writes to be lost, affecting the correctness and quality of any models that it is feeding with data. RonDB has transactional capabilities that ensure that transactions can be retried in the event of such partial failures. Thus, as long as the database cluster is not fully down, no transactions will be lost.
In many cases the data comes from external data sources into the online Feature Store, so a replay of the data is possible, but an inconsistent state of the database can easily lead to extra unavailability in failure situations. Since an online feature store is often used in mission-critical services, this is clearly not desirable.
RonDB updates all replicas synchronously as part of writes. Thus, if a node running the transaction coordinator or a participant fails, the cluster will automatically fail over to the surviving nodes, a new transaction coordinator will be elected (non-blocking), and no committed transactions will be lost. This is a key feature of RonDB and has been tested in the most demanding applications for more than 15 years and tested thousands of times on a daily basis.
Additionally it can be mentioned that in a highly available setup, in a cloud environment RonDB can read any replica and still see the latest changes whereas Redis will have to read the main replica to get a consistent view of the data and this will, in this case, require communicating across availability zones which can easily add milliseconds to latency for reads. RonDB will automatically setup the cluster such that applications using the APIs will read replicas that are located in the same availability zone. Thus in those setups RonDB will always be able to read the latest version of the data and still deliver data at the lowest possible latency. Redis setups will have to choose between delivering consistent data with higher latency or inconsistent data with low latency in this setup.
Scalable Storage
Redis only supports in-memory data - this means that Redis will not be able to support online Feature Stores that store lots of data. In contrast, RonDB can store data both in-memory and on-disk, and with support for up to 144 database nodes in a cluster, it can scale to clusters of up to 1PB in size.
Analysis: Three Generations of Multithread Architectures
For our single-threaded benchmark, we did not expect there to be, nor were there, any major differences in throughput or latency for either read or write operations. The purpose of the benchmark was to show that both databases are similar in how efficiently they use a single CPU. RonDB and Redis are both in-memory databases, but the implementation details of their multithreaded architectures matters for scalability (how efficiently they handle increased resources), as we will see.
Firstly, “Redis is not designed to benefit from multiple CPU cores. People are supposed to launch several Redis instances to scale out on several cores if needed.” For our use-case of online feature stores, it is decidedly non-trivial to partition a feature store across multiple redis instances. Therefore, commercial vendors encourage users to pay for their distributions that introduce a new multithreaded architecture to Redis. We now chronicle the three different generations of threading architectures underlying RonDB, from its NDB roots, and how they compare to Redis’ journey to date.
Open-source Redis has practically the same thread architecture implemented as in the first version of NDB Cluster from the 1990s, when NDB was purely an in-memory database. The commercial Redis distributions have sinced developed multithreaded architectures very similar to the second thread architecture used by later versions of NDB cluster. However, RonDB has evolved into a third version of the NDB cluster thread architecture. Let’s dive into the details of these 3 generations of threading architectures.
The first generation thread architecture is extremely simple - everything is implemented in one thread. This means that this thread handles receive on the socket, handling transactions, handling the database operation, and finally sending the response. This works better with fast CPUs with large caches - more Intel, less AMD. Still, handling all of this in one thread is efficient and my experiments on a 32-core Lenovo P620 workstation, we can see that RonDB reached 1.1M reads per second and Redis a bit more than 800k reads per second in a single thread with a latency of around 25 microseconds. This test used batch reads with 50 reads per batch and had 16 threads issuing batches in parallel. For INSERT, UPDATE or DELETE operations, both RonDB and Redis reached around 600k writes per second, with Redis performing SET operations (it does not have a SQL API). This benchmark was done with a setup using two replicas in both RonDB and in Redis.
Around 2008, the trend towards an increased number of CPUs per socket accelerated and today a modern cloud server can have more than 100 CPUs. With NDB, we decided it was necessary to redesign its multithreading architecture to scale with the available number of CPUs. This resulted in our second generation thread architecture, where we partitioned database tables and let each partition (shard) be managed by a separate thread. This takes care of the database operation. However, as NDB is a transactional distributed database, it was also necessary to design a multithreaded architecture for socket receive, socket send, and transaction handling. These are harder to scale-out on multi-core hardware.
Both NDB and the commercial solutions of Redis implement their multithreaded architecture using message passing. However, the commercial Redis solution uses Unix sockets for communication, whereas NDB (and RonDB) send messages through memory in a lock-free communication scheme. RonDB has dedicated threads to handle socket receive, socket send, and transaction handling. To further reduce latency, network send is adaptively integrated into transaction handling threads.
RonDB has, however, taken even more steps in its multithreaded architecture compared to commercial Redis solutions. RonDB now has a new third generation thread architecture that improves the scalability of the database - it is now possible for more than one thread to perform concurrent reads on a partition. RonDB will ensure that all these read-only threads that can read a partition all share the same L3 cache to avoid any scalability costs. This ensures that hotspots can be handled by multiple threads in RonDB. This architectural advancement decreases the need to partition the database into an increasingly larger number of partitions, and prevents problems such as over-provisioning due to hotspots in DynamoDB. The introduction of read-only threads is important for applications that also need to perform range scans on indexes that are not part of the partition key. It also enables the key-value store to handle secondary index scans and complex SQL queries in the background, while concurrently handling primary key operations (reads/writes for the online Feature Store).
Finally, the third generation thread architecture enables fine-grained elasticity; it is easy to stop a database node and bring it up again with a higher or lower number of CPUs, thus making it easy to increase database throughput or decrease its cost of operation. Hotspots can be mitigated with read-only threads without resorting to over-provisioning. RonDB also has coarse-grained elasticity, with the ability to add new database nodes without affecting its operation, known as online add node.
Conclusions
There are numerous advantages of RonDB compared to Redis; the higher availability and the ability to handle much larger data sets are the most obvious ones. Both are open-source, but Redis has the advantage of a reduced operational burden as it is not at its core a distributed system. However, in the recent era of managed databases in the cloud, operational overhead is no longer a deciding factor when choosing your database. With RonDB’s appearance as a managed database in the cloud, the operational advantages of Redis diminish, paving the way for RonDB to gain adoption as the highest performance online feature store in the cloud.